3-D Geostatistical Seismic Inversion With Well Log Constraints
Texte intégral
Figure
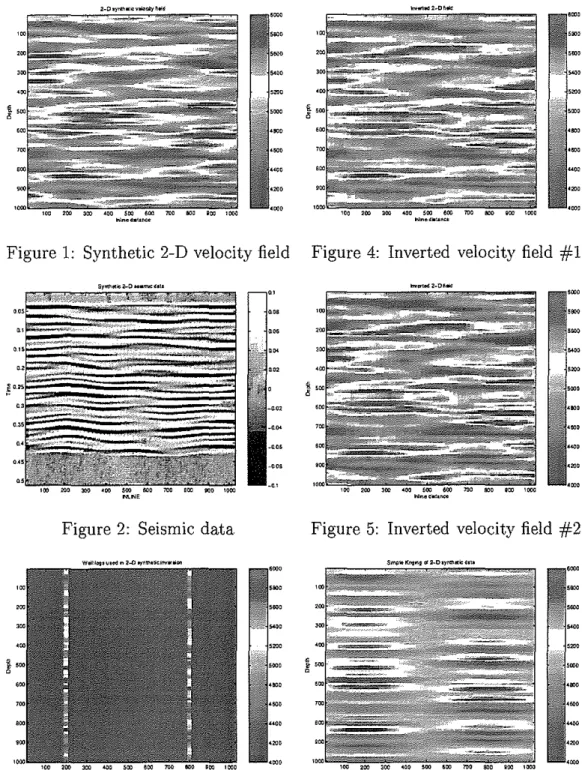
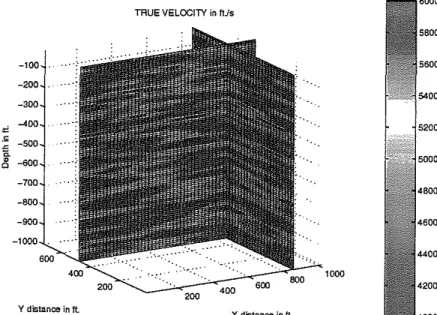
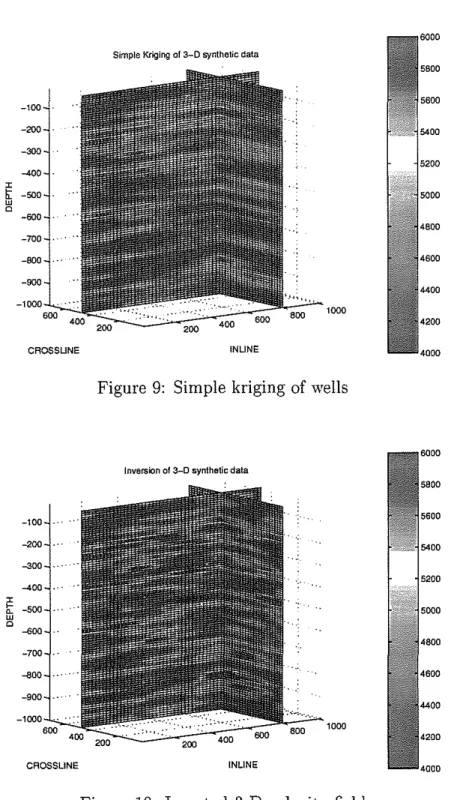
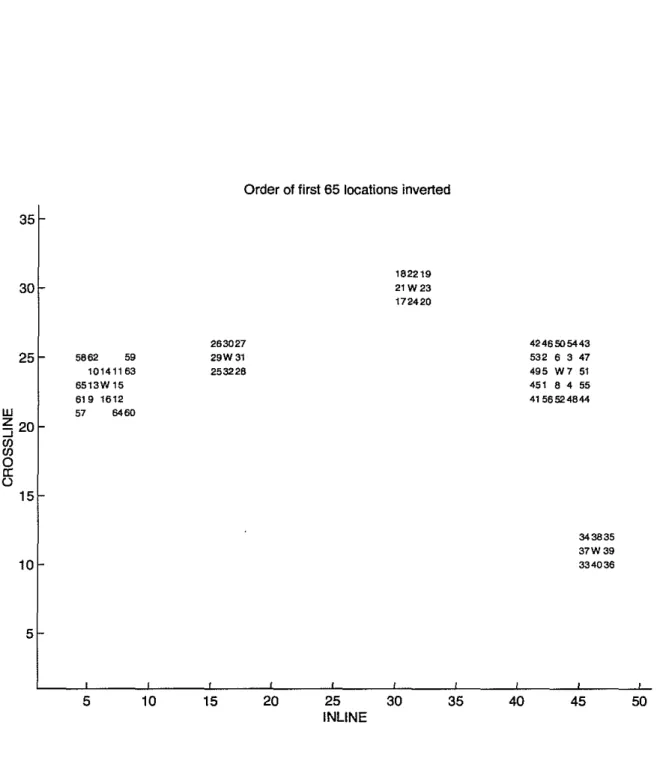

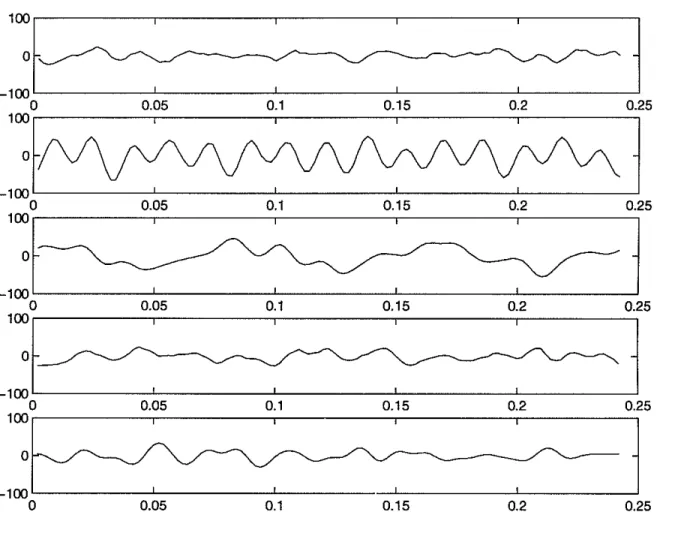
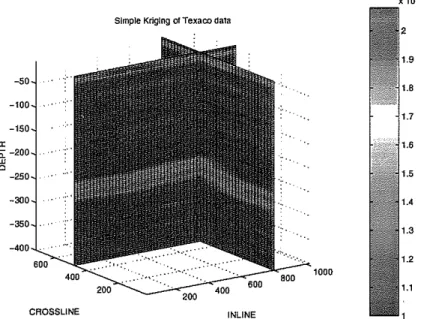
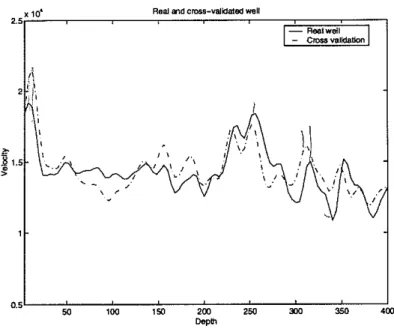
Documents relatifs
MONTE CARLO APPROXIMATIONS OF AMERICAN OPTIONS THAT PRESERVE MONOTONICITY AND CONVEXITY ´ PIERRE DEL MORAL, BRUNO REMILLARD, SYLVAIN RUBENTHALER Abstract.. It can be shown that when
Integrated inversion of production history data and 4D seismic data for reservoir model characterization leads to a nonlinear inverse problem that is usually cumbersome to solve :
Parmi les six types d'implications définis par Epstein, nous relevons ci-après les trois types qui selon nous sont directement liés à l'anxiété mathématique (Tableau 3,
Table 8 gives the time of the parallel algorithm for various numbers of slaves, with random slaves and various fixed playout times.. random evaluation when the fixed playout time
Nevertheless, high expression of Reg3β occurs in healthy pancreatic acinar cells surrounding the tumor, being this distant microenvironment the major source of Reg3β in
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
En fait les études déjà publiées montrent que l’appareil de Golgi peut être effectivement hérité via le RE quand les cellules sont traitées à la BFA!: cette drogue
analysis, a case study of the only successful implementation of this policy so far (in British Columbia), and analysis of the current political landscape in Massachusetts I
