A degree-optimal, ordered peer-to-peer overlay network
96
0
0
Texte intégral
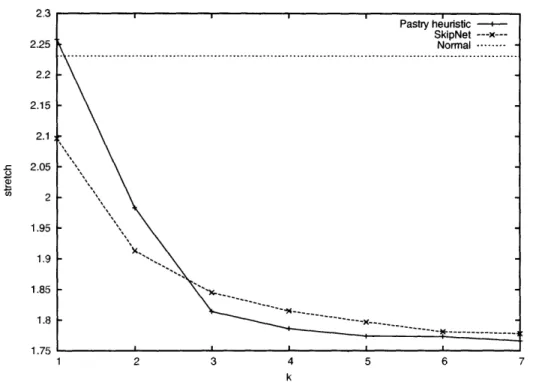
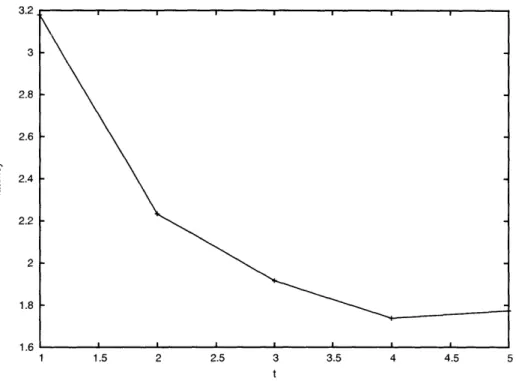
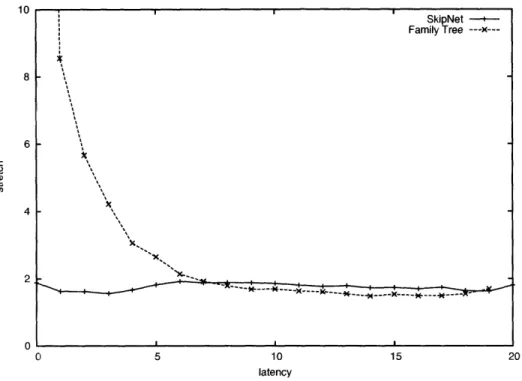
Figure
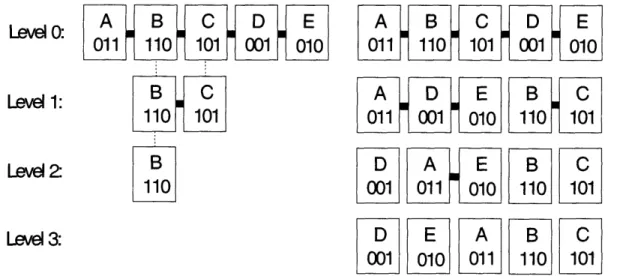

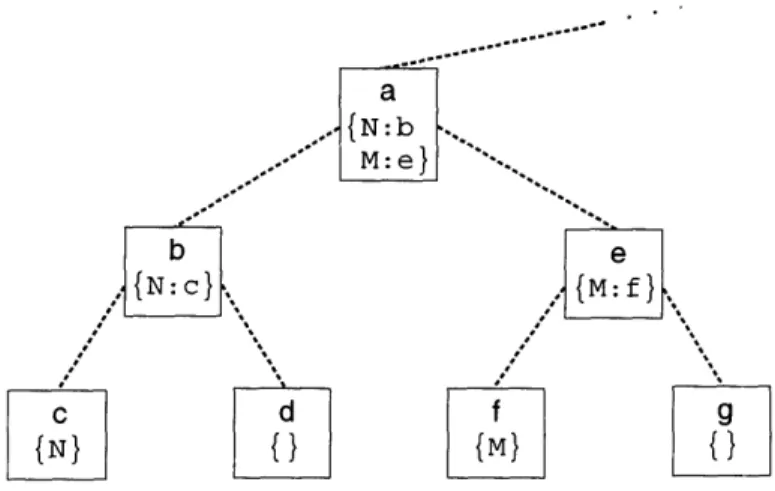
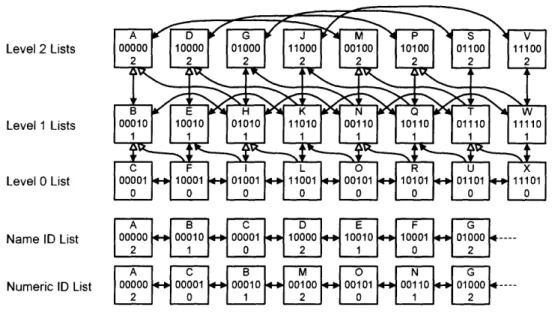
+7


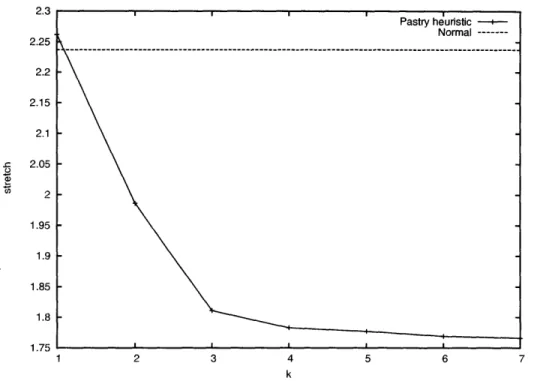
Documents relatifs