Collaborative Data Publishing and Searching System
Texte intégral
Figure

Documents relatifs
The IMCCE Virtual Observatory solar system portal (http://vo.imcce.fr/) aims to provide to the astronomical community all the knowledge and the expertise of the IMCCE which concern
Analysis of ULP signals accompanied by VLP signals recorded by a nearby broadband seismic station can thus provide important constraints on the timing of the 2007 Piton de la
The experimentation presented in the following sections showed that increasing Hertzian contact pressure past the fully plastic limit of the groove material improved
Therefore, to prove that a given valid transfer plan φ is Γ-robust, one can show that for all datum units k ∈ D, and all recipient nodes r ∈ R, the minimum number of contacts which
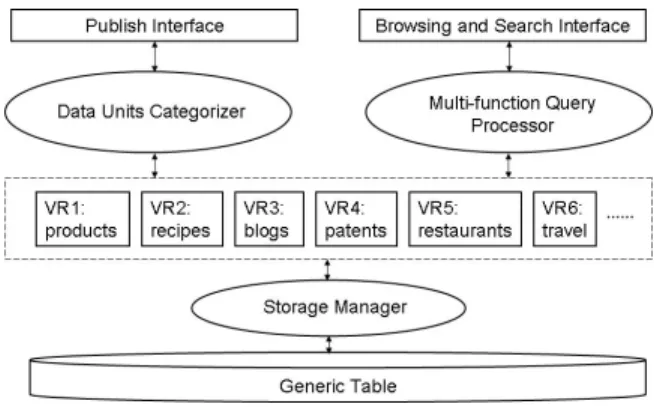
In fact, there is also one reference data model, but this one is generic enough to allow any mapping of the different concepts that come from the different
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Within the framework of the current level of IT monitoring system development, the data volume in MCC JSC Russian Railways is 11 terabytes, and this value
The collection and processing system of the medical data based on cloud computing, IoT in medicine and anticipation system for the dete- rioration of the patient's state on the
