A profile-based Big data architecture for agricultural context
Texte intégral
Figure
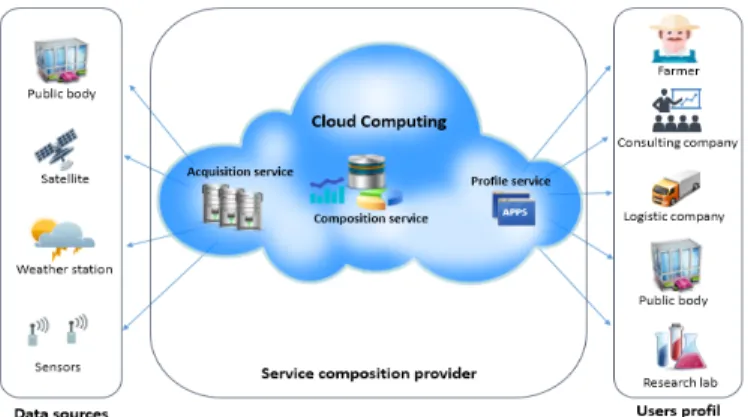
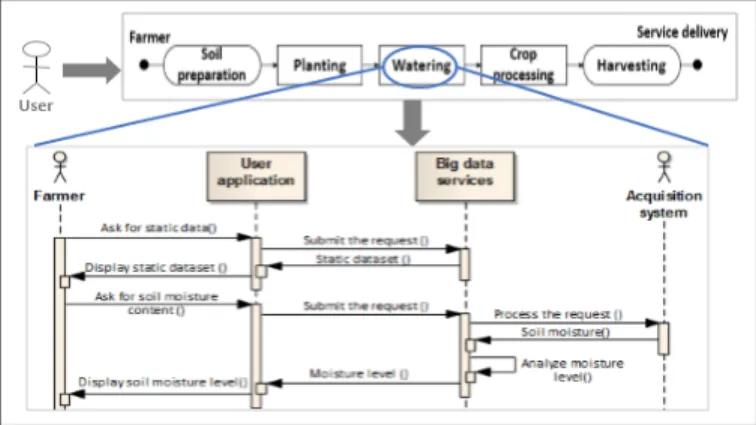

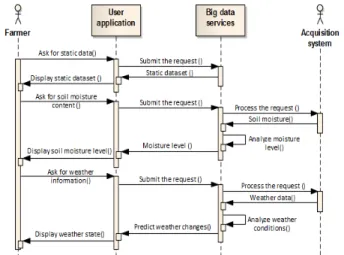
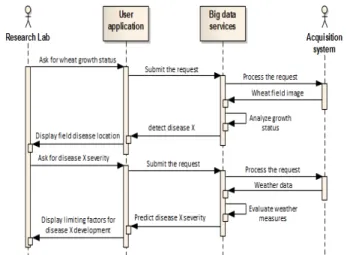
Documents relatifs
The author points out how other characteristics have defied this affirmation in narrative plots in order to reaffirm the personal identity of its main
Two months later sitting on the street at night she was begging for money with her boyfriend I gave them five dollars. but they didn’t recognize me or thank me for the money which
We also would refer readers to clinical practice guidelines developed by the Canadian Cardiovascular Society, the American College of Chest Physicians, and the European Society of
Nous avons obtenu un niveau exemplaire dans notre démarche de management de l’éco-conception labellisée par l’Afnor certification sur l’ensemble du groupe MEDIA6...
We can increase the flux by adding a series of fins, but there is an optimum length L m for fins depending on their thickness e and the heat transfer coefficient h. L m ~ (e
Cain & Sheppard (1954) The theory of adaptive polymorphism. "This interesting theory may be correct, but it is not clear what is meant by one population being more
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in
ERRATUM ON “ENTROPY-ENERGY INEQUALITIES AND IMPROVED CONVERGENCE RATES FOR NONLINEAR..
