Rapport et propositions de recommandations sur le « Profilage et la Convention 108+ du Conseil de l’Europe »
Texte intégral
Figure

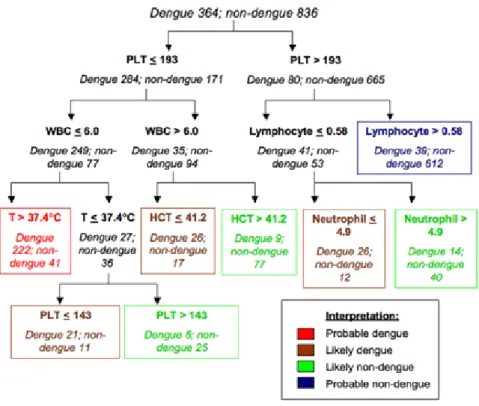

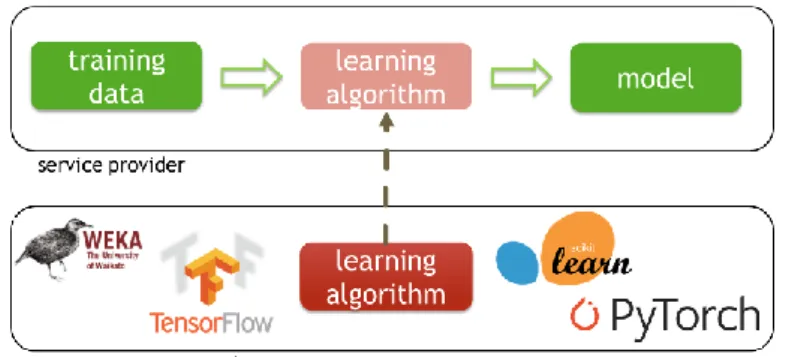




Outline
Documents relatifs
À la suite de la suppression de la réserve parlementaire, dont le montant s’établit à 3,3 millions d’euros sur la mission « Action extérieure de l’État » en 2017,
Lors du précédent quinquennat, les familles des classes moyennes ont été confrontées à la fois à des hausses d’impôt significatives (de l’ordre de 1,5 milliard d’euros au
SECONDE PARTIE LES PRINCIPALES ÉVOLUTIONS DE LA MISSION SANTÉ EN 2018 I. UNE MISE À CONTRIBUTION DES OPÉRATEURS SANITAIRES QUI SE POURSUIT ... UNE STABILISATION DES SUBVENTIONS
Votre rapporteur spécial considère que le bénéfice pour la société de cette dépense fiscale n’apparaît pas à la hauteur de son coût : à peine
Le 3° du IV du présent article précise que la compensation allouée à Mayotte au titre de la formation des assistants maternels, d’un montant de 9 334 euros, est
La mission « Défense » s’est vue ajouter en loi de finances pour 2014 un programme 402 « Excellence technologique des industries de défense », doté de 1,5 milliard
Au 10 octobre 2014, date limite, en application de l’article 49 de la LOLF, pour le retour des réponses du Gouvernement aux questionnaires budgétaires concernant le présent projet de
- dans le cadre de la nouvelle compétence du ministère des affaires étrangères et du développement international (MAEDI) en matière de tourisme, les moyens de
