Lyapunov Exponents of Random Walks in Small Random Potential: The Lower Bound
50
0
0
Texte intégral
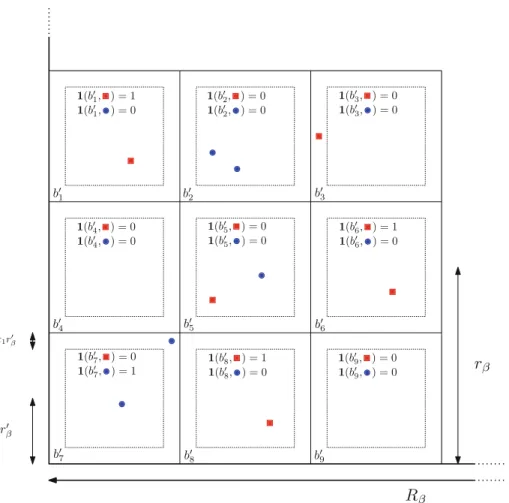
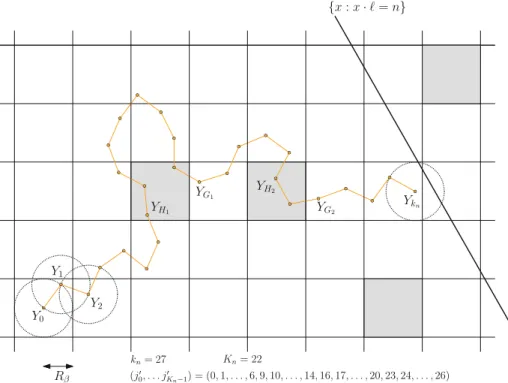
Figure

Documents relatifs
