HAL Id: hal-02607952
https://hal.inrae.fr/hal-02607952
Submitted on 16 May 2020
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of
sci-entific research documents, whether they are
pub-lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destinée au dépôt et à la diffusion de documents
scientifiques de niveau recherche, publiés ou non,
émanant des établissements d’enseignement et de
recherche français ou étrangers, des laboratoires
publics ou privés.
A framework for remote sensing images processing using
deep learning techniques
Romain Cresson
To cite this version:
Romain Cresson. A framework for remote sensing images processing using deep learning techniques.
IEEE Geoscience and Remote Sensing Letters, IEEE - Institute of Electrical and Electronics Engineers,
2019, 16 (1), pp.25-29. �10.1109/LGRS.2018.2867949�. �hal-02607952�
2 Section II a detailed description of our method. We
then analyze the scalability of our approach with state of the art deep nets and Spot-7 and Sentinel-2 images (SectionIII). We finally discuss the main advantages and limits of our approach in SectionIV.
II. METHOD
A. Overview
The Orfeo ToolBox (OTB) is a library for RS image processing, built on top of an application development framework widely used in medical image processing, the Insight Toolkit (ITK) [24]. The machine learning framework of OTB is able to process large datasets at continental scale for land mapping [25] and benefits from High Performance Computing (HPC) architec-tures like clusters [26]. TensorFlow (TF) is a library for dataflow programming. It is a symbolic math li-brary, and is intensively used for machine learning ap-plications such as deep nets. It can also operate at large scale in HPC architectures like GPU. We aim to extend the existing rich machine learning frame-work of OTB with TF. Implementation of state of the art deep nets should be enabled with the minimum ef-fort, and the opportunity to apply them on RS images must be granted to non-developers, namely users. The existing user-oriented machine learning framework of OTB must be preserved. We also sought the imple-mentation of a component which can be used in a transparent way inside any OTB pipeline, to enable the combination of already implemented approaches with DL. In the following sections, we provide de-scription of the libraries processing frameworks (Sec-tionsII B andII C). Then we introduce our low-level OTB compliant component in Section II D and our new user-oriented OTB applications in Section II E. Finally, we analyze performances of our approach with state of the art RS deep nets in SectionIII.
B. Libraries paradigms
This section describes the processing logic of OTB and TF.
1. OTB workflow
A pipeline refers to a directed graph of process objects, that can be either sources (initiating the pipeline), filters (processing the data) or mappers (typically, write a result on disk). Sources and fil-ters can generate one or multiple data objects (e.g. image, vector). In the same way, filters and mappers consume one or multiple data objects. The architec-ture of OTB inherits from ITK and hides the com-plexity of internal mechanisms for pipeline execution, which involve several steps. Detailed description of
the pipeline mechanism can be found in [27] includ-ing figures and sequence diagram. The execution of a pipeline starts from a mapper, triggering its upstream filter(s). When a filter is triggered, information about mandatory input data (i.e. information about output data of upstream process object(s)) is also requested upstream. In this way, it is propagated back through the pipeline, from mappers to sources via filters. Once this request reach sources, data objects information are generated (e.g. image size, pixel spacing) then propagated downstream to mappers. It should be noted that filters can potentially modify these infor-mation, according to the process they implement (e.g. changing image size) which is the case with image re-sampling for instance. Finally, they reach the mapper, initiating the data processing. Information regarding the size of the image that will be produced, is then used by the mapper to choose a splitting strategy. The default splitting scheme is based on the system mem-ory specification. Other strategies can be chosen, e.g. striped or tiled regions with fixed dimensions. Then, the mapper requests its input image to upstream fil-ter(s) sequentially, region after region. The data re-quest and generation is handled through the pipeline in the same way as for the information: once the re-quest reaches the sources, initiating the pipeline, the requested region is produced, then processed through filters, to finally end in the mapper. The pipeline exe-cution continues with the next image region until the entire output is generated. This mechanism, named streaming, enables the processing of very large images regardless the memory consumption of the process ob-jects composing the pipeline.
2. TF workflow
TF uses symbolic programming, which distinguish definition of computations from their execution. In TF, tensors are abstraction objects of the operations and objects in the memory, simplifying manipulation regardless the computing environment (e.g. CPU or GPU). A TF model consists in operations arranged into a graph of nodes. Each node can viewed as an operation taking zero or more tensors as inputs, and producing a tensor. This data flow graph defines the operations (e.g. linear algebra operators), but the computations are performed within the so-called ses-sion. A high-level API enables the construction of TF graphs, and the session runs the graph in delegating calculations to low level, highly-optimized routines. Among tensors, we can distinguish concepts such as Placeholders, Constants and Variables. A Placeholder is a symbol hosting input data, e.g. a set of images. As its name indicates, Constants are tensors with con-stant values, and Variables hold non persistent values, e.g. parameters to estimate during training. Vari-ables must be explicitly initialized, and can be saved or restored during a session along with the graph. A number of tools enable design of TF models, like the TF Python API or user-oriented software developed
Author-produced version of the article published in IEEE Geoscience and Remote Sensing Letters, 2019, 16 (1), pp. 25-29 The original publication is available at https://ieeexplore.ieee.org
by the TF community.
C. Flowing the pipeline
In this section, we present prerequisites for the in-tegration of a process object that runs TF session for generic deep nets, in a OTB pipeline with RS images as data objects. In the pipeline workflow, the genera-tion of images informagenera-tion and the requested regions computation by process objects, are crucial steps. We denote the spacing the physical size of a single RS image pixel. The generation of output images infor-mation includes origin, spacing, size, and additional RS metadata e.g. projection reference. Process ob-jects must also propagate the requested regions to in-put images. Regarding deep nets implementation, and particularly CNNs, this process must be carefully han-dled. CNNs usually involve several operations, mostly including a succession of convolutions, pooling, and non-linear functions. There is also a number of de-riving operators e.g. transposed convolution. Most of these operators modify the size and spacing of the result. For example, convolution can change the out-put image size, depending its kernel size and inout-put padding. It can also change the spacing of the output if performed with strides, that is, the step of which is shifted the filter at each computation. Pooling opera-tors are also a common kind of operator that modify the output size and spacing, depending of the stride and the size of the sliding window. We should note that a number of other operators change size and scale the spacing of the output.
Considering a process object implementing such op-erations, it must propagate requested regions of im-ages to its inputs. In the following, we introduce a generic description of size and spacing modifications that a deep net induces in processing RS images. We name the scaling factor of a particular output of the net, the ratio between the output spacing and a ref-erence spacing (typically one input image feeding the deep net). This parameter enables the description of any change of physical size of the pixel introduced by operators such as pooling or convolution involving non-unitary strides. In addition, each input has its own receptive field , the input space that a particular output of the net is affected by. In the same way, each output has its own expression field, the output space resulting from the receptive field. Images regions and spacing modifications induced by a TF graph are thus defined with the receptive field of inputs, and the scal-ing factor and expression field of outputs.
D. Running TF session in process object We introduce a new OTB process object which internally invokes the TF engine and enforces the pipeline execution described in SectionII Cand hence, can seamlessly process large images. It takes one or
multiple input images, and produces zero or multi-ple output images. The input placeholders of the TF model are fed with the input images of the process object. After the session run, computed tensors are assigned to the process object outputs. Placehold-ers corresponding to input images, as well as tensors corresponding to output images, are both specified as named in the TF model. The process object uses re-ceptive field of inputs, as well as expression field and scaling factor of outputs, to propagate requested in-put images regions and generate information of outin-put images. Finally, two processing modes are currently supported:
1. Patch-based
Extract and process patches independently at reg-ular intervals. Patches sizes are equal to the receptive field sizes of inputs. For each input, a tensor with a number of elements equal to the number of patches feds the TF model.
2. Fully-convolutional
Unlike patch-based mode, it allows the processing of an entire requested region. For each input, a ten-sor composed of one single element, corresponding to the input requested region, is fed to the TF model. This mode requires that receptive fields, expression fields and scale factors are consistent with operators implemented in the TF model, input images physical spacing and alignment. Blocking artifact is avoided by computing input images regions aligned to the ex-pression field sizes of the model, and keeping only the subset of the output corresponding to the requested output region.
E. New OTB applications
OTB applications generally implement pipelines composed of several process objects connected to-gether. We first provide a new application dedicated to RS images sampling suited for DL. Then, using our new filter described in Section II D, we provide new applications for TF model training and serving. Finally, we introduce some new applications consist-ing in an assembly of multiple OTB applications. All these new applications are integrated seamlessly in the existing machine learning framework of OTB.
1. Sampling
The existing machine learning framework of OTB includes sample selection and extraction applications suited for geospatial data like vector layers and RS images. Multiple sampling strategies can be chosen,
4 with fine control of parameters. However, DL on
im-ages usually involves reference data made of patches, but the existing application performs pixel-wise sam-ple extraction. We introduce a new application that performs patches extraction in input images, from samples positions resulting from the existing sample selection application of OTB. As we want to stick to RS images files formats, samples are concatenated in rows to form one unique big image of patches. Typ-ically, considering a number n of sampled patches of size [Srow, Scol, Sch], the resulting image have a size
of [n ⋅ Srow, Scol, Sch]. The main advantage of this
technique is that pixel interleave is unchanged (typ-ically row, column, channel), guaranteeing the effi-cient copy and processing.
2. Training
Since the high level TF API is Python, we provide a light Python environment to allow developers to build and train their models from patches images produced using our sampling application described in Section
II E 1. As there is already a number of available TF models and existing user-oriented opens-source appli-cations to create TF models, we chose not to focus it.
Our contribution for RS images deep net training is a user-oriented OTB application dedicated for train-ing existtrain-ing TF models. The application can import any existing TF model. It can restore from file model variables before the training, or save them to disk af-ter training. Thus this application can be used either to train a particular model from scratch, or perform fine tuning depending on the variables restored. The training can be performed over one or multiple inputs given their corresponding TF placeholders names and provide usual evaluation metrics.
3. Model serving
We introduce a single OTB application dedicated to TF model serving, that implements a pipeline with the filter described in SectionII D. It produces one output image resulting from TF model computations. As the entire pipeline implements the streaming mechanism described in SectionII C, it can process one or multi-ple images of arbitrary sizes. The user can adjust the produced images blocks sizes, thanks to the internal OTB application architecture. This application pro-vides a generic support for the operational deployment of trained deep nets on RS images.
4. Composite applications
Composite applications are OTB applications con-nected together. Recent studies have suggested that deep nets features can be used as input features of
Table 1. Models parameters Maggiori FC17 Ienco M3
RF 80x80 (VHRS ) 1x1 (TS ), 25x25 (VHRS )
EF 16x16 1x1
Mode Fully-conv Patch-based
Reference VHRS TS
Table 2. Characteristics of the dataset
Id Product type Size (col× row × band) Pixel spacing VHRS Spot-7 PXS 24110× 33740 × 4 1.5 meters TS S2 Time series 3616× 5060 × 592 10 meters
algorithms like classification, leading state of the art results. Regarding RS image classification, OTB al-ready implement a number of algorithms in its classifi-cation appliclassifi-cation, e.g. SVM, Random Forests, boost classifier, decision tree classifier, gradient boosted tree classifier, normal Bayes classifier. In the sake of demonstrating the operational aspect of our approach, we implement a composite application that reuse our model serving application (described in II E 3) as in-put of two existing OTB applications: the TrainIm-agesClassifier and ImTrainIm-agesClassifier applications re-spectively dedicated to train a classifier and perform an image classification.
III. EXPERIMENTS
In this section, we analyze performances of our TF model serving application. We conduct a series of ex-periments on two representative state of the art deep nets for RS images, the Maggiori et al. fully con-volutional model [10] and the Ienco M3 data fusion model [13]. Both perform land cover classification, but are different in terms of architecture as well as imple-mentation. The model of Maggiori is a single-input CNN composed exclusively of convolutions, pooling and activation functions, allowing to process one im-age region with a single convolution. The M3 model is an hybrid CNN-RNN model that inputs time se-ries (TS) and one VHRS image. Unlike the Maggiori model, it consumes patches of the VHRS image and one pixel stack of time series, to perform a single es-timation at one only location. Table 1 summarizes models parameters: Expression Field (EF), Receptive Fields (RF), mode and input reference image. Both models have an unitary scale factor. The used images are presented in Table2: one VHRS Spot-7 image ac-quired within the GEOSUD project[28] and one S2 TS provided by the THEIA Land Data Center[29]. The TS consists in spectral bands resampled at 10m and additional radiometric indices. The Maggiori net was trained to estimate two classes and M3 eight classes.
All experiments are conducted on two computers. The first is a basic workstation without GPU support (Intel Xeon CPU E5-2609 @ 2.50GHz and 16 GB of
Author-produced version of the article published in IEEE Geoscience and Remote Sensing Letters, 2019, 16 (1), pp. 25-29 The original publication is available at https://ieeexplore.ieee.org
0 4e+08 8e+08 0 500 1000 1500 2000 Number of pixels
Processing time (seconds)
CPU (Ts=128) CPU (Ts=512) CPU (Ts=2048) GPU (Ts=128) GPU (Ts=512) GPU (Ts=2048) 0 1e+07 1.8e+07 0 5 10 15 20 25 Number of pixels
Processing time (hours)
CPU (Ts=16) CPU (Ts=32) CPU (Ts=64) GPU (Ts=16) GPU (Ts=32) GPU (Ts=64) (a) MAG17 (b) M3
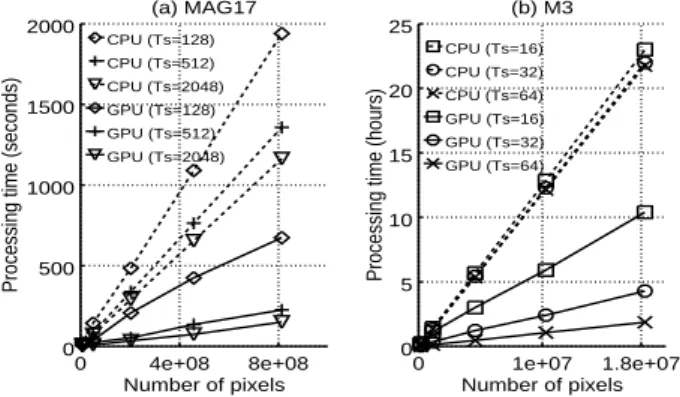
Figure 1. Measured processing times for different images sizes for (a) the Maggiori model (MAG17) and (b) Ienco M3 model (M3 )
RAM). The second is a server with GPU support (In-tel (R) Xeon (R) CPU E5-2667 [email protected] with 256 GB of RAM and TITAN X GPU). Libraries versions are OTB 6.7 and TF 1.7. We measure run times of our applications using the two models on both configura-tions, for different computed images sizes and various tile size. We presents separately the results for both models because their processing time differs largely due to the fact that M3 is more complex than the Maggiori model. Figure1shows that processing time is linear to the number of pixels of the produced im-age, regardless parameters. Very large input datasets are entirely processed thank to the streaming mecha-nism, even on the basic workstation with only 16Gb RAM. TF computations are benefiting strongly from the GPU support especially for image convolution, but CPU workstation processing time is reasonable with less than 24 hours for M3 (Fig. 1b) and less than 1 hour for the Maggiori model (Fig.1a).
IV. DISCUSSION
A. Operational deep learning framework for RS images
Our first goal was to provide a generic DL frame-work for RS images processing. We propose a solution which takes roots in the OTB library. The original machine learning framework was enriched to embed TF for training and using deep neural networks. We introduce a new component enforcing the OTB work-flow, that developers can implement in pipelines. We present a set of new applications that users without programming knowledge can operate: patches sam-pling, model training and serving, and also training and classification applications performing on features of any deep net exported as a TF model. Our ap-proach is successfully applied to common RS images with two representative state of the art deep nets. Processing times measurements have shown a great
scalability and also that our applications can run deep nets without restriction on dataset size and regardless hardware configuration.
B. Limits and further research
It should be noted that the presented method also has limits. The user has responsibility in providing crucial parameters to applications. In particular, re-ceptive field, expression field and scale factor of deep nets. In future development, those parameters could be extracted from the serialized TF graph. In the same way, the memory footprint is computed within the OTB pipeline, but does not takes in account the memory consumed internally by TF during the exe-cution of the computational graph: the user is thus responsible of fine tuning using the OTB application engine parameters.
V. CONCLUSION
This work was carried out with a view toward pro-cessing remote sensing (RS) images using deep learn-ing (DL) techniques from the user perspective. We propose a generic framework based on Orfeo Toolbox (OTB) and TensorFlow (TF) libraries. We have suc-cessfully applied existing state of the art deep nets on common RS images using our framework and shown a good computational efficiency, without restriction on images sizes and regardless hardware configuration. Our approach enables users without coding skills to use deep nets in their RS applications, and develop-ers to create operational RS processing pipelines ben-efiting from the development framework of OTB li-brary. Our approach allows the combination of the existing OTB machine learning framework with deep nets. The integration of DL processes in high per-formance computing architectures is enabled thank to the heterogeneous devices supported by the used li-braries. Further research could focus on improving the automatic retrieval of nets parameters and mem-ory footprint. The source code and documentation corresponding to the implementation presented in this paper is available at [30], and the exposed framework will be proposed as official contribution in the forth-coming releases of OTB.
ACKNOWLEDGMENTS
The author thanks the OTB team, Dino Ienco and Emmanuel Maggiori. This work was supported by public funds received through GEOSUD, a project (ANR-10-EQPX-20) of the Investissements d’Avenir program managed by the French National Research Agency. The author would also like to thank the re-viewers for their valuable suggestions.
6
[1] J. A. Benediktsson, J. Chanussot, and W. M. Moon. Advances in very-high-resolution remote sensing. Pro-ceedings of the IEEE, 101, 2013.
[2] Mordechai Haklay and Patrick Weber. Open-streetmap: User-generated street maps. IEEE Per-vasive Computing, 7(4):12–18, 2008.
[3] Xiao Xiang Zhu, Devis Tuia, Lichao Mou, Gui-Song Xia, Liangpei Zhang, Feng Xu, and Friedrich Fraun-dorfer. Deep learning in remote sensing: a review. arXiv preprint arXiv:1710.03959, 2017.
[4] Sizhe Chen and Haipeng Wang. Sar target recognition based on deep learning. In Data Science and Advanced Analytics (DSAA), 2014 International Conference on, pages 541–547. IEEE, 2014.
[5] Dinh Ho Tong Minh, Dino Ienco, Raffaele Gaetano, Nathalie Lalande, Emile Ndikumana, Faycal Osman, and Pierre Maurel. Deep recurrent neural networks for winter vegetation quality mapping via multitemporal sar sentinel-1. IEEE Geoscience and Remote Sensing Letters, 15(3):464–468, 2018.
[6] Lei Wang, K Andrea Scott, Linlin Xu, and David A Clausi. Sea ice concentration estimation during melt from dual-pol sar scenes using deep convolutional neural networks: A case study. IEEE Transactions on Geoscience and Remote Sensing, 54(8):4524–4533, 2016.
[7] Y. Chen, Z. Lin, X. Zhao, G. Wang, and Y. Gu. Deep learning-based classification of hyperspectral data. IEEE Journal of Selected Topics in Applied Earth Ob-servations and Remote Sensing, 7(6):2094–2107, June 2014.
[8] W. Li, G. Wu, and Q. Du. Transferred deep learning for anomaly detection in hyperspectral imagery. IEEE Geoscience and Remote Sensing Letters, 14(5):597– 601, May 2017.
[9] Michele Volpi and Devis Tuia. Dense semantic label-ing of subdecimeter resolution images with convolu-tional neural networks. IEEE Transactions on Geo-science and Remote Sensing, 55(2):881–893, 2017. [10] Emmanuel Maggiori, Yuliya Tarabalka, Guillaume
Charpiat, and Pierre Alliez. High-resolution aerial image labeling with convolutional neural networks. IEEE Transactions on Geoscience and Remote Sens-ing, 55(12):7092–7103, 2017.
[11] Gong Cheng and Junwei Han. A survey on object de-tection in optical remote sensing images. ISPRS Jour-nal of Photogrammetry and Remote Sensing, 117:11– 28, 2016.
[12] Paolo Napoletano. Visual descriptors for content-based retrieval of remote-sensing images. Interna-tional Journal of Remote Sensing, 39(5):1343–1376, 2018.
[13] Dino Ienco, Raffaele Gaetano, Claire Dupaquier, and Pierre Maurel. Land cover classification via multi-temporal spatial data by deep recurrent neural net-works. IEEE Geoscience and Remote Sensing Letters, 14(10):1685–1689, 2017.
[14] Luis Gomez-Chova, Devis Tuia, Gabriele Moser, and Gustau Camps-Valls. Multimodal classification of re-mote sensing images: A review and future directions. Proceedings of the IEEE, 103(9):1560–1584, 2015. [15] P Benedetti, D Ienco, R Gaetano, K Os´e, R Pensa,
and S Dupuy. M3fusion: A deep learning architecture for multi-{Scale/Modal/Temporal} satellite data
fu-sion. arXiv preprint arXiv:1803.01945, 2018. [16] Giuseppe Masi, Davide Cozzolino, Luisa Verdoliva,
and Giuseppe Scarpa. Pansharpening by convolu-tional neural networks. Remote Sensing, 8(7):594, 2016.
[17] Yi Yang and Shawn Newsam. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL international conference on advances in geographic information sys-tems, pages 270–279. ACM, 2010.
[18] Postdam dataset. www2.isprs.org/commissions/ comm3/wg4/2d-sem-label-potsdam.html. Accessed: 2018-04-30.
[19] Keiller Nogueira, Ot´avio AB Penatti, and Jefersson A dos Santos. Towards better exploiting convolutional neural networks for remote sensing scene classifica-tion. Pattern Recognition, 61:539–556, 2017.
[20] Dimitrios Marmanis, Mihai Datcu, Thomas Esch, and Uwe Stilla. Deep learning earth observation classifica-tion using imagenet pretrained networks. IEEE Geo-science and Remote Sensing Letters, 13(1):105–109, 2016.
[21] Fan Hu, Gui-Song Xia, Jingwen Hu, and Liangpei Zhang. Transferring deep convolutional neural net-works for the scene classification of high-resolution re-mote sensing imagery. Rere-mote Sensing, 7(11):14680– 14707, 2015.
[22] Manuel Grizonnet, Julien Michel, Victor Poughon, Jordi Inglada, Micka¨el Savinaud, and R´emi Cresson. Orfeo toolbox: open source processing of remote sens-ing images. Open Geospatial Data, Software and Stan-dards, 2(1):15, 2017.
[23] Mart´ın Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al. Tensorflow: A system for large-scale machine learning. In OSDI, volume 16, pages 265–283, 2016. [24] T. S. Yoo, M. J. Ackerman, W. E. Laorensen,
W. Schroeder, V. Chalana, S. Aylward, D. Metaxas, and R. Whitaker. Engineering and algorithm design for an image processing API: A technical report on ITK - The Insight Toolkit. In IOS Press Amsterdam J. Westwood, ed., editor, Proceedings of Medecine Meets Virtual Reality, 2002.
[25] Jordi Inglada, Arthur Vincent, Marcela Arias, Ben-jamin Tardy, David Morin, and Isabel Rodes. Op-erational high resolution land cover map production at the country scale using satellite image time series. Remote Sensing, 9(1):95, 2017.
[26] R´emi Cresson and Gabriel Hautreux. A generic frame-work for the development of geospatial processing pipelines on clusters. IEEE Geoscience and Remote Sensing Letters, 13(11):1706–1710, 2016.
[27] Luis Ibez and Brad King. ITK
(http://www.aosabook.org/en/itk.html). Accessed: 2016-05-24.
[28] www.equipex-geosud.fr. [29] http://www.theia-land.fr/en.
[30] OTBTensorflow remote module for orfeo toolbox.
https://github.com/remicres/otbtf. Accessed: 2018-09-05.
Author-produced version of the article published in IEEE Geoscience and Remote Sensing Letters, 2019, 16 (1), pp. 25-29 The original publication is available at https://ieeexplore.ieee.org