Building a state space for song learning
by
Emily Lambert Mackevicius
Submitted to the Brain and Cognitive Sciences Department
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
June 2018
© Massachusetts Institute of Technology 2018. All rights reserved.
Author . . . .
Brain and Cognitive Sciences Department
May 4, 2018
Certified by. . . .
Michale S. Fee
Glen V. and Phyllis F. Dorflinger Professor of Neuroscience
Thesis Supervisor
Accepted by . . . .
Matthew A. Wilson
Sherman Fairchild Professor of Neuroscience and Picower Scholar;
Director of Graduate Education for Brain and Cognitive Sciences
Building a state space for song learning
by
Emily Lambert Mackevicius
Submitted to the Brain and Cognitive Sciences Department on May 4, 2018, in partial fulfillment of the
requirements for the degree of Doctor of Philosophy
Abstract
Song learning circuitry is thought to operate using a unique representation of each moment within each song syllable. Distinct timestamps for each moment in the song have been observed in the premotor cortical nucleus HVC, where neurons burst in sparse sequences. However, such sparse sequences are not present in very young birds, which sing highly variable syllables of random lengths. Furthermore, young birds learn by imitating a tutor song, and it was previously unclear precisely how the experience of hearing a tutor might shape auditory, motor, and evaluation path-ways in the songbird brain. My thesis presents a framework for how these pathpath-ways may assemble during early learning, using simple neural mechanisms. I start with a neural network model for how premotor sequences may grow and split. This model predicts that the sequence-generating nucleus HVC would receive rhythmically pat-terned training inputs. I found such a signal when I recorded neurons that project to HVC. When juvenile birds sing, these neurons burst at the beginning of each syllable, and when the birds listen to a tutor, neurons burst at the rhythm of the tutor’s song. Bursts marking the beginning of every tutor syllable could seed chains of sequential activity in HVC that could be used to generate the bird’s own song imitation. I next used functional calcium imaging to characterize HVC sequences before and after tutor exposure. Analysis of these datasets led us to develop a new method for unsuper-vised detection of neural sequences. Using this method, I was able to observe neural sequences even prior to tutor exposure. Some of these sequences could be tracked as new syllables emerged after tutor exposure, and some sequences appeared to become coupled to the new syllables. In light of my new data, I expand on previous models of song learning to form a detailed hypothesis for how simple neural processes may perform song learning from start to finish.
Thesis Supervisor: Michale S. Fee
Acknowledgments
Thank you to the following funding sources for their support: Henry E. Singleton (1940) Presidential Fellowship, NIGMS Integrative Neuronal Systems training grant, NDSEG graduate fellowship, Mathers Foundation Grant 024094-001, NIH Grant 5-RO1-DC009183-03, Simons Award 365000.
Thank you to my thesis committee members, Mriganka Sur, Laura Schulz, Josh McDermott, and Sam Gershman, for helpful perspectives, support, and guidance.
I am grateful to all current and former members of the Fee Lab for your help, fun discussions, and collaborations. Tatsuo Okubo, thanks for including me on your sequence growth and splitting project, and for inspiring a lot of my subsequent work. Natasha Denissenko, thanks for working together to get functional calcium imaging working in juvenile birds. Shijie Gu, thanks for working together on calcium data cell extraction analyses. Andrew Bahle, thanks for working together on seqNMF and discussing models of auditory-motor learning. Thanks for a wide range of valuable help and support from lab managers and staff Dan Rubin, Anton Konovchenko, Tim Currier, Shelbi Ferber, Margo O’Leary and Kail Miller.
Huge thanks to my advisor Michale Fee for all your help and guidance. I’ve relied on both your amazing capacity to generate many exciting new directions, and your amazing capacity to prune down and recognize what to focus on. You are a joy to work with. I’ll forever be inspired by how you practice science.
I value the neuroscience communities I’ve been part of. At the Brain and Cognitive Sciences Department, I got a lot of support for running computational tutorials, including from the Seminar Committee and from the Center for Minds Brains and Machines. I am also grateful for what I learned in many other building 46 seminar series and discussions. I am also especially grateful to the Methods in Computational Neuroscience summer course, where I learned a ton, and was able to start several exciting projects.
Finally I want to thank my friends and family for supporting me, inspiring me, adventuring with me, and being my role models.
Contents
1 Introduction1 19
1.1 Learning complex sequential behaviors . . . 19
1.2 Brain areas and neural pathways involved in song learning . . . 22
1.3 Song acquisition through reinforcement learning (RL) . . . 23
1.4 Mechanisms underlying HVC sequences . . . 26
1.5 Learning sequences for song timing . . . 28
2 Model of the growth and splitting of motor sequences during song development2 29 2.1 Introduction . . . 29 2.2 Methods . . . 32 2.2.1 Network architecture . . . 32 2.2.2 Network dynamics . . . 32 2.2.3 Seed neurons . . . 34
2.2.4 Synaptic plasticity rules . . . 36
2.2.5 Shared and specific neurons . . . 38
2.2.6 Visualizing network activity . . . 38
2.2.7 Code availability . . . 39
2.2.8 Data availability . . . 39
2.3 Results . . . 40
1Adapted in part from: Mackevicius and Fee, Current Opinion in Neurobiology, 2018.
[Mackevi-cius and Fee, 2018]
2Adapted in part from: Okubo, Mackevicius, Payne, Lynch and Fee, Nature, 2015. [Okubo et al.,
2.3.1 Initial model architecture . . . 40
2.3.2 Learning a protosequence through rhythmic activation of seed neurons . . . 40
2.3.3 Learning to split the protosequence . . . 40
2.3.4 Capturing a diverse set of learning strategies . . . 41
2.4 Discussion . . . 41
3 A sensorimotor signal that may play a role in building a new motor program 45 3.1 Introduction . . . 46
3.2 Methods . . . 49
3.2.1 Animal care and use . . . 49
3.2.2 Neural recordings in freely behaving zebra finches . . . 50
3.2.3 Analysis of song data . . . 50
3.2.4 Analysis of neural data . . . 51
3.3 Results . . . 52
3.3.1 Singing-related activity of NIf_HVC neurons in juvenile birds. 52 3.3.2 NIf_HVC neurons burst prior to syllable onset even during subsong . . . 54
3.3.3 Latency as a function of anatomical position . . . 56
3.3.4 Syllable-selective activity during singing . . . 56
3.3.5 NIf activity during tutoring . . . 58
3.4 Discussion: signals observed in NIf may drive the growth and differen-tiation of a new motor program . . . 62
4 SeqNMF algorithm for unsupervised discovery of temporal sequences in high-dimensional datasets, with applications to neuroscience 3 67 4.1 Introduction . . . 68
4.2 Results . . . 70
4.2.1 Matrix factorization framework for unsupervised discovery of
features in neural data . . . 70
4.2.2 Testing the performance of seqNMF on simulated sequences . 78 4.2.3 Application of seqNMF to hippocampal sequences . . . 95
4.2.4 Application of seqNMF to abnormal sequence development in avian motor cortex . . . 97
4.2.5 Application of seqNMF to a behavioral dataset: song spectro-grams . . . 99
4.3 Discussion . . . 101
4.4 Methods and Materials . . . 103
4.4.1 Table of key resources . . . 103
4.4.2 Contact for resource sharing . . . 103
4.4.3 Software and data availability . . . 103
4.4.4 Generating simulated data . . . 104
4.4.5 SeqNMF algorithm details . . . 104
4.4.6 Hippocampus data . . . 112
4.4.7 Animal care and use . . . 112
4.4.8 Calcium imaging . . . 112
4.5 Deriving multiplicative update rules . . . 113
4.5.1 Standard NMF . . . 113
4.5.2 Standard convNMF . . . 115
4.5.3 Incorporating regularization terms . . . 115
5 Examining the role of tutor exposure in the emergence of sequences in HVC 119 5.1 Introduction . . . 119
5.2 Methods and Materials . . . 121
5.2.1 Table of key resources for imaging HVC sequences . . . 121
5.2.2 Animal care and use . . . 121
5.2.4 Extraction of neuronal activity and background subtraction
us-ing CNMF_E . . . 123
5.2.5 Unsupervised discovery of neural sequences using seqNMF . . 124
5.2.6 Preprocessing calcium traces prior to running seqNMF . . . . 124
5.2.7 Estimating the number of significant sequences in each dataset 126 5.2.8 Selecting a consistent factorization . . . 127
5.2.9 Significance testing for cross-correlation analyses . . . 127
5.2.10 Assessing the cross-correlation between each factor and acoustic song features . . . 128
5.2.11 Assessing which neurons participate in each sequence . . . 128
5.2.12 Tracking HVC projection neurons over the course of major song changes . . . 128
5.3 Results . . . 130
5.3.1 Rapid learning after late tutoring . . . 130
5.3.2 Presence of sequences prior to tutoring . . . 131
5.3.3 Correlation of pre-tutoring sequences with song . . . 132
5.3.4 Participation of neurons within pre-tutoring sequences . . . . 136
5.3.5 Auto-correlation and cross-correlation of neural sequences prior to tutoring . . . 136
5.3.6 Comparing the composition of HVC sequences before and after tutor exposure . . . 136
5.3.7 Stable neural sequences underlie rapid song changes . . . 140
5.4 Discussion: latent HVC sequences provide a state space for song learning143 6 Discussion: hypothesized neural processes underlying song learning4149 6.1 Process 0: ‘Latent’ sequences form in HVC . . . 150
6.2 Process 1: A ‘tutor memory’ is formed in auditory cortex . . . 151
6.3 Process 2: Activation of the ‘tutor memory’ shapes the formation of multiple syllable chains in HVC . . . 152
4Adapted in part from: Mackevicius and Fee, Current Opinion in Neurobiology, 2018.
6.4 Process 3: Temporally-precise correspondence is established between HVC and auditory cortex . . . 153 6.5 Process 4: Learning connections from HVC to downstream nucleus RA 155 6.6 Relation to other hypothesized roles for sensorimotor interactions . . 156 6.7 Evidence and reflections . . . 156
List of Figures
1-1 Reinforcement learning of sequential behavior, implemented by the songbird brain . . . 21 2-1 Singing-related firing patterns of HVC projection neurons in juvenile
birds at different stages of song development . . . 30 2-2 Activity in neural model of sequence formation and splitting
through-out learning . . . 31 2-3 Model of other strategies for syllable formation . . . 42 3-1 Recording at the interface between sensory and motor cortical circuits
in juvenile birds during song learning . . . 48
3-2 Example collision test of NIf_HVC neuron . . . 51
3-3 NIf fires at syllable onsets in singing juvenile birds . . . 53 3-4 Distributions of burst latencies relative to syllable onset at different
stages of vocal development . . . 55 3-5 During syllable differentiation, some NIf neurons burst selectively
be-fore certain syllable types . . . 57 3-6 When juvenile birds listen to tutor song, neurons in NIf burst at tutor
syllable onsets . . . 59 3-7 Further characterization of pre-syllable-onset activity during listening 60 3-8 During tutoring, some NIf neurons burst selectively before certain
syl-lable types . . . 61 3-9 Possible sources for signals observed in NIf, and possible role for NIf
4-1 Introduction to convNMF factorization, and failure modes motivating
seqNMF regularization . . . 71
4-2 Testing seqNMF on simulated data . . . 79
4-3 Testing seqNMF performance on sequences contaminated with noise . 82 4-4 Effect of dataset size on seqNMF reconstruction . . . 84
4-5 Procedure for choosing 𝜆 for a new dataset based on finding a balance between reconstruction cost and correlation cost . . . 85
4-6 Number of significant factors as a function of 𝜆 for datasets containing between 1 and 10 sequences . . . 87
4-7 Using cross-validation on held-out (masked) data to choose 𝜆 . . . 89
4-8 Estimating the number of sequences in a dataset using cross-validation on randomly masked held-out datapoints . . . 90
4-9 Using penalties to bias towards events-based and parts-based factor-izations . . . 91
4-10 Biasing seqNMF to parts-based or events-based factorizations of song-bird data . . . 93
4-11 Biasing factorizations between sparsity in W or H . . . 95
4-12 Application of seqNMF to extract hippocampal sequences from two rats 96 4-13 SeqNMF applied to calcium imaging data from a singing isolate bird reveals abnormal sequence deployment . . . 98
4-14 SeqNMF applied to song spectrograms . . . 100
4-15 Outline of the procedure used to assess factor significance. . . 109
5-1 Calcium imaging in HVC in singing birds . . . 122
5-2 Estimating the number of significant sequences in each dataset . . . . 125
5-3 Song development trajectories for our 8 birds, categorized into learners and non-learners . . . 131
5-4 Example data from two birds prior to tutor exposure. . . 133
5-5 Correlation between neural sequences present prior to tutoring and song for four birds that were learners. . . 134
5-6 Correlation between neural sequences and song for four birds that were non-learners . . . 135 5-7 Significance of participation of each neuron within each sequence for
four learners . . . 137 5-8 Significance of participation of each neuron within each sequence for
four non-learners . . . 138 5-9 Auto-correlations and cross-correlations of neural sequences . . . 139 5-10 Matching locations of cells in sequences from before and after tutor
exposure . . . 141 5-11 Stable neural sequences underlie rapid song changes . . . 142 5-12 Sequence used for new syllable is major part of HVC activity pre-tutoring143 5-13 Hypothesis for explaining speed vs. flexibility tradeoff in late-tutored
vs. normal birds . . . 147 6-1 Hypothesis for the role of auditory-motor interactions in song learning. 154
List of Tables
4.1 Notation for convolutional matrix factorization . . . 73 4.2 Links to key resources used for seqNMF . . . 103 4.3 Regularized NMF and convNMF: cost functions and algorithms . . . 105 5.1 Links to key resources used for measuring HVC sequences during rapid
learning . . . 121 6.1 Evidence for aspects of hypothesis . . . 158
Chapter 1
Introduction
1
1.1
Learning complex sequential behaviors
Some of the brain’s most fascinating and expressive functions, like music, athletic performance, speech, and thought itself, are learned sequential behaviors that re-quire thousands of repetitions of trial and error learning and observation of others. However, a fundamental challenge is learning how to structure these behaviors into appropriate chunks that can be acquired by trial and error learning. ‘Chunking’ has been highlighted as a central mechanism for learning action sequences in a variety of systems [Graybiel, 1998, Jin and Costa, 2015, Smith and Graybiel, 2016, Ostlund et al., 2009]. For example, the brain of a young musician does not know a priori the number or durations of melodies it will need to generate. The brain of a young athlete does not know how many maneuvers it will need to practice and eventually perfect. How does the brain flexibly construct motor programs that have the correct temporal state representations that then support trial-and-error learning to achieve complex behavioral goals?
Avian song learning, which shares crucial behavioral, circuit-level and genetic mechanisms with human speech [Doupe and Kuhl, 1999, White, 2001, Teramitsu et al., 2004, Pfenning et al., 2014, Prather et al., 2017] (Figure 1-1a), has provided a
1Adapted in part from: Mackevicius and Fee, Current Opinion in Neurobiology, 2018.
rich system for understanding how complex sequential behaviors are produced by the brain, including how they are learned through observation and practice. All songbirds, such as the widely studied zebra finch, learn to imitate the song of a conspecific tutor, typically the father. Juvenile zebra finches start off babbling subsong, then introduce a stereotyped ‘protosyllable’ of ≈100 ms duration. New syllables emerge through the differentiation of this protosyllable into multiple syllable types, until the song crystallizes into an adult song composed of 3 to 7 distinct syllables [Tchernichovski et al., 2000]. After several months of practice, zebra finches can produce a precise moment-to-moment imitation of their tutor’s song.
Song learning is influenced by both ‘nurture’ and ‘nature’, that is, by both auditory exposure to a particular tutor song, and by species-specific preferences [Tchernichovski and Marcus, 2014]. Zebra finches are able to learn songs of birds from other species, but when given a choice they prefer zebra finch song [Eales, 1987]. Canaries, another species of songbird, can even learn random tone sequences, but in adulthood tend to convert these random sequences to a more species-typical rhythm [Gardner et al., 2005]. Species-specific preferences may extend to the context in which a song is heard. For example, white crowned sparrows imitate songs following a species-typical 5kHz whistle, even if the song itself is species-atypical (for example, a squirrel alarm call) [Soha and Marler, 2000]. Zebra finches tend not to imitate songs they heard passively, but instead prefer songs they heard in a social context, that is, from a conspecific they interact with, or even from a mechanical apparatus they interact with [Derégnaucourt et al., 2013]. Zebra finches require remarkably little exposure to a tutor (approximately 75 seconds total, all occurring within a two hour block) for subsequent imitation [Deshpande et al., 2014]. When birds do not hear any tutor, they sing ‘isolate’ songs, with highly variable and abnormal syllable rhythms [Price, 1979, Williams et al., 1993, Fehér et al., 2009]. However, when these ‘isolate’ songs are used as tutor songs, after two generations songs become normal again, suggesting that an ‘innate’ preference filters what aspects of a tutor song are actually imitated [Fehér et al., 2009]. Thus, within the songbird brain we expect to see an interplay between ‘innate’ and learned structure.
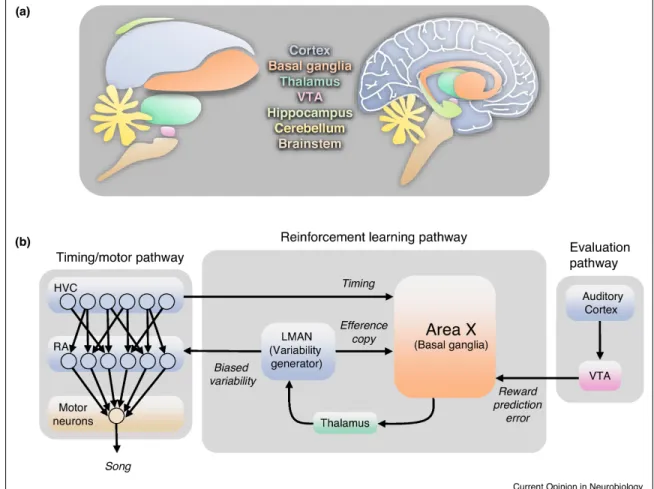
Figure 1-1: Reinforcement learning of sequential behavior, implemented by the song-bird brain
(a) Schematic showing several homologous structures in the songbird (left) and human (right) brains. (b) Diagram of the major areas and pathways in the songbird brain thought to be involved in song learning, production, and evaluation. Each area is colored according to anatomical location. Arrows denote monosynapic connections between areas. Some connections are left out of this diagram for simplicity, including bidirectional connections between HVC and auditory cortex.
1.2
Brain areas and neural pathways involved in song
learning
Careful analyses of cell types, projection patterns, and gene expression has led to the view that the songbird brain has homologs to all major parts of the mammalian brain, including cortex, thalamus, basal ganglia, and dopaminergic VTA [Pfenning et al., 2014, Jarvis et al., 2005, Karten, 1991, Karten, 2013, Reiner et al., 2004, Wang et al., 2010] (Figure 1-1a). Unlike the layered mammalian cortex, the songbird ‘cortex’ is organized in pallial fields [Karten, 2015], which share molecular markers with mammalian cortical layers [Dugas-Ford et al., 2012]. Within these distinct brain areas lie cell groups (or nuclei) whose primary function is song.
The song nuclei connect to each other, forming several pathways that underlie song production and learning (Figure 1-1b). A descending ‘cortical’ motor pathway consists of premotor and motor output nuclei (HVC and RA respectively) [Vu et al., 1994, Yu and Margoliash, 1996, Fee et al., 2004, Srivastava et al., 2017]. A learning pathway consists of a basal-ganglia-thalamo-cortical loop (Area X, DLM and LMAN respectively)[Bottjer et al., 1984, Scharff and Nottebohm, 1991, Luo et al., 2001, Doupe, 1993]. An auditory pathway is thought to store a memory of the tutor song [London and Clayton, 2008, Yanagihara and Yazaki-Sugiyama, 2016], and interacts with song areas both directly [Bauer et al., 2008, Akutagawa and Konishi, 2010], as well as indirectly through midbrain reward centers (VTA) [Mandelblat-Cerf et al., 2014, Gadagkar et al., 2016, Hoffmann et al., 2016].
Each of these pathways is thought to implement distinct functions of reinforce-ment learning [Doya and Sejnowski, 1995, Fiete et al., 2007, Fee and Goldberg, 2011, Brainard and Doupe, 2013]. Timing/Motor Pathway: Each individual pro-jection neuron in adult HVC bursts at a particular moment in the song, always oc-curring at the same moment in the song to submillisecond precision [Hahnloser et al., 2002, Long et al., 2010]. Different neurons burst at different times in the song, so that collectively, the population of projection neurons provides a sequence of timestamps that cover the entire song [Picardo et al., 2016, Lynch et al., 2016]. In this model, HVC
drives different ensembles of downstream neurons in RA and the vocal motor nucleus at different moments in the song. Reinforcement Learning Pathway: Song variability is largely driven by nucleus LMAN, a premotor cortical region that projects to the motor output nucleus RA [Kao and Brainard, 2006, Ölveczky et al., 2005, Ölveczky et al., 2011, Stepanek and Doupe, 2010]. During learning, song variations gener-ated by LMAN become biased toward successful song variations [Andalman and Fee, 2009, Tesileanu et al., 2017]. This bias represents the gradient of song performance in motor space, which could be used to shape motor circuitry through learning of HVC→RA synapses [Fee and Goldberg, 2011, Tesileanu et al., 2017]. It has been hypothesized that this gradient is computed using three signals that converge in the song-related basal ganglia, Area X [Fee and Goldberg, 2011]. Specifically, local en-sembles of medium spiny neurons in Area X receive: an efference copy of LMAN activity that generates song variations, a timing signal from HVC, and an evaluation signal from VTA. These signals allow Area X to determine which song variations, at which times, have led to improved performance, and thus to bias LMAN to produce the same variations at the same time in future song renditions, through a topograph-ically organized BG-thalamo-cortical feedback loop to LMAN [Luo et al., 2001, Fee, 2014]. Evaluation pathway through VTA: Song is evaluated by listening and com-paring to a template memory of the tutor song. The evaluation pathway starts in higher-order auditory cortical areas, which contain neurons selective for song errors [21,22]. The output of this evaluation pathway is VTA. Neurons in VTA projecting to Area X convey a song performance prediction error signal used to guide learning [Gadagkar et al., 2016, Luo et al., 2001].
1.3
Song acquisition through reinforcement learning
(RL)
The RL framework underlies a predominant view of song learning [Doya and Se-jnowski, 1995, Fiete et al., 2007, Fee and Goldberg, 2011, Brainard and Doupe, 2013].
In recent incarnations of this view, premotor and motor nuclei HVC (proper name) and RA (robust nucleus of the arcopallium) generate a song ‘policy’—what vocal outputs to produce when. A variability-generating circuit LMAN (lateral magnocel-lular nucleus of the anterior nidopallium) serves as an ‘actor’ that injects variability into RA to produce variable song outputs [Kao and Brainard, 2006, Ölveczky et al., 2005, Ölveczky et al., 2011, Stepanek and Doupe, 2010, Kao et al., 2005, Leblois et al., 2010]. A pathway from auditory circuits through dopaminergic VTA (ventral tegmental area) to a basal ganglia circuit may serve as an ‘evaluator’ that detects which vocal variations successfully matched a memory of the tutor song [Keller and Hahnloser, 2009, Mandelblat-Cerf et al., 2014, Gadagkar et al., 2016]. Finally, the vocal basal ganglia circuit, which is necessary to learn changes in song acoustics [Ali et al., 2013], improves song policy by biasing the variability-generating circuit to pro-duce successful variations more often [Andalman and Fee, 2009, Warren et al., 2011]. This bias drives plasticity in the song motor pathway to consolidate an improved song policy [Andalman and Fee, 2009, Warren et al., 2011, Tesileanu et al., 2017]. See Figure 1-1b, and [Fee and Goldberg, 2011] for more extensive discussion of an RL model.
While song learning has traditionally been framed as an example of reinforcement learning, it differs from some classic RL examples, and could also be framed in different terms. Specifically, song learning could be thought of as learning a generative model of the tutor song, for example by unsupervised learning. For consistency with other work, we will keep the RL framing of song learning, but note two distinctions. First, in classic RL the actor receives external reinforcement, but songbirds generate an internal reinforcement signal [Gadagkar et al., 2016] based on comparing their song to a memory of a tutor song [Adret, 2004, Bolhuis and Moorman, 2015]. Second, song is a sequential behavior in which errors early in the sequence do not propagate to the rest of the sequence. In contrast with behaviors like navigating a maze or playing a game, where actions early in the sequence can have a profound effect on potential outcomes later in the sequence, one flubbed note need not spoil the whole song. This type of RL, described by Sutton and Barto as ‘contextual bandit’ RL, is
simpler than what they term ‘full’ RL, because actions only affect reward, but not future states [Sutton and Barto, 1998]. Thus, learning can occur independently at each state in time, using a time-dependent reward signal to associate each state with the appropriate action. This form of RL requires as input a representation of the context on which associated actions or emissions are learned.
Consistent with this view, songbird RL models take as input a sequence of contexts represented by a unique timestamp for each moment in the song [Fiete et al., 2007, Fee and Goldberg, 2011, Brainard and Doupe, 2013]. This representation is encoded in nucleus HVC of the song motor system. In adult birds, each individual premotor HVC neuron bursts at a single moment in the song. The bursts of each neuron are only 6 ms in duration occurring at the same moment in the song with submillisecond precision. Because different neurons burst at different times [Hahnloser et al., 2002, Long et al., 2010], the population of neurons collectively provides a continuous sequence of bursts that spans the entire song [Picardo et al., 2016, Lynch et al., 2016]. Each burst in the sequence activates a different ensemble of downstream neurons to generate the appropriate vocal output at that moment. Due to the sparseness of HVC coding, each syllable of the song is generated by a unique sequence of HVC bursts, which behavioral measurements of variability suggest are initiated at the offset of the previous syllable [Troyer et al., 2017]. See Box 1.4 for discussion of the neural mechanisms underlying sparse sequential bursting in HVC. Finally, HVC transmits sparse sequences both to the song motor pathway and to the song-related basal ganglia, which uses this sequential state space representation of song timing to perform RL [Fee and Goldberg, 2011, Brainard and Doupe, 2013].
Here we come to the crux of our problem: Like our young musician, prior to hearing their tutor, juvenile songbirds do not know how many syllables their songs will contain, making it unlikely that HVC could form, prior to tutoring, sequences for each syllable in the song to be acquired. Importantly, recent work suggests that such sequences may not already exist in the earliest stages of song development. This work also suggests that the sequential representation of time underlying RL emerges gradually during song acquisition, perhaps through an unsupervised Hebbian learning
process [Okubo et al., 2015].
Generating appropriate latent representations on which learning may efficiently operate is an area of active research in the machine learning and learning theory communities. In particular, RL algorithms are known to suffer the ‘curse of dimen-sionality’, and work poorly with inefficient high-dimensional representations of the state space [Barto and Mahadevan, 2003]. However, RL algorithms have achieved im-pressive human-level performance on a variety of tasks when based on efficient state representations obtained from a separate learning process involving deep learning and artificial neural networks [Mnih et al., 2015, Silver et al., 2016]. More generally, sev-eral recent advances in machine learning involve using interacting networks that each learn via separate processes [Sussillo et al., , Goodfellow et al., 2014]. Furthermore, the use of deep networks, historically difficult to train, experienced a major break-through [Hinton et al., 2006] with the application of pre-training using unsupervised processes to achieve generalizable representations [Erhan et al., 2010]. How latent structure learning could be implemented is a key research direction at the interface of biological and machine learning theory [Gowanlock et al., 2016, Lake et al., 2016]. Thus, to the extent that the brain employs RL, it also must model latent structure in the world to build representations that support RL [Gershman and Niv, 2010].
1.4
Mechanisms underlying HVC sequences
HVC plays a key role in song timing [Vu et al., 1994]. Lesions to HVC eliminate all consistently timed vocal gestures, and leave birds babbling subsong [Aronov et al., 2008]. Further evidence that HVC controls stereotyped song timing is that localized cooling of HVC slows song syllables by roughly 3% per degree C of cooling [Aronov et al., 2011, Long and Fee, 2008]. In contrast, cooling the downstream area (RA) does not slow the song beyond what would be expected from the small residual temperature change in HVC (which is several millimeters away) suggesting that the dynamics governing song timing are in HVC, and not RA [Long and Fee, 2008] nor in a loop involving RA (but see [Hamaguchi et al., 2016]).
A prevalent model of how HVC produces precisely timed sequences is the synaptic chain model [Long et al., 2010, Jun and Jin, 2007, Fiete et al., 2010, Li and Greenside, 2006, Jin et al., 2007], which hypothesizes that sequential activity in HVC neurons is due to direct synaptic connections between neurons that burst at successive moments in the song. Preliminary analysis of a small number of burst times seemed to suggest that HVC bursts only occur at certain special moments in the song [Amador et al., 2013], which would be inconsistent with a synaptic chain model. More recently, analysis of large datasets of HVC neurons has revealed that the network generates a sequence of bursts that spans the entire song with nearly uniform density [Picardo et al., 2016, Lynch et al., 2016]. Temporal patterning in HVC does not appear to be strongly spatially organized; neurons that burst at similar times appear to be scattered throughout HVC [Markowitz et al., 2015]. However, projections to HVC exhibit non-uniform topology, and lesion experiments suggest that medial HVC may play a disproportionate role in controlling transitions between syllables [Basista et al., 2014, Galvis et al., 2017, Elliott et al., 2017].
Inhibitory interneurons within HVC may play a role in governing the timing of HVC projection neurons [Mooney and Prather, 2005]. In the simplest case, inhibitory feedback may stabilize the propagation of activity through feedforward excitatory chains [Long et al., 2010, Jun and Jin, 2007, Fiete et al., 2010, Jin et al., 2007]. In addition, interneurons may play a more precise role in patterning projection neuron burst times [Kosche et al., 2015, Gibb et al., 2009a]. More recently, the interac-tion between excitatory and inhibitory neurons in HVC has been investigated using connectomic approaches [Kornfeld et al., 2017], revealing patterns of connectivity between projection neurons and interneurons consistent with synaptically connected chains of excitatory neurons embedded in a local inhibitory network.
HVC receives inputs from other brain areas that may influence song timing and structure. For example, inputs from cortical area Nucleus Interface (NIf) appear to affect syllable ordering and higher-order song structure [Hosino and Okanoya, 2000]. Inputs to HVC from NIf and the thalamic nucleus Uvaformis (Uva) exhibit a peak immediately prior to syllable onsets and a pronounced minimum during gaps between
syllables [Danish et al., 2017, Vyssotski et al., 2016], consistent with a special role of these areas in syllable initiation and timing. However, cooling studies reveal that HVC also plays a role in syllable syntax [Zhang et al., 2017], and inputs to HVC from Uva may also play some role in within-syllable song timing [Hamaguchi et al., 2016].
1.5
Learning sequences for song timing
The songbird is an excellent model system to examine how the brain builds a latent state space representation—namely, sequences in HVC. Recent findings suggest that these sequences emerge gradually throughout vocal development. At the earliest stage, only half of HVC projection neurons are reliably locked to song, with bursts clustered near the onsets of subsong syllables [Okubo et al., 2015], and lesions of HVC do not affect the babbling subsong [Aronov et al., 2011]. Maturation past subsong requires HVC, and is defined by the emergence of a consistently timed vocal gesture, called a protosyllable [Tchernichovski et al., 2001, Veit et al., 2011]. During the emergence of the protosyllable, HVC appears to grow a protosequence in which bursts span the entire syllable duration [Okubo et al., 2015].
How does a single protosequence transform into a different distinct sequence for each syllable in the adult song? At the level of the behavior, it has been observed that protosyllables can gradually differentiate into two syllable types [Tchernichovski et al., 2001]. Neural recordings in HVC during this process suggest that early protosequences gradually split to form multiple distinct syllable sequences. Sequence splitting is evidenced by the observation that, while some neurons burst selectively for one or the other emerging syllables, many neurons are active during both. Furthermore, the number of shared neurons decreases significantly at later stages of development. This splitting process repeats as birds differentiate enough new syllable sequences to compose their adult songs, at which point most neurons are syllable-specific, with very few shared neurons [Okubo et al., 2015].
Chapter 2
Model of the growth and splitting of
motor sequences during song
development
1
2.1
Introduction
An overarching aim of my thesis is to present a framework for how pathways in the songbird brain may assemble during early learning, using simple neural mechanisms. A particular focus is how motor sequences in HVC may interact with developing au-ditory and evaluation pathways. Essential to this aim is an understanding of how inputs to the motor area HVC could shape the development of HVC sequences. Pre-vious work from the lab shows that HVC sequences appear to grow and split during early learning [Okubo et al., 2015] (Figure 2.1). In this chapter, I present a model for how the formation of motor sequences in HVC could be shaped by inputs to HVC.
We propose a mechanistic model of learning in the HVC network to describe how sequences emerge during song development. This model is based on the idea that sequential bursting results from the propagation of activity through a continuous synaptically connected chain of neurons within HVC [Long et al., 2010, Jin et al.,
1Adapted in part from: Okubo, Mackevicius, Payne, Lynch and Fee, Nature, 2015. [Okubo et al.,
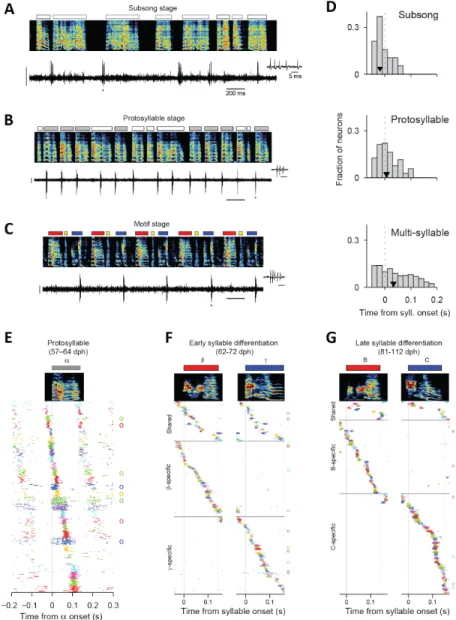
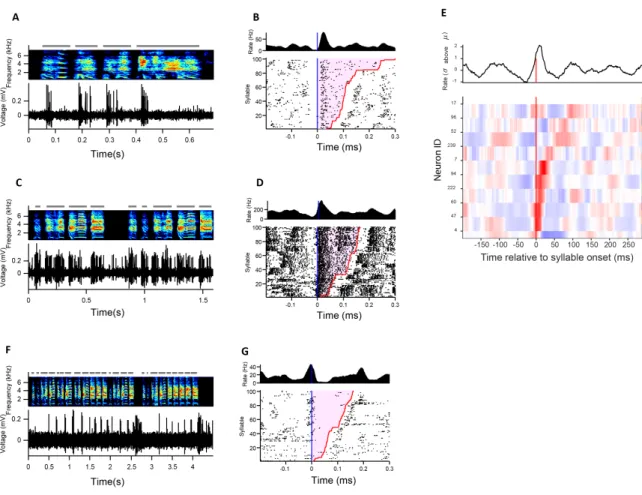
Figure 2-1: Singing-related firing patterns of HVC projection neurons in juvenile birds at different stages of song development
(from Tatsuo Okubo [Okubo et al., 2015], reproduced here for reference) (A) Neuron recorded in the subsong stage, prior to the formation of protosyllables (HVC_RA; 51 dph). Top: song spectrogram with syllables indicated above. Bottom: extracellular voltage trace. (B) Neuron recorded in the protosyllable stage (HVC_RA; 62 dph). Protosyllables indicated (gray bars). (C) Neuron recorded after motif formation (HVC_RA; 68 dph). (D) Distribution of burst latencies relative to syllable onset in subsong stage (top), protosyllable stage (middle), and multi-syllable/motif stages (bottom) Black triangle: median burst times. (E) Raster plot of 28 HVC projection neurons aligned to protosyllable onsets (sorted by latency; 57-64 dph). Antidromically identified HVC_RA neurons indicated by circles at right. (F) Raster of 105 projection neurons early in syllable differentiation showing shared and specific sequences. HVC_RA neurons indicated by circles at right. (G) Same as panel G but for 100 neurons recorded after differentiation of 𝛽 and 𝛾 into adult syllables B and C.
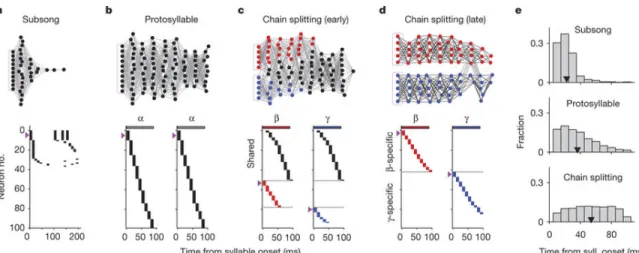
Figure 2-2: Activity in neural model of sequence formation and splitting throughout learning
a-d, Top, network diagrams of participating neurons (darker lines indicate stronger connections; magenta boxes indicate seed neurons). Bottom, raster plot of neurons showing shared and specific sequences. Neurons sorted by relative latency. Magenta arrows indicate groups of seed neurons. a, Subsong stage: activation of seed neurons produces a rapidly decaying burst of sequential activity. b, Protosyllable stage: rhythmic activation of seed neurons induces formation of a protosyllable chain. c, Alternating activation of red and blue seed neurons and synaptic competition drives the network to split into two chains (specific neurons, red and blue; shared neurons, black). d, Network after chain splitting. e, Distribution of model burst latencies during subsong, protosyllable stage and chain splitting stage (early and late combined).
2007, Li and Greenside, 2006, Jun and Jin, 2007, Fiete et al., 2010, Buonomano, 2005, Gibb et al., 2009a, Bertram et al., 2014]. It also captures non-uniformities such as increased burst density at syllable onsets, as formulated in a perspective of HVC function emphasizing vocal gestures [Amador et al., 2013].
Modelling studies have shown that a combination of two synaptic plasticity rules —spike-timing dependent plasticity (STDP) and heterosynaptic competition—can transform a randomly connected network into a feedforward synaptically connected chain that generates sparse sequential activity [Jun and Jin, 2007, Fiete et al., 2010]. We hypothesize that the same mechanisms can drive the formation of a rhythmic protosyllable chain, and subsequently split this chain into multiple daughter chains for different syllable types. To test this hypothesis, we constructed a simple network of binary units representing HVC projection neurons [Fiete et al., 2010].
2.2
Methods
To illustrate a potential mechanism of chain splitting, we chose to implement the model as simply as possible. We modelled neurons as binary units and simulated their activity in discrete time steps [Fiete et al., 2010]; at each time step (10 ms), the 𝑖th neuron either bursts (𝑥𝑖 = 1) or is silent (𝑥𝑖 = 0).
2.2.1
Network architecture
A network of 100 binary neurons is recurrently connected in an all-to-all manner, with
𝑊𝑖𝑗 representing the synaptic strength from presynaptic neuron 𝑗 to postsynaptic
neuron 𝑖. Self-excitation is prevented by setting 𝑊𝑖𝑗 = 0 for all 𝑖 at all times [Fiete
et al., 2010]. During learning, the strength of each synapse is constrained to be within the interval [0, 𝑤𝑚𝑎𝑥], while the total incoming and outgoing weights of each neuron
are both constrained by the “soft bound” 𝑊𝑚𝑎𝑥 = 𝑚 * 𝑤𝑚𝑎𝑥 where 𝑚 represents a
target number of saturated synapses per neuron [Fiete et al., 2010] (see Section 2.2.4
for details). Note that 𝑤𝑖𝑗 represents a hard maximum weight of each individual
synapse, while 𝑊𝑖𝑗 represents a soft maximum total synaptic input or output of any
one neuron. Synaptic weights are initialized with random uniform distribution such that each neuron receives, on average, its maximum allowable total input, 𝑊𝑖𝑗.
2.2.2
Network dynamics
The activity of each neuron in the network was determined in two steps: calculating the net feedforward input that comes from the previous time step; then determining whether that is enough to overcome the recurrent inhibition in the current time step.
First, the net feedforward input to the 𝑖th neuron at time step 𝑡, 𝐴𝑛𝑒𝑡
𝑖 (𝑡) , was
calculated by summing the excitation, feedforward inhibition, neural adaptation, and external inputs:
𝐴𝑛𝑒𝑡𝑖 (𝑡) =[︁𝐴𝐸𝑖 (𝑡) − 𝐴𝐼𝑓 𝑓(𝑡) − 𝐴𝑎𝑑𝑎𝑝𝑡
𝑖 (𝑡) + 𝐵𝑖(𝑡) − 𝜃𝑖
]︁
where [𝑧]+ indicates a rectification (equal to 𝑧 if 𝑧 > 0 and 0 otherwise). 𝐴𝐸𝑖 (𝑡) =
∑︀
𝑗𝑊𝑖𝑗𝑥𝑗(𝑡 − 1) is the excitatory input from network activity on the previous time
step. 𝐴𝐼𝑓 𝑓(𝑡) = 𝛽∑︀
𝑗𝑥𝑗(𝑡 − 1) is a global feedforward inhibitory input [Fiete et al.,
2010], where 𝛽 sets the strength of this feedforward inhibition. 𝐴𝑎𝑑𝑎𝑝𝑡
𝑖 (𝑡) = 𝛼𝑦𝑖 is an
adaptation term [Fiete et al., 2010] where 𝛼 is the strength of adaptation, and 𝑦𝑖 is
a low-pass filtered record of recent activity in 𝑥𝑖 with time constant 𝜏𝑎𝑑𝑎𝑝𝑡 = 40 ms;
that is 𝜏𝑎𝑑𝑎𝑝𝑡𝑑𝑦𝑑𝑡𝑖 = −𝑦𝑖 + 𝑥𝑖; 𝐵𝑖(𝑡) is the external input to neuron 𝑖 at time 𝑡. For
seed neurons, this term consists of training inputs (see Section 2.2.3). For non-seed neurons, it consists of random inputs with probability 𝑝𝑖𝑛 = 0.01in each time step and
size 𝑊𝑚𝑎𝑥/10. Finally, 𝜃𝑖 is a threshold term used to reduce the excitability of seed
neurons, making them less responsive to recurrent input than are other neurons in the network. For seed neurons, 𝜃𝑖 = 10 and for non-seed neurons, 𝜃𝑖 = 0. Including
this term improves robustness of the training procedure by eliminating occasional situations in which seed neuron activity may be dominated by recurrent rather than external inputs. In these cases, external inputs may fail to exert proper control of network activity.
Second, we determined whether the 𝑖th neuron will burst or not at time step
𝑡 by examining whether the net feedforward input, 𝐴𝑛𝑒𝑡
𝑖 (𝑡), exceeds the recurrent
inhibition, 𝐴𝐼𝑟𝑒𝑐(𝑡). We implemented recurrent inhibition by estimating the total input to the network at time 𝑡:
𝐴𝐼𝑟𝑒𝑐(𝑡) = 𝛾∑︁
𝑖
𝐴𝑛𝑒𝑡𝑖 (𝑡)
and feeding it back to all the neurons. Parameter 𝛾 sets the strength of the recurrent inhibition. We assume that this recurrent inhibition operates on a fast time scale [Kosche et al., 2015] (that is, faster than the duration of a burst). Thus, the final output of the 𝑖th neuron at time 𝑡 becomes:
𝑥𝑖(𝑡) = Θ[︀𝐴𝑛𝑒𝑡𝑖 (𝑡) − 𝐴 𝐼𝑟𝑒𝑐(𝑡)]︀
where Θ[𝑧] is the Heaviside step function (equal to 1 if 𝑧 > 0 and 0 otherwise). To induce splitting, 𝛾 was gradually stepped up to 𝛾𝑠𝑝𝑙𝑖𝑡 following a sigmoid with time
constant 𝜏𝛾 and inflection point 𝑡0:
𝛾(𝑡) = 𝛾𝑠𝑝𝑙𝑖𝑡
1 + 𝑒(𝑡−𝑡0)/𝜏𝛾
2.2.3
Seed neurons
A subset of neurons was designated as seed neurons, which received external training inputs used to shape network activity during learning [Jun and Jin, 2007, Buonomano, 2005]. The external training inputs activate seed neurons at syllable onsets, reflecting the observed onset-related bursts of HVC neurons during the subsong stage [Okubo et al., 2015]. The pattern of these inputs was adjusted in different stages of learning, and each strategy of syllable learning was implemented by different patterns of seed neuron training inputs.
Alternating differentiation (Figure 2-2 a-e)
Ten neurons were designated as seed neurons and received strong external input (𝑊𝑚𝑎𝑥) to drive network activity. In the subsong stage, seed neurons were driven
(by external inputs) synchronously and randomly with probability 0.1 in each time step corresponding to the random occurrence of syllable onsets in subsong[Aronov et al., 2008, Aronov et al., 2011]. This was done only to visualize network activity; no learning was implemented at the subsong stage. During the protosyllable stage, seed neurons were driven synchronously and rhythmically with a period 𝑇 = 100 ms. The protosyllable stage consisted of 500 iterations of 10 pulses each. To initiate chain splitting, the seed neurons were divided into two groups and each group was driven on alternate cycles. The splitting stage consisted of 2,000 iterations of 5 pulses in each group of seed neurons (1 s total per iteration, as in the protosyllable stage).
Motif strategy (Figure 2-3e-h)
This was implemented in a similar manner as alternating differentiation, except that 9 seed neurons were used, and for the splitting stage, seed neurons were divided into 3 groups of 3 neurons, each driven on every third cycle.
Bout-onset differentiation (Figure 2-3a-d)
Seed neurons were divided into two groups: 5 bout-onset seed neurons and 5 protosyl-lable seed neurons. At all learning stages, external inputs were organized into bouts consisting of four separate input pulses, and bout-onset seed neurons were driven at the beginning of each bout. Then, 30 ms later, protosyllable seed neurons were driven three times with an interval of 𝑇 = 100 ms. In the protosyllable stage, inputs to all seed neurons were of strength 𝑊𝑚𝑎𝑥. In the splitting stage, the input to
protosylla-ble seed neurons was decreased to 𝑊𝑚𝑎𝑥/10. This allowed neurons in the bout-onset
chain to suppress, through fast recurrent inhibition, the activity of protosyllable seed neurons during bout-onset syllables.
Each iteration of the simulation was 5 s long, consisting of 10 bouts, described directly above, with random inter-bout intervals. The protosyllable stage consisted of 100 iterations, and the splitting stage consisted of 500 iterations.
Bout-onset syllable formation (Figure 2-3i-k)
Input to seed neurons was set high (2.5 × 𝑊𝑚𝑎𝑥), and maintained at this high level
throughout development. This prevented protosyllable seed neurons from being in-hibited by neurons in the bout-onset chain. Furthermore, strong external input to the protosyllable seed neurons terminated activity in the bout-onset chain through fast recurrent inhibition, thus preventing further growth of the bout-onset chain, as occurs in bout-onset differentiation.
As in bout-onset differentiation, each iteration of the simulation was 5 s long, consisting of 10 bouts with random inter-bout intervals. The protosyllable stage consisted of 100 iterations, and the splitting stage consisted of 500 iterations.
2.2.4
Synaptic plasticity rules
As in previous models [Fiete et al., 2010, Jun and Jin, 2007], we hypothesized two plasticity rules in our model: Hebbian spike-timing dependent plasticity (STDP) to drive sequence formation [Abbott and Blum, 1991, Dan and Poo, 2006], and het-erosynaptic long term depression (hLTD) to introduce competition between synapses of a given neuron [Jun and Jin, 2007, Fiete et al., 2010]. STDP is governed by the antisymmetric plasticity rule with a short temporal window (one burst duration):
∆𝑆𝑇 𝐷𝑃𝑖𝑗 (𝑡) = 𝜂 [𝑥𝑖(𝑡)𝑥𝑗(𝑡 − 1) − 𝑥𝑖(𝑡 − 1)𝑥𝑗(𝑡)]
where the constant 𝜂 sets the learning rate. hLTD limits the total strength of weights for neuron 𝑖, and the summed weight limit rule for incoming weights is given by:
∆ℎ𝐿𝑇 𝐷𝑖· (𝑡) = 𝜂 [︃ ∑︁ 𝑘 (︀𝑊𝑖𝑘(𝑡 − 1) + ∆𝑆𝑇 𝐷𝑃𝑖𝑘 (𝑡))︀ − 𝑊𝑚𝑎𝑥 ]︃ +
and for outgoing weights from neuron 𝑗: ∆ℎ𝐿𝑇 𝐷·𝑗 (𝑡) = 𝜂 [︃ ∑︁ 𝑘 (︀𝑊𝑘𝑗(𝑡 − 1) + ∆𝑆𝑇 𝐷𝑃𝑘𝑗 (𝑡))︀ − 𝑊𝑚𝑎𝑥 ]︃ +
At each time step, total change in synapse weight is given by the combination of STDP and hLTD: ∆𝑊𝑖𝑗(𝑡) = ∆𝑆𝑇 𝐷𝑃𝑖𝑗 (𝑡) − 𝜖∆ ℎ𝐿𝑇 𝐷 𝑖· (𝑡) − 𝜖∆ ℎ𝐿𝑇 𝐷 ·𝑗 (𝑡)
where 𝜖 sets the relative strength of hLTD.
Model parameters: subsong (Figure 2-2a)
In our implementation of the subsong stage, there was no learning. Subsong model parameters were: 𝛽 = 0.115, 𝛼 = 30, 𝜂 = 0, 𝜖 = 0, 𝛾 = 0.01.
Model parameters: alternating differentiation (Figure 2-2b-d)
After subsong, learning progressed in two stages: the protosyllable stage and the splitting stage. Parameters that remained constant over development were: 𝛽 = 0.115, 𝛼 = 30, 𝜂 = 0.025, 𝜖 = 0.2. To induce chain splitting, 𝑤𝑚𝑎𝑥, the maximum
allowed strength of any synapse, was increased from 1 to 2, 𝑚 was decreased from 10 to 5, and 𝛾 was increased from 0.01 to 0.18 following a sigmoid with time constant 𝜏𝛾 = 200 iterations and inflection point 𝑡0 = 500 iterations into the splitting stage.
No change in parameters occurred before the chain-splitting stage. Model parameters: bout-onset differentiation (Figure 2-3a-d)
Parameters that remained constant over development were: 𝛽 = 0.13, 𝛼 = 30, 𝜂 = 0.05, 𝜖 = 0.14. To induce chain splitting, 𝑤𝑚𝑎𝑥 was increased from 1 to 2, 𝑚 was
decreased from 5 to 2.5, and 𝛾 was increased from 0.01 to 0.04 following a sigmoid with time constant 𝜏𝛾 = 200 iterations and inflection point 𝑡0 = 250 iterations into
the splitting stage.
Model parameters: motif strategy (Figure 2-3e-h)
Parameters that remained constant over development were: 𝛽 = 0.115, 𝛼 = 30, 𝜂 = 0.025, 𝜖 = 0.2. To induce chain splitting, 𝑤𝑚𝑎𝑥 was increased from 1 to 2, 𝑚 was
decreased from 9 to 3, and 𝛾 was increased from 0.01 to 0.18 following a sigmoid with time constant 𝜏𝛾 = 200 iterations and inflection point 𝑡0 = 500 iterations into the
splitting stage.
Model parameters: formation of a new syllable at bout onset (Figure 2-3i-k)
Parameters that remained constant over development were:𝛽 = 0.13, 𝛼 = 30, 𝜂 = 0.05, 𝜖 = 0.15. To induce chain splitting, 𝑤𝑚𝑎𝑥 was increased from 1 to 2, 𝑚 was
decreased from 5 to 2.5, and 𝛾 was increased from 0.01 to 0.05 following a sigmoid with time constant 𝜏𝛾 = 200 iterations and inflection point 𝑡0 = 250 iterations into
the splitting stage.
2.2.5
Shared and specific neurons
Neurons were classified as participating in a syllable type if the syllable onset-aligned histogram exhibited a peak that passed a threshold criterion. The criteria were chosen to include neurons where the histogram peak exceeded 90% of surrogate histogram peaks. Surrogate histograms were generated by placing one burst at a random la-tency in each syllable. (For example, in the protosyllable stage, the above criterion was found to be equivalent to having 5 bursts at the same latency in a bout of 10 protosyllables.) During the splitting phase, neurons were classified as shared if they participated in both syllable types, and specific if they participated in only one syl-lable type.
2.2.6
Visualizing network activity
We visualized network activity in two ways: network diagrams, and raster plots of population activity (for example, Figure 2-2a-d top and bottom panels, respectively). In both cases, we only included neurons that participated in at least one of the syllable types (see earlier Section 2.2.5 for participation criteria).
Network diagrams
Neurons are sorted along the 𝑥 axis based on their relative latencies. Neurons are sorted along the 𝑦 axis based on the relative strength of their synaptic input from specific neurons (or seed neurons) of each type (red or blue). Lines between neurons correspond to feedforward synaptic weights, and darker lines indicate stronger synap-tic weights. For clarity of plotting, only the strongest six outgoing and strongest nine incoming weights are plotted for each neuron.
Population raster plots
Neurons are sorted from top to bottom according to their latency. Groups of seed neurons are indicated by magenta arrows. Shared neurons are plotted at the top and specific neurons are plotted below. As for network diagrams, neurons that did not reliably participate in at least one syllable type were excluded.
Further details for Figure 2-2a-d
Panels show network diagrams and raster plots at four different stages. Figure 5a shows subsong stage (before learning),Figure 2-2b shows end of protosyllable stage (iteration 500), Figure 2-2c shows early chain splitting stage (iteration 992), Figure 2-2d shows late chain-splitting stage (iteration 2,500).
Further details for Figure 2-3a-d
Figure 2-3a shows early protosyllable stage (iteration 5), Figure 2-3b shows late pro-tosyllable stage (iteration 100), Figure 2-3c shows early chain splitting stage (iteration 130), Figure 2-3d shows late chain splitting stage (iteration 600).
2.2.7
Code availability
Code used to simulate the model is publicly available: https://github.com/emackev/HVCModelCode
2.2.8
Data availability
Datasets are publicly available through the CRCNS data sharing platform: https://crcns.org/data-sets/aa/am-3/about-am-3
2.3
Results
2.3.1
Initial model architecture
The model neurons are initially connected with random excitatory weights, repre-senting the subsong stage. We hypothesize that a subset of HVC neurons receives an external input at syllable onsets and serves as a seed from which chains grow during later learning stages [Jun and Jin, 2007, Buonomano, 2005]. Before learning, activa-tion of these seed neurons produced a transiently propagating sequence of network activity that decayed rapidly (within tens of milliseconds; Figure 2-2a).
2.3.2
Learning a protosequence through rhythmic activation
of seed neurons
In the next stage, the network is trained to produce a single protosyllable by activating seed neurons rhythmically (100 ms period). The connections are modified according to the learning rules described above [Jun and Jin, 2007, Fiete et al., 2010]. As a result, connections were strengthened along the population of neurons sequentially activated after syllable onsets, resulting in the growth of a feedforward synaptically connected chain that supported stable propagation of activity (Figure 2-2b).
2.3.3
Learning to split the protosequence
We found that this single chain could be induced to split into two daughter chains by dividing the seed neurons into two groups that were activated on alternate cycles of the rhythm (Figure 2-2c, d). Local inhibition [Kosche et al., 2015] and synaptic competition were also increased (see Methods). During the splitting process, we observed neurons specific to each of the emerging syllable types, as well as shared neurons that were active at the same latencies in both syllable types (Figure 2-2c). Just as observed in our data, over the course of development the distribution of burst latencies in the model continued to broaden (Figure 2-2e), and the fraction of shared neurons decreased (Figure 2-2c, d). The average period of rhythmic bursting in model
neurons increased during chain splitting as neurons became ‘specific’ for one emerging syllable type and began to participate only on alternate cycles of the protosyllable rhythm (Figure 2-2d and 2-3g, h).
2.3.4
Capturing a diverse set of learning strategies
Our model can reproduce other strategies by which birds learn new syllable types. We implemented bout-onset differentiation in the model by also including a population of seed neurons activated at bout onsets, as observed in [Okubo et al., 2015] (Figure 2-3a). This caused the protosyllable chain to split in such a way that one daughter chain was reliably activated only at bout onsets, while the other daughter chain was active only on subsequent syllables (Figure 2-3a-d). Our model was also able to simulate the simultaneous emergence of a three-syllable motif (‘motif strategy’) by dividing the seed neurons into three subpopulations (Figure 2-3e-h).
Our data and modelling support the possibility of syllable formation by mech-anisms other than sequence splitting. For example, in several birds, a short vocal element emerged at bout onsets that did not seem to differentiate acoustically from the protosyllable (and thus was not bout-onset differentiation). We found that, by us-ing different learnus-ing parameters, our model allows bout-onset seed neurons to induce the formation of a new syllable chain at bout onset, rather than inducing bout-onset differentiation (Figure 2-3i-k).
In summary, our model of learning in a simple sequence-generating network cap-tures transformations that underlie the formation of new syllable types via a diverse set of learning strategies.
2.4
Discussion
In our model, we envision that the formation of daughter chains in HVC is translated into the emergence of new syllable types as follows: During the splitting process, as two distinct sequences of specific neurons develop, their downstream projections can be independently modified [Leonardo and Fee, 2005, Fiete et al., 2004] such that each
Figure 2-3: Model of other strategies for syllable formation
a-d, Bout-onset differentiation results from activation of bout-onset seed neurons (blue arrow) fol-lowed by rhythmic activation of protosyllable seed neurons (red arrow). Network diagrams show (a, b) protosyllable formation and (c, d) splitting of chains specific for bout-onset syllable 𝛽 and specific for later repetitions of the protosyllable 𝛼 (blue and red, respectively; shared neurons: black). e-h, Model of simultaneous formation of multiple syllable types into an entire motif (‘motif strategy’). e, f, Protosyllable seed neurons (magenta lines) were activated rhythmically to form a protosequence. g, Seed neurons were then divided into three sequentially activated subgroups, resulting in the rapid splitting of the protosequence into three daughter sequences. In intermediate stages (panel g), in-dividual neurons exhibited varying degrees of specificity and sharedness for the emerging syllable types. h, After learning, the population of neurons was active sequentially throughout the entire ‘motif,’ but individual neurons were active during only one of the resulting syllables, forming three distinct non-overlapping sequences. i-k, Network diagrams and raster plots showing an example of the formation of a new syllable chain at bout onset. In the network diagrams, seed neurons are indicated within magenta boxes, and bout-onset seed neurons and protosyllable seed neurons are indicated by blue and red arrows, respectively. Neurons specific for each emerging syllable type (𝜖 and 𝛼) are coloured blue and red, respectively. The three panels represent the early protosyllable stage, the late protosyllable stage, and the final stage. The training protocol is similar to that for bout-onset differentiation (panels a-d), except that protosyllable seed neurons are driven more strongly throughout the learning process. As a result, protosyllable seed neurons did not become outcompeted by the growing bout-onset chain. Strong activation of the protosyllable seed neurons also terminated activity in the bout-onset chain through fast recurrent inhibition, thus preventing further growth of the bout-onset chain, as occurs in bout-onset differentiation.
of the emerging chains of specific neurons can drive a distinct pattern of downstream motor commands, allowing distinct acoustic structure in the emerging syllable types. Such differential acoustic refinement is consistent with the previous behavioural obser-vation that the altered acoustic structure of new syllables emerges in place, without moving or reordering sound components (‘sound differentiation in situ’) [Tcherni-chovski et al., 2001]. This model naturally explains the apparent ‘decoupling’ of shared projection neuron bursts from acoustic structure in the vocal output—that is, the fact that the bursts of shared neurons become associated with two distinct acoustic outputs during the differentiation of two syllable types. Specifically, during syllable differentiation, a shared neuron participates with different ensembles of neu-rons during each of the emerging sequences, and these different ensembles can drive different vocal outputs.
The process of splitting a prototype neural sequence allows learned components of a prototype motor program to be reused in each of the daughter motor programs. For example, one of the earliest aspects of vocal learning is the coordination between singing and breathing [Veit et al., 2011], specifically, the alternation between vocalized expiration and non-vocalized inspiration typical of adult song [Goller and Cooper, 2004]. The protosequence in HVC would allow the bird to learn the appropriate coordination of respiratory and vocal musculature. Duplication of the protosequence through splitting would result in two ‘functional’ daughter sequences, each already capable of proper vocal/respiratory coordination, and each suitable as a substrate for rapid learning of a new syllable type.
This proposed mechanism resembles a process thought to underlie the evolution of novel gene functions: gene duplication followed by divergence through indepen-dent mutations [Ohno, 1970]. Similarly, for the acquisition of complex behaviours, the duplication of neural sequences by splitting, followed by independent differenti-ation through learning, may provide a mechanism for constructing complex motor programs.
Chapter 3
A sensorimotor signal that may play a
role in building a new motor program
Abstract
How are complex sequences of behavior learned? Are they broken down into simpler pieces? How are behavioral goals represented, and translated into the actions that produce those goals? Songbirds learn to imitate the songs of tutors they heard as juve-niles. Juvenile song starts off as unstructured babbling, then becomes more structured with the introduction of a stereotyped ‘protosyllable’. New syllables emerge through the differentiation of this protosyllable into multiple syllable types, until the song crystalizes into an adult song composed of 3-7 distinct syllables. Here we describe the activity of neurons recorded in nucleus interface (NIf), a cortical region at the interface between the auditory and motor systems. During juvenile babbling, NIf neurons burst at or just before the onsets of syllables. As the song matures, some NIf neurons are selective for particular emerging syllable types. These signals are consistent with a model in which NIf seeds and splits developing premotor sequences. Furthermore, NIf neurons fire at the onsets of particular syllable types when juveniles are listening to their tutor song, which may influence the number of syllables that the bird eventually develops. By aligning to syllable onsets, NIf could ‘chunk’ songs into syllables each of which is accessible as a discrete unit in both auditory and motor representations. Our findings suggest a simple mechanism by which learning in one domain (listening to a tutor) could be transferred to support learning in a different domain (singing).
3.1
Introduction
Unlike motor programs for innate behaviors, which are built by genetically-specified developmental sequences, motor programs for complex learned behaviors must be built by a combination of genes and experience. Many of our most complex and expressive behavioral repertoires, from speech to music to cooking to sports, are learned through observing others, and through practice of simpler elements. Such behavioral elements, or movement chunks, can be flexibly composed in the brain to produce complex motor sequences [Graybiel, 1998, Nachev et al., 2008, Smith and Graybiel, 2014]. This powerful strategy for generating new behaviors supports the creation of an expressive variety of actions, even from relatively few primitive building blocks. We were interested in how the brain makes building blocks for a new behavioral repertoire.
Given our desire to address this question in a complex yet reproducible learning process where potential neural mechanisms are relatively constrained, we choose to examine avian song imitation. Songbirds learn their vocalizations by imitating songs of tutors they heard as juveniles. They learn in two stages: a sensory stage where they memorize the tutor song, and a sensorimotor stage where they practice vocalizing [Tchernichovski et al., 2001, Zann, 1996]. These stages are typically overlapping, but not necessarily—the memory of the tutor song, called the song template, is sufficient to guide imitation [Zann, 1996], even if restricted to a single 2-hour window of tutor exposure consisting of a cumulative total of 75 seconds of tutor song [Deshpande et al., 2014].
Song learning exhibits convergent behavioral, circuit-level and genetic parallels with human speech learning [Doupe and Kuhl, 1999, Petkov and Jarvis, 2012, Teramitsu et al., 2004, White, 2001, Dugas-Ford et al., 2012, Pfenning et al., 2014, Jarvis et al., 2005, Karten, 1991, Karten, 2013, Reiner et al., 2004, Wang et al., 2010], and also has parallels with other forms of mammalian motor learning [Fee and Goldberg, 2011]. While song learning involves imitating a tutor, it is also strongly shaped by other forces such as species-specific or individual preferences [Tchernichovski and Marcus,
2014]. Similarly, human behaviors that involve some imitation also tend to involve exploration and individual goals beyond simple imitation [Gweon et al., 2014, Shnei-dman et al., 2016]. Like other complex motor behaviors such as speech, songs are divided into discrete simpler chunks, syllables [Cynx, 1990]. After initial random babbling, a repeatable protosyllable emerges, which then differentiates into multi-ple daughter syllables [Tchernichovski et al., 2001]. As the song matures, syllables undergo a process of gradual refinement.
The neural mechanisms of adult song production and refinement are fairly well understood, and rely, like mammalian motor learning, on a network of cortical, basal ganglia and thalamic brain areas [Fee and Goldberg, 2011, Jarvis et al., 2005, Reiner et al., 2004]. Together, this network of brain areas is thought to execute precisely timed song syllables [Vu et al., 1994, Yu and Margoliash, 1996, Fee et al., 2004, Srivastava et al., 2017, Hahnloser et al., 2002, Long and Fee, 2008, Long et al., 2010, Picardo et al., 2016, Lynch et al., 2016]; explore new song variations [Kao and Brainard, 2006, Ölveczky et al., 2005, Ölveczky et al., 2011, Stepanek and Doupe, 2010]; evaluate which variations sound good [Keller and Hahnloser, 2009, Mandelblat-Cerf et al., 2014, Gadagkar et al., 2016]; and employ reinforcement learning to bias future song towards variants that sound better [Andalman and Fee, 2009, Warren et al., 2011, Tesileanu et al., 2017].
What neural signals might help build the sequences that precisely control adult song syllables? Song timing is thought to be controlled by HVC [Vu et al., 1994, Yu and Margoliash, 1996, Hahnloser et al., 2002, Long and Fee, 2008], where neurons burst in precisely timed sequences that span all moments of the song [Picardo et al., 2016, Lynch et al., 2016]. These precise sequences appear to emerge gradually over development, first with the growth of protosequences from syllable onsets, then the splitting of protosequences into daughter sequences [Okubo et al., 2015]. Several existing computational models of HVC development rely on a population of syllable-onset-related training neurons that seed developing chains in HVC [Bertram et al., 2014, Gibb et al., 2009b, Jun and Jin, 2007, Okubo et al., 2015]. Here, we identify a candidate source of such training inputs in Nucleus Interface (NIf), a higher-order
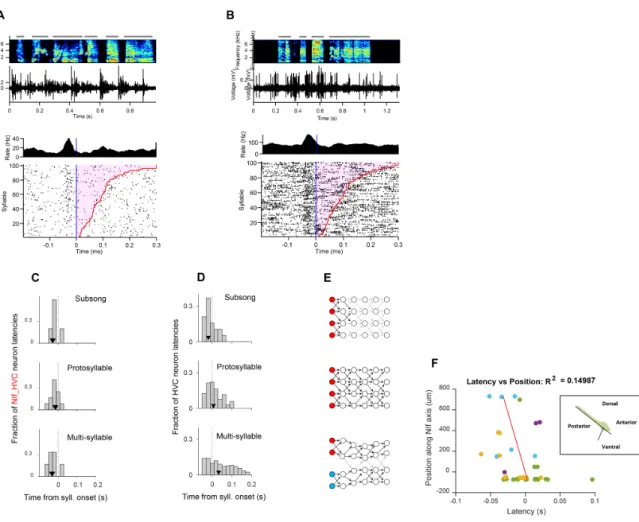
Figure 3-1: Recording at the interface between sensory and motor cortical circuits in juvenile birds during song learning
(A) Schematic showing the ascending auditory pathway and descending motor pathway in the song-bird. Like association cortex in mammals, NIf is densely connected with both sensory and motor areas. (B) Schematic of the songbird brain showing interconnected sensory and motor nuclei. A motorized microdrive was implanted with electrodes in Nucleus Interface (NIf), to enable recordings in freely behaving birds. In addition, a stimulating electrode was implanted in the premotor cortical nucleus HVC to antidromically identify NIf_HVC neurons.
sensorimotor cortical area that projects to HVC and has been implicated in song learning.
NIf is widely recognized as a potential node of interaction between the auditory and motor systems [Akutagawa and Konishi, 2010, Bauer et al., 2008, Cardin and Schmidt, 2004a, Cardin and Schmidt, 2004b, Lewandowski et al., 2013]. Like mam-malian association cortex, NIf is a higher-order cortical area that has bidirectional connections with both auditory and motor areas (Figure 3-1A). Specifically, it has been suggested that NIf is analogous to Spt, a region in the human speech process-ing circuit located at the interface of auditory and motor functions [Hickok et al., 2003, Lewandowski et al., 2013].
NIf appears to play a primary role during vocal development: lesions of NIf have minimal effect on adult zebra finch song [Otchy et al., 2015], but inactivation of NIf in young juvenile birds causes loss of emerging spectral and temporal song structure [Naie and Hahnloser, 2011]. Furthermore, inactivating NIf while a juvenile bird is being tutored interferes with tutor imitation [Roberts et al., 2012].