Enhancing the Reproducibility of Group Analysis with Randomized Brain Parcellations
Texte intégral
Figure
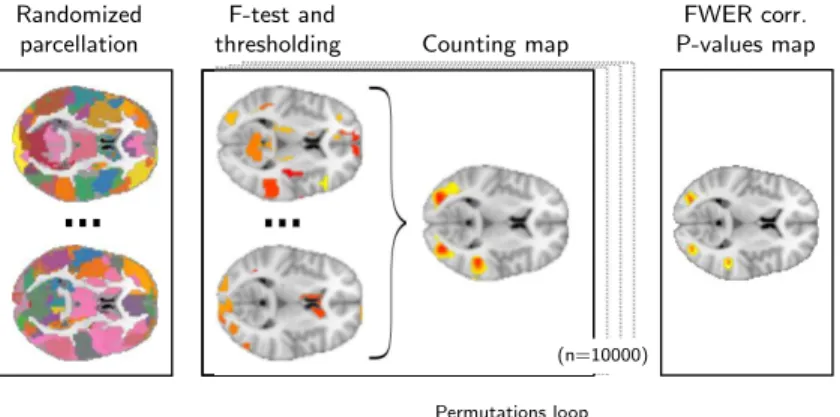

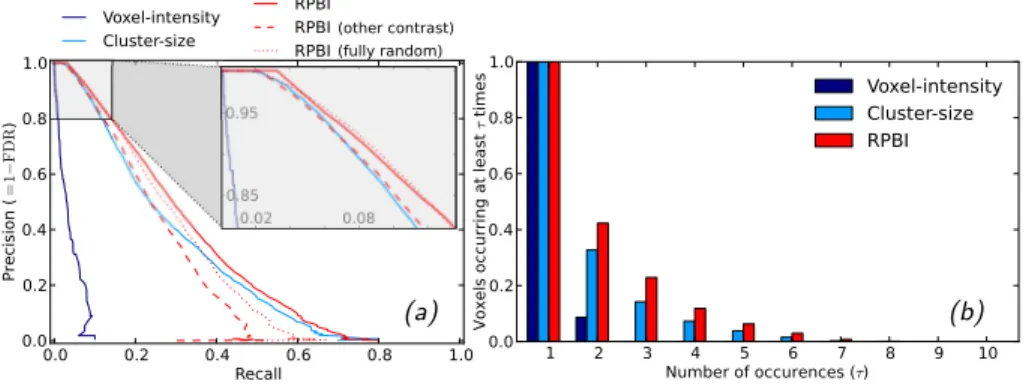
Documents relatifs
Finally, the spatial and spectral residuals for the unbinned maximum likelihood fit of the curved power law spectrum are displayed in Fig. Spectral residuals for nine sub-sectors
Thus, anyone wishing to use EM correlations (or covariances) as matrix input for the FACTOR or RELIABILITY procedures has some preliminary work to do: They
We used the simulated data of Genetic Analysis Workshop 15 (Problem 3, answer known) to assess the power of the phylogeny-based analysis to detect disease susceptibility loci
In Appendix C, we report further simulation results, where we vary the features dimension (p “ 50), the rank (r “ 5), the missing values mechanism using probit self-masking and
(8) As a consequence of the size effect on strength and deformation, and the influence of boundary rota- tions it is impossible to choose the ‘best’ or ‘most appropriate’ type
Table 1 contains the results from the statistical analy- sis of pre- and post-depletion glycogen levels and the rates of glycogen synthesis following ingestion
Les dernières variables qualitatives utilisées étaient le niveau d’information des étudiants concernant : les possibilités de développement professionnel permises
In addition, the implicit methods (b), in green in Figure 2, working on the concatenation of the mask and the data, either based on a binomial modeling of the mechanism (mimi,
