E-Lexic : Extraction lexicale à partir de textes bilingues alignés
Texte intégral
Figure


Documents relatifs
Pour cela nous allons extraire tous les triplets (S,V,C) grâce à un analyseur syntaxique partiel des textes. Ensuite avec l’extraction des motifs fréquents nous ne gardons que
Cet article présente une méthode semi-automatique de construction d’ontologie à partir de corpus de textes sur un domaine spécifique.. Cette mé- thode repose en premier lieu sur
La premiere m´ethode construit la hi´erarchie de concepts (noyau d’ontologie) avec une m´ethode for- melle, l’ACF, puis elle repr´esente chaque classe d’objets c´elestes dans
Il doit pouvoir y mettre, pour des raisons mn´emoniques qui lui sont propres, ce qu’il pense vraiment - afin que le rappel ne soit pas contraint - par exemple pouvoir associer au
Création et pondération des liens Il s’agit de créer un graphe avec les documents pour nœuds et un lien pondéré entre chaque paire de documents où une co-occurrence
Dans ce travail, une théorie trigonométrique non locale de déformation de cisaillement des poutres basée sur la position de l'axe neutre est développée pour l'analyse
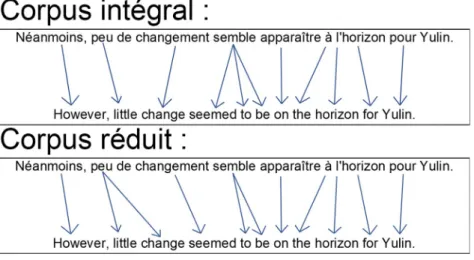
Notre recherche vise à tester l’aligneur intégré récemment dans UNITEX (cf. section 6) afin de constituer des textes parallèles, qui seront d’une grande
Nous sugg´ erons d’adapter pour la RIM, l’ap- proche d’expansion automatique de requˆ etes par la base g´ en´ erique de r` egles d’association MGB que nous avons propos´ ee
