Directoryless Shared Memory Architecture using
Thread Migration and Remote Access
by
Keun Sup Shim
Bachelor of Science, Electrical Engineering and Computer Science,
KAIST, 2006
Master of Science, Electrical Engineering and Computer Science,
Massachusetts Institute of Technology, 2010
Submitted to the Department of Electrical Engineering and Computer
Science
A60{NEq
in partial fulfillment of the requirements for the degree of
MASSACHUSETTS INS OF TECHNOLOGYDoctor of Philosophy
JUN
2
rT0 E1at the
L
RARIES
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
June 2014
@
Massachusetts Institute of Technology 2014. All rights reserved.
Signature redacted
A u th or ...
Department of Electrical Engineering and Computer Science
g
(.VIay 11, 2014
Certified by...Signature
redacted
Srinivas Devadas
Edwin Sibley Webster Professor
Thesis
Supervisor
Signature redacted_
Accepted by...
r d c e
/eslie
/A. olodziejski
Chair, Department Committee on Graduate Students
Directoryless Shared Memory Architecture using
Thread Migration and Remote Access
by
Keun Sup Shim
Submitted to the Department of Electrical Engineering and Computer Science on May 14, 2014, in partial fulfillment of the
requirements for the degree of Doctor of Philosophy
Abstract
Chip multiprocessors (CMPs) have become mainstream in recent years, and, for scalability reasons, high-core-count designs tend towards tiled CMPs with physically distributed caches. In order to support shared memory, current many-core CMPs maintain cache coherence using distributed directory protocols, which are extremely difficult and error-prone to implement and verify. Private caches with directory-based coherence also provide suboptimal performance when a thread accesses large amounts of data distributed across the chip: the data must be brought to the core where the thread is running, incurring delays and energy costs. Under this scenario, migrating a thread to data instead of the other way around can improve performance.
In this thesis, we propose a directoryless approach where data can be accessed either via a round-trip remote access protocol or by migrating a thread to where data resides. While our hardware mechanism for fine-grained thread migration enables faster migration than previous proposals, its costs still make it crucial to use thread migrations judiciously for the performance of our proposed architecture. We, therefore, present an on-line algorithm which decides at the instruction level whether to perform a remote access or a thread migration. In addition, to further reduce migration costs, we extend our scheme to support partial context migration by predicting the necessary
thread context. Finally, we provide the ASIC implementation details as well as RTL simulation results of the Execution Migration Machine (EM2
), a 110-core directoryless shared-memory processor.
Thesis Supervisor: Srinivas Devadas Title: Edwin Sibley Webster Professor
Acknowledgments
First and foremost, I would like to express my deepest gratitude to my advisor, Professor Srinivas Devadas, who has offered me full support and has been a tremendous mentor throughout my Ph.D. years. I feel very fortunate to have had the opportunity to work with him and learn from him. His energy and insight will continue to inspire me throughout my career.
I would also like to thank my committee members Professor Arvind and Professor Daniel Sanchez. They both provided me with invaluable feedback and advice that helped me to develop my thesis more thoroughly. I am especially grateful to Arvind for being accessible as a counselor as well, and to Daniel for always being an inspiration to me for his passion in this field. I truly thank another mentor of mine, Professor Joel Emer. From Joel, I learned not only about the core concepts of computer architecture but also about teaching. I feel very privileged for having been a teaching assistant for his class.
While I appreciate all of my fellow students in the Computation Structures Group at MIT, I want to express special thanks to Mieszko Lis and Myong Hyon Cho. We were great collaborators on the EM2 tapeout project, and at the same time, awesome friends during our doctoral years. It was a great pleasure for me to work with such talented and fun people.
Getting through my dissertation required more than academic support. Words cannot express my gratitude and appreciation to my friends from Seoul Science High School and KAIST at MIT. I am also grateful to my friends at Boston Onnuri Church for their prayers and encouragement. I would also like to extend my deep gratitude to
Samsung Scholarship for supporting me financially during my doctoral study.
My fianc6e Song-Hee deserves my special thanks for her love and care. She has believed in me more than I did myself and her consistent support has always kept me energized and made me feel that I am never alone. I cannot thank my parents and family enough; they have always believed in me, and have been behind me throughout my entire life. Lastly, I thank God, for offering me so many opportunities in my life
Contents
1 Introduction 17
1.1 Large-Scale Chip Multiprocessors . . . . 17
1.2 Shared Memory for Large-Scale CMPs . . . . 18
1.3 Motivation for Fine-grained Thread Migration . . . . 19
1.4 Motivation for Directoryless Architecture . . . . 21
1.5 Previous Works on Thread Migration . . . . 22
1.6 Contributions . . . . 23
2 Directoryless Architecture 27 2.1 Introduction . . . . 27
2.2 Remote Cache Access . . . . 28
2.3 Hardware-level Thread Migration . . . . 29
2.4 Performance Overhead of Thread Migration . . . . 30
2.5 Hybrid Memory Access Framework . . . . 31
3 Thread Migration Prediction 33 3.1 Introduction . . . . 33
3.2 Thread Migration Predictor . . . . 33
3.2.1 Per-core Thread Migration Predictor . . . . 33
3.2.2 Detecting Migratory Instructions: WHEN to migrate . . . . . 35
3.2.3 Possible Thrashing in the Migration Predictor . . . . 38
3.3 Experim ental Setup . . . . 39
3.3.2 Evaluated Systems . . . . 42
3.4 Simulation Results . . . . 42
3.4.1 Perform ance . . . . 42
3.5 Chapter Summary . . . .. 44
4 Partial Context Migration for General Register File Architecture 47 4.1 Introduction . . . . 47
4.2 Partial Context Thread Migration . . . . 48
4.2.1 Extending Migration Predictor . . . . 48
4.2.2 Detection of Useful Registers: WHAT to migrate . . . . 49
4.2.3 Partial Context Migration Policy . . . . 51
4.2.4 Misprediction handling . . . . 53
4.3 Experimental Setup . . . . 53
4.3.1 Evaluated Systems . . . . 54
4.4 Simulation Results . . . . 54
4.4.1 Performance and Network Traffic . . . . 54
4.4.2 The Effects of Network Parameters . . . . 57
4.5 Chapter Summary . . . . 58
5 The EM' silicon implementation 61 5.1 Introduction . . . . 61
5.2 EM 2 Processor . . . . 62
5.2.1 System architecture . . . . 62
5.2.2 Tile architecture . . . . 64
5.2.3 Stack-based core architecture . . . . 64
5.2.4 Thread migration implementation . . . . 65
5.2.5 The instruction set . . . . 67
5.2.6 System configuration and bootstrap . . . . 69
5.2.7 Virtual memory and OS implications . . . . 70
5.3 Migration Predictor for EM2 . . . . . . . . . . . . . . . . . . . . . . . 70
5.3.2 Partial Context Migration Policy 5.3.3 Implementation Details . . . . . 5.4 Physical Design of the EM2 Processor . 5.4.1 Overview . . . . 5.4.2 Tile-level . . . . 5.4.3 Chip-level . . . . 5.5 Evaluation Methods . . . .
5.5.1 RTL simulation . . . . 5.5.2 Area and power estimates . . . 5.6 Evaluation . . . . 5.6.1 Performance tradeoff factors . . 5.6.2 Benchmark performance . . . . 5.6.3 Area and power costs . . . . 5.6.4 Verification Complexity . . . . 5.7 Chapter Summary . . . .
6 Conclusions
6.1 Thesis contributions . . . . 6.2 Architectural assumptions and their implications . . . . 6.3 Future avenues of research . . . .
Bibliography
A Source-level Read-only Data Replication
97 97 98 100 101 107 73 . . . . 7 4 . . . . 7 6 . . . . 7 6 . . . . 7 6 . . . . 7 8 . . . . 7 9 . . . . 7 9 . . . . 8 1 . . . . 8 2 . . . . 8 2 . . . . 8 4 . . . . 9 1 . . . . 9 2 . . . . 9 4
List of Figures
1-1 Rationale of moving computation instead of data . . . . 20
2-1 Hardware-level thread migration via the on-chip interconnect . . . . . 31 2-2 Hybrid memory access framework for our directoryless architecture . 32
3-1 Hybrid memory access architecture with a thread migration predictor on a 5-stage pipeline core. . . . . 34 3-2 An example of how instructions (or PC's) that are followed by
consecu-tive accesses to the same home location (i.e., migratory instructions) are detected in the case of the depth threshold
0
= 2. . . . . 363-3 An example of how the decision between remote access and thread migration is made for every memory access. . . . . 38 3-4 Parallel K-fold cross-validation using perceptron . . . . 40 3-5 Core miss rate and its breakdown into remote access rate and migration
rate . . . . 4 3
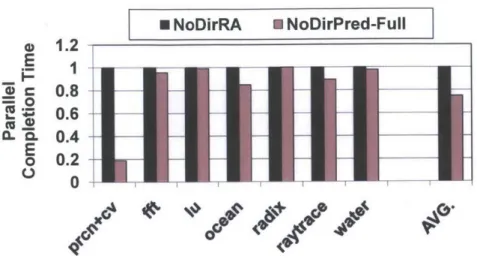
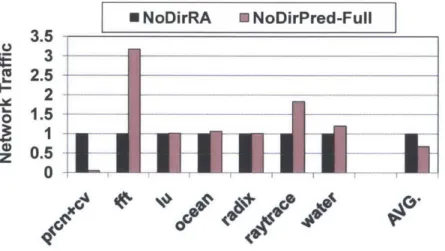
3-6 Parallel completion time normalized to the remote-access-only architec-ture (N oDirRA ) . . . . 44 3-7 Network traffic normalized to the remote-access-only architecture (NoDirRA) 45
4-1 Hardware-level thread migration with partial context migration support 48 4-2 A per-core PC-based migration predictor, where each entry contains a
4-3 An example how registers being read/written are kept track of and how the information is inserted into the migration predictor when a specific instruction (or PC) is detected as a migratory instruction (the depth
threshold 0 = 2). . . . . 50
4-4 An example of a partial context thread migration. . . . . 52
4-5 Parallel completion time normalized to DirCC . . . . 55
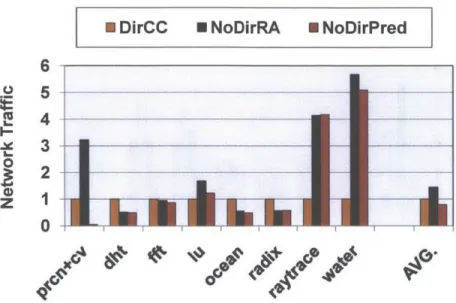
4-6 Network traffic normalized to DirCC . . . . 56
4-7 Breakdown of Li miss rate . . . . 57
4-8 Core miss rate for directoryless systems . . . . 58
4-9 Network traffic breakdown . . . . 59
4-10 Breakdown of migrated context into used and unused registers . . . . 60
4-11 The effect of network latency and bandwidth on performance and network traffic . . . . 60
5-1 Chip-level layout of the 110-core EM2 chip . . . . 62
5-2 EM2 Tile Architecture . . . . 63
5-3 The stack-based processor core diagram of EM2 . . . .. 64
5-4 Hardware-level thread migration via the on-chip interconnect under EM2. Only the main stack is shown for simplicity. . . . . 66
5-5 The two-stage scan chain used to configure the EM2 chip . . . . 69
5-6 Integration of a PC-based migration predictor into a stack-based, two-stage pipelined core of EM2 . . . . . . . . . . . . . . . . . . . 71
5-7 Decision/Learning mechanism of the migration predictor . . . . 73
5-8 EM 2 Tile Layout . . . . 77
5-9 Die photo of the 110-core EM2 chip . . . . 79
5-10 Thread migration (EM2) vs Remote access (RA) . . . . 82
5-11 Thread migration (EM2) vs Private caching (CC) . . . . 83
5-12 The effect of distance on RA, CC and EM2 . . . .. 84
5-13 The evaluation of EM2 . . . .. 85
5-15 Performance and network traffic with different number of threads for
tbscan under EM2 . . . .. 88
5-16 N instructions before being evicted from a guest context under EM2 . 8 8
5-17 EM2 allows efficient bulk loads from a remote core. . . . . 90 5-18 Relative area and leakage power costs of EM2 vs. estimates for
exact-sharer CC with the directory sized to 100% and 50% of the D$ entries
(DC Ultra, IBM 45nm SOI hvt library, 800MHz). . . . . 92 5-19 Bottom-up verification methodology of EM2 . . . . . . .. . . . . 93
List of Tables
3.1 System configurations used . . . . 39
5.1 Interface ports of the migration predictor in EM2 .
. . . .. 75 5.2 Power estimates of the EM2 tile (reported by Design Compiler) . . . 78 5.3 A summary of architectural costs that differ in the EM2 and CC
implemen-tation s. . . . . 9 1
Chapter 1
Introduction
1.1
Large-Scale Chip Multiprocessors
For the past decades, CMOS scaling has been a driving force of computer performance improvements. The number of transistors on a single chip has doubled roughly every 18 months (known as Moore's law [44]), and along with Dennard scaling [21], we could improve the processor performance without hitting the power wall [21]. Starting from the mid-2000's, however, supply voltage scaling has stopped due to higher leakage, and power limits have halted the drive to higher core frequencies.
Unlike the end of Dennard scaling, transistor density has continued to grow [25]. As increasing instruction-level parallelism (ILP) of a single-core processor became less efficient, computer architects have turned to multicore architectures rather than more complex uniprocessor architectures to better utilize the available transistors for overall performance. And since 2005 when we have had dual-core processors in the market, Chip Multiprocessors (CMPs) with more than one core on a single chip have already become common in the commodity and general-purpose processor markets [50,56].
To further improve performance, architects are now resorting to medium and large-scale multicores. In addition to multiprocessor projects in academia (e.g., RAW [58], TRIPS [52]), Intel demonstrated its 80-tile TeraFLOPS research chip in 65-nm CMOS in 2008 [57], followed by the 48-core SCC processor in 45-nm technology, the second processor in the TeraScale Research program [31]. In 2012, Intel introduced its first
Many Integrated Core (MIC) product which has over 60 cores to the market as the Intel Xeon Phi family [29], and it has recently announced a 72-core x86 Knights Landing
CPU [30]. Tilera Corporation has shipped its first multiprocessor, TILE64 [7, 59],
which connects 64 tiles with 2-D mesh networks, in 2007; the company has further announced TILE-Gx72 which implements 72 power-efficient processor cores and is suited for many compute and I/O-intensive applications [17]. Adapteva also announced its 64-core 28-nm microprocessor based on its Epiphany architecture which supports shared memory and uses a 2D mesh network [48].
As seen by many examples, processor manufacturers are already able to place tens and hundreds of cores on a single chip, and industry pundits are predicting 1000 or more cores in a few years [2,8,61].
1.2
Shared Memory for Large-Scale CMPs
For manycore CMPs, each core typically has per-core Li and L2 caches since power requirements of caches grow quadratically with size; therefore, the only practical option to implement a large on-chip cache is to physically distribute cache on the chip so that every core is near some portion of the cache [7,29]. And since conventional bus and crossbar interconnects no longer scale due to the bandwidth and area limitations [45,46], these cores are often connected via an on-chip interconnect, forming a tiled architecture
(e.g., Raw [58], TRIPS [52], Tilera [7], Intel TeraFLOPS [57], Adapteva [48]).
How will these manycore chips be programmed? Programming convenience pro-vided by the shared memory abstraction has made it the most popular paradigm for
general-purpose parallel programming. While architectures with restricted memory models (most notably GPUs) have enjoyed immense success in specific applications (such as rendering graphics), most programmers prefer a shared memory model [55], and commercial general-purpose multicores have supported this abstraction in hard-ware. The main question, then, is how to efficiently provide coherent shared memory
on the scale of hundreds or thousands of cores.
traditionally implemented by bus-based snooping or a centralized directory for CMPs with relatively few cores. For large-scale CMPs where bus-based mechanisms fail, however, snooping and centralized directories are no longer viable, and such many-core systems commonly provide cache coherence via distributed directory protocols. A logically central but physically distributed directory coordinates sharing among the per-core caches, and each core cache must negotiate shared (read-only) or exclusive (read/write) access to each cache line via a coherence protocol. The use of directories poses its own challenges, however. Coherence traffic can be significant, which increases interconnect power, delay, and congestion; the performance of applications can suffer due to long latency between directories and requestors especially, for shared read/write data; finally, directory sizes must equal a significant portion of the combined size of the per-core caches, as otherwise directory evictions will limit performance [27]. Although some recent works propose more scalable directories or coherence protocols in terms of area and performance [16,18, 20,24,51], the scalability of directories to a large number of cores still remains an arguably critical challenge due to the design complexity, area overheads, etc.
1.3
Motivation for Fine-grained Thread Migration
Under tiled CMPs, each core has its own cache slice and the last-level cache can be implemented either as private or shared; while the trade-offs between the two have been actively explored [12,62], many recent works have organized physically distributed L2 cache slices to form one logically shared L2 cache, naturally leading to a Non-Uniform Cache Access (NUCA) architecture [4,6,13,15,28,33,36]. And when large data structures that do not fit in a single cache are shared by multiple threads or iteratively accessed even by a single thread, the data are typically distributed across these multiple shared cache slices to minimize expensive off-chip accesses. This raises the need for a thread to access data mapped at remote caches often with high spatio-temporal locality, which is prevalent in many applications; for example, a database request might result in a series of phases, each consisting of many accesses
to contiguous stretches of data.
Chunk 1 Chunk 4Chunk3Chk4
(a) Directory-based / RA-only (b) Thread migration
Figure 1-1: Rationale of moving computation instead of data
In a manycore architecture without efficient thread migration, this pattern results in large amounts of on-chip network traffic. Each request will typically run in a separate thread, pinned to a single core throughout its execution. Because this thread might access data cached in last-level cache slices located in different tiles, the data must be brought to the core where the thread is running. For example, in a
directory-based architecture, the data would be brought to the core's private cache, only to be replaced when the next phase of the request accesses a different segment of data (see Figure 1-1a).
If threads can be efficiently migrated across the chip, however, the on-chip data movement-and with it, energy use-can be significantly reduced; instead of trans-ferring data to feed the computing thread, the thread itself can migrate to follow the data. When applications exhibit data access locality, efficient thread migration can turn many round-trips to retrieve data into a series of migrations followed by long stretches of accesses to locally cached data (see Figure 1-1b). And if the thread context is small compared to the data that would otherwise be transferred, moving the thread can be a huge win. Migration latency also needs to be kept reasonably low, and we argue that these requirements call for a simple, efficient hardware-level implementation of thread migration at the architecture level.
1.4
Motivation for Directoryless Architecture
As described in Chapter 1.2, private Li caches need to maintain cache coherence to support shared memory, which is commonly done via distributed directory-based protocols in modern large-scale CMPs. One barrier to distributed directory coherence protocols, however, is that they are extremely difficult to implement and verify [35]. The design of even a simple coherence protocol is not trivial; under a coherence protocol, the response to a given request is determined by the state of all actors in the system, transient states due to indirections (e.g., cache line invalidation), and transient states due to the nondeterminism inherent in the relative timing of events. Since the state space explodes exponentially as the distributed directories and the number of cores grow, it is virtually impossible to cover all scenarios during verification either
by simulation or by formal methods [63]. Unfortunately, verifying small subsystems
does not guarantee the correctness of the entire system [3]. In modern CMPs, errors in cache coherence are one of the leading bug sources in the post-silicon debugging phase [22].
A straightforward approach to removing directories while maintaining cache
co-herence is to disallow cache line replication across on-chip caches (even Li caches) and use remote word-level access to load and store remotely cached data [23]: in this scheme, every access to an address cached on a remote core becomes a two-message round trip. Since only one copy is ever cached, coherence is trivially ensured. Such a remote-access-only architecture, however, is still susceptible to data access patterns as shown in Figure 1-la; each request to non-local data would result in a request-response pair sent across the on-chip interconnect, incurring significant network traffic and performance degradation.
As a new design point, therefore, we propose a directoryless architecture which better exploits data locality by using fine-grained hardware-level thread migration to complement remote accesses [14,41]. In this approach, accesses to data cached at a remote core can also cause the thread to migrate to that core and continue execution there. When several consecutive accesses are made to data at the same core, thread
migration allows those accesses to become local, potentially improving performance over a remote-access regimen.
Migration costs, however, make it crucial to migrate only when multiple remote accesses would be replaced to make the cost "worth it." Moreover, since only a few registers are typically used between the time the thread migrates out and returns, transfer costs can be reduced by not migrating the unused registers. In this thesis, we especially focus on how to make judicious decisions on whether to perform a remote access or to migrate a thread, and how to further reduce thread migration costs by only migrating the necessary thread context.
1.5
Previous Works on Thread Migration
Migrating computation to accelerate data access is not itself a novel idea. Hector Garcia-Molina in 1984 introduced the idea of moving processing to data in memory bound architectures [26], and improving memory access latency via migration has been proposed using coarse-grained compiler transformations [32]. In recent years migrating execution context has re-emerged in the context of single-chip multicores. Michaud showed that execution migration can improve the overall on-chip cache capacity and selectively migrated sequential programs to improve cache performance [42]. Computation spreading [11] splits thread code into segments and migrates threads among cores assigned to the segments to improve code locality.
In the area of reliability, Core salvaging [47] allows programs to run on cores with permanent hardware faults provided they can migrate to access the locally damaged module at a remote core. In design-for-power, Thread motion [49] migrates less demanding threads to cores in a lower voltage/frequency domain to improve the overall power/performance ratios. More recently, thread migration among heterogeneous cores has been proposed to improve program bottlenecks (e.g., locks) [34].
Moving thread execution from one processor to another has long been a common feature in operating systems. The 02 scheduler [9], for example, improves memory performance in distributed-memory multicores by trying to keep threads near their
data during OS scheduling. This OS-mediated form of migration, however, is far too slow to make migrating threads for more efficient cache access viable: just moving the thread takes many hundreds of cycles at best (indeed, OSes generally avoid rebalancing processor core queues when possible). In addition, commodity processors are simply not designed to support migration efficiently: while context switch time is a design consideration, the very coarse granularity of OS-driven thread movement means that optimizing for fast migration is not.
Similarly, existing descriptions of hardware-level thread migration do not focus primarily on fast, efficient migrations. Thread Motion [49], for example, uses special microinstructions to write the thread context to the cache and leverages the underlying MESI coherence protocol to move threads via the last-level cache. The considerable on-chip traffic and delays that result when the coherence protocol contacts the directory, invalidates sharers, and moves the cache line, is acceptable for the 1000-cycle granularity of the centralized thread balancing logic, but not for the fine-grained migration at the instruction level which is the focus of this thesis. Similarly, hardware-level migration among cores via a single, centrally scheduled pool of inactive threads has been described in a four-core CMP [10]; designed to hide off-chip DRAM access latency, this design did not focus on migration efficiency, and, together with the round-trips required for thread-swap requests, the indirections via a per-core spill/fill buffer and the central inactive pool make it inadequate for the fine-grained migration needed to access remote caches.
1.6
Contributions
The specific contributions of this dissertation are as follows:
1. A directoryless architecture which supports fine-grained hardware-level thread migration to complement remote accesses (Chapter 2). Although thread (or process) movement has long been a common OS feature, the millisecond granularity makes this technique unsuitable for taking advantage of shorter-lived phenomena like fine-grained memory access locality. Based
on our pure hardware implementation of thread migration, we introduce a directoryless architecture where data mapped on a remote core can be accessed via a round-trip remote access protocol or by migrating a thread to where data resides.
2. A novel migration prediction mechanism which decides at instruction
granularity whether to perform a remote access or a thread migration (Chapter 3). Due to high migration costs, it is crucial to use thread migrations
judiciously under the proposed directoryless architecture. We, therefore, present an on-line algorithm which decides at the instruction level whether to perform a remote access or a thread migration.
3. Partial context thread migration to reduce migration costs (Chap-ter 4). We observe that not all the architectural regis(Chap-ters are used while a
thread is running on the migrated core, and therefore, always moving the entire thread context upon thread migrations is wasteful. In order to further cut down the cost of thread migration, we extend our prediction scheme to support partial
context migration, a novel thread migration approach that only migrates the necessary part of the architectural state.
4. The 110-core Execution Migration Machine (EM2 )-the silicon im-plementation to support hardware-level thread migration in a 45nm ASIC (Chapter 5). We provide the salient physical implementation details
of our silicon prototype of the proposed architecture built as a 110-core CMP, which occupies 100mm2 in 45nm ASIC technology. The EM2 chip adopts the stack-based core architecture which is best suited for partial context migration, and it also implements the stack-variant migration predictor. We also present detailed evaluation results of EM2 using the RTL-level simulation of several benchmarks on a full 110-core chip.
Chapter 6 concludes the thesis with a summary of the major findings and suggestions for future avenues of research.
Relation to other publications. This thesis extends and summarizes prior publi-cations by the author and others. The deadlock-free fine-grained thread migration protocol was first presented in [14], and a directoryless architecture using this thread migration framework with remote access (cf. Chapter 2) was introduced in [40,41]. While these papers do not address deciding between migrations and remote accesses for each memory access, Chapter 3 subsumes the description of a migration predictor presented in [54]. The work is extended in Chapter 4 to support partial context migration by learning and predicting the necessary thread context. In terms of the EM2 chip, the tapeout process was in collaboration with Mieszko Lis and Myong Hyon Cho, and the evaluation results of the RTL simulation in Chapter 5 were joint with Mieszko Lis; some of these contents, therefore, will also appear or has appeared in their theses. The physical implementation details of EM2 and our chip design experience can also be found in [53].
Chapter 2
Directoryless Architecture
2.1
Introduction
For scalability reasons, large-scale CMPs (> 16 cores) tend towards a tiled architecture where arrays of replicated tiles are connected over an on-chip interconnect [7,52,58]. Each tile contains a processor with its own Li cache, a slice of the L2 cache, and a router that connects to the on-chip network. To maximize effective on-chip cache capacity and reduce off-chip access rates, physically distributed L2 cache slices form one large logically shared cache, known as Non-Uniform Cache Access (NUCA) architecture [13,28,36]. Under this Shared L2 organization of NUCA designs, the address space is divided among the cores in such a way that each address is assigned to a unique home core where the data corresponding to the address can be cached at the L2 level. At the Li level, on the other hand, data can be replicated across any requesting core since current CMPs use Private Li caches. Coherence at the Li level is maintained via a coherence protocol and distributed directories, which are commonly co-located with the shared L2 slice at the home core.
To completely obviate the need for complex protocols and directories, a directoryless architecture extends the shared organization to Li caches-a cache line may only reside in its home core even at the Li level [23]. Because only one copy is ever cached, cache coherence is trivially ensured. To read and write data cached in a remote core, the directoryless architectures proposed and built so far use a remote access
mechanism wherein a request is sent to the home core and the resulting data (or acknowledgement) is sent back to the requesting core.
In what follows, we describe this remote access protocol, as well as a protocol based on hardware-level thread migration where instead of making a round-trip remote access the thread simply moves to the core where the data resides. We then present a framework that combines both.
2.2
Remote Cache Access
Under the remote-access framework of directoryless designs [23, 36], all non-local memory accesses cause a request to be transmitted over the interconnect network, the access to be performed in the remote core, and the data (for loads) or acknowledgement (for writes) to be sent back to the requesting core: when a core C executes a memory access for address A, it must
1. find the home core H for A (e.g., by consulting a mapping table or masking
some address bits); 2. if H = C (a core hit),
(a) forward the request for A to the cache hierarchy (possibly resulting in a DRAM access);
3. if H
#
C (a core miss),(a) send a remote access request for address A to core H;
(b) when the request arrives at H, forward it to H's cache hierarchy (possibly
resulting in a DRAM access);
(c) when the cache access completes, send a response back to C;
(d) once the response arrives at C, continue execution.
Note that, unlike a private cache organization where a coherence protocol (e.g., directory-based protocol) takes advantage of spatial and temporal locality by making
a copy of the block containing the data in the local cache, this protocol incurs a round-trip access for every remote word. Each load or store access to an address cached in a different core incurs a word-granularity round-trip message to the core allowed to cache the address, and the retrieved data is never cached locally (the combination of word-level access and no local caching ensures correct memory semantics).
2.3
Hardware-level Thread Migration
We now describe fine-grained, hardware-level thread migration, which we use to better exploit data locality for our directoryless architecture. This mechanism brings the execution to the locus of the data instead of the other way around: when a thread needs access to an address cached on another core, the hardware efficiently migrates the thread's execution context to the core where the data is (or is allowed to be) cached.
If a thread is already executing at the destination core, it must be evicted and moved to a core where it can continue running. To reduce the need for evictions and amortize migration latency, cores duplicate the architectural context (register file, etc.) and allow a core to multiplex execution among two (or more) concurrent threads. To prevent deadlock, one context is marked as the native context and the other as the guest context: a core's native context may only hold the thread that started execution there (called the thread's native core), and evicted threads must return to their native
cores to ensure deadlock freedom [14].
Briefly, when a core C running thread T executes a memory access for address A, it must
1. find the home core H for A (e.g., by consulting a mapping table or masking the appropriate bits);
2. if H = C (a core hit),
(a) forward the request for A to the local cache hierarchy (possibly resulting in a DRAM access);
3. if H
#
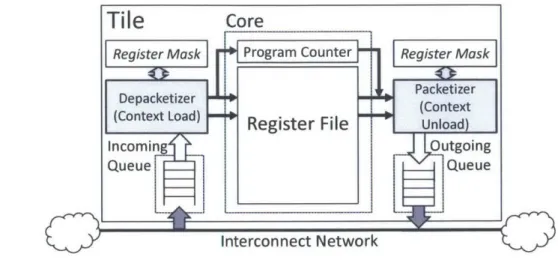
C (a core miss),(a) interrupt the execution of the thread on C (as for a precise exception), (b) unload the execution context (microarchitectural state) and convert it to a
network packet (as shown in Figure 2-1), and send it to H via the on-chip interconnect:
i. if H is the native core for T, place it in the native context slot; ii. otherwise:
A. if the guest slot on H contains another thread T', evict T' and migrate it to its native core N'
B. move T into the guest slot for H;
(c) resume execution of T on H, requesting A from its cache hierarchy (and potentially accessing backing DRAM or the next-level cache).
When an exception occurs on a remote core, the thread migrates to its native core to handle it.
Although the migration framework requires hardware changes to the baseline directoryless design (since the core must be designed to support efficient migration), it migrates threads directly over the interconnect, which is much faster than other thread migration approaches (such as OS-level migration or Thread Motion [49], which
leverage the existing cache coherence protocol to migrate threads).
2.4
Performance Overhead of Thread Migration
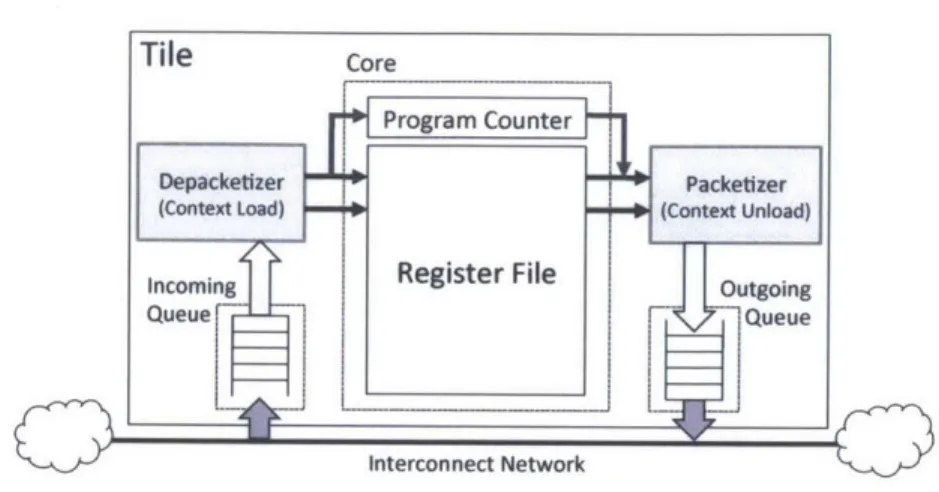
Since the thread context is directly sent across the network, the performance overhead of thread migration is directly affected by the context size. The relevant architectural state that must be migrated in a 64-bit x86 processor amounts to about 3.lKbits (sixteen 64-bit general-purpose registers, sixteen 128-bit floating-point registers and special purpose registers), which is what we use in this thesis. The context size will vary depending on the architecture; in the TILEPro64 [7], for example, it amounts
Tile Core
Depacketizerj Packetizer
(Context Load) No(Context Unload)
Incoming Register File Outgoing
Queue Queue
Interconnect Network
Figure 2-1: Hardware-level thread migration via the on-chip interconnect to about 2.2Kbits (64 32-bit registers and a few special registers). This introduces a
serialization latency since the full context needs to be loaded (unloaded) into (from) the network: with 128-bit flit network and 3.1Kbits context size, this becomes pkt size
I flit sizeI - 26 flits, incurring the serialization overhead of 26 cycles. With a 64-bit register file with two read ports and two write ports, one 128-bit flit can be read/written in one cycle and thus, we assume no additional serialization latency due to the lack of ports from/to the thread context.
Another overhead is the pipeline insertion latency. Since a memory address is computed at the end of the execute stage, if a thread ends up migrating to another core and re-executes from the beginning of the pipeline, it needs to refill the pipeline. In case of a typical five-stage pipeline core, this results in an overhead of three cycles. To make fair performance comparisons, all these migration overheads are included as part of execution time for architectures that use thread migrations, and their values are specified in Table 3.1.
2.5
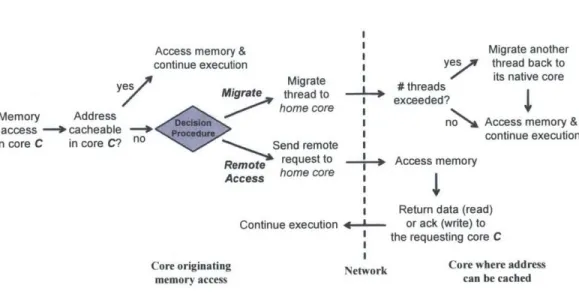
Hybrid Memory Access Framework
We now propose a hybrid architecture by combining the two mechanisms described: each core-miss memory access may either perform the access via a remote access as in Section 2.2 or migrate the current execution thread as in Section 2.3. This architecture
Access memory &
continue execution ys
Migrate
Migrate thread to I exc eded?
home core :
Send remote I
Remote request to Access memory
Access home core yes Memory Address access -- cacheable in core C in core C? no Core originating memory access
4
Migrate another thread back to its native coreAccess memory & continue execution
Return data (read)
Continue execution - or ack (write) to
the requesting core C Network Core where address
can be cached
Figure 2-2: Hybrid memory access framework for our directoryless architecture
is illustrated in Figure 2-2.
For each access to memory cached on a remote core, a decision algorithm determines whether the access should migrate to the target core or execute a remote access. Because this decision must be taken on every access, it must be implementable as efficient hardware. In our design, an automatic predictor decides between migration and remote access on a per-instruction granularity. It is worthwhile to mention that we allow replication for instructions since they are read-only; threads need not perform a remote access nor migrate to fetch instructions. We describe the design of this predictor in the next chapter.
Chapter 3
Thread Migration Prediction
3.1
Introduction
Under the remote-access-only architecture, every core-miss memory access results in a round-trip remote request and its reply (data word for load and acknowledgement for store). Therefore, migrating a thread can be beneficial when several memory accesses are made to the same core: while the first access incurs the migration costs, the remaining accesses become local and are much faster than remote accesses. Since thread migration costs exceed the cost required by remote-access-only designs on a per-access basis due to a large thread context size, the goal of the thread migration predictor is to judiciously decide whether or not a thread should migrate: since migration outperforms remote accesses only for multiple contiguous memory accesses to the same location, our migration predictor focuses on detecting those.
3.2
Thread Migration Predictor
3.2.1
Per-core Thread Migration Predictor
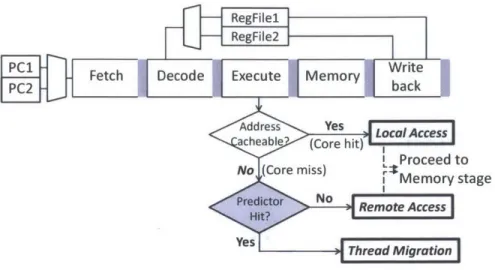
Since the migration/remote-access decision must be made on every memory access, the decision mechanism must be implementable as efficient hardware. To this end, we will describe a per-core migration predictor-a PC-indexed direct-mapped data structure
RegFilel
FH ARegFile2
PCetch Decode Execute Memory Write
PC2 back
acheable? (Core hit)- Ioa~cs
I Proceed to No (Core miss) 3MmoystgiMemory stage
Hid tr N Remote Access
Yes Thread Migration
Figure 3-1: Hybrid memory access architecture with a thread migration predictor on a 5-stage pipeline core.
where each entry simply stores a PC. The predictor is based on the observation that sequences of consecutive memory accesses to the same home core are highly correlated with the program flow, and that these patterns are fairly consistent and repetitive across program execution. Our baseline configuration uses 128 entries; with a 64-bit PC, this amounts to about 1KB total per core.
The migration predictor can be consulted in parallel with the lookup of the home core for the given address. If the home core is not the core where the thread is currently running (a core miss), the predictor must decide between a remote access and a thread migration: if the PC hits in the predictor, it instructs a thread to migrate; if it misses, a remote access is performed.
Figure 3-1 shows the integration of the migration predictor in a hybrid memory access architecture on a 5-stage pipeline core. The architectural context (RegFile2 and PC2) is duplicated to support deadlock-free thread migration (cf. Section 2.3); the shaded module is the component of migration predictor.
In the next section, we describe how a certain instruction (or PC) can be detected as "migratory" and thus inserted into the migration predictor.
3.2.2
Detecting Migratory Instructions: WHEN to migrate
At a high level, the prediction mechanism operates as follows:1. when a program first starts execution, it runs as the baseline directoryless
architecture which only uses remote accesses;
2. as it continues execution, it monitors the home core information for each memory access, and
3. remembers the first instruction of every multiple access sequence to the same
home core;
4. depending on the length of the sequence, the instruction address is either inserted into the migration predictor (a migratory instruction) or is evicted from the predictor (a remote-access instruction);
5. the next time a thread executes the instruction, it migrates to the home core if
it is a migratory instruction (a "hit" in the predictor), and performs a remote access if it is a remote-access instruction (a "miss" in the predictor).
The detection of migratory instructions which trigger thread migrations can be easily done by tracking how many consecutive accesses to the same remote core have been made, and if this count exceeds a threshold, inserting the PC into the predictor to trigger migration. If it does not exceed the threshold, the instruction is classified as a remote-access instruction, which is the default state. Each thread tracks (1) Home, which maintains the home location (core ID) for the current requested memory address, (2) Depth, which indicates how many times so far a thread has contiguously accessed the current home location (i.e., the Home field), and (3) Start PC, which tracks the
PC of the very first instruction among memory sequences that accessed the home
location that is stored in the Home field. We separately define the depth threshold 0, which indicates the depth at which we determine the instruction as migratory.
The detection mechanism is as follows: when a thread T executes a memory instruction for address A whose PC = P, it must
1. find the home core H for A (e.g., by consulting a mapping table or masking the appropriate bits);
2. if Home = H (i.e., memory access to the same home core as that of the previous memory access),
(a) if Depth < 0, increment Depth by one;
3. if Home 7 H (i.e., a new sequence starts with a new home core),
(a) if Depth = 0, StartPC is considered a migratory instruction and thus inserted into the migration predictor;
(b) if Depth < 0, StartPC is considered a remote-access instruction;
(c) reset the entry (i.e., Home = H, PC = P, Depth = 1).
Memory Instruction Present State Next State Action
PC Home Core Home Depth Start PC Home Depth Start PC
I, : PC, A - - - A I PC, Reset the entry for a new sequence starting from PC, 1: PC, B A I PC, B I PC, Reset the entry for a new sequence starting from PC2
(evict PC, from the predictor, if exists)
1,: PC, C B I PC, C I PC, Reset the entry for a new sequence starting from PC3
(evict PC2 from the predictor, if exists)
1,: PC4 C C I PC, C 2 PC, Increment the depth by one
1, : PC, C C 2 PC, C 2 PC, Do nothing (threshold already reached) I": PC, C C 2 PC3 C 2 PC3 Do nothing (threshold already reached) 17: PC, A C 2 PC3 A I PC, Insert PC, into the migration predictor
Reset the entry for a new sequence starting from PC7
Figure 3-2: accesses to case of the
An example of how instructions (or PC's) that are followed by consecutive the same home location (i.e., migratory instructions) are detected in the depth threshold 0 = 2.
Figure 3-2 shows an example of the detection mechanism when 0 = 2. Setting
0 = 2 means that a thread will perform remote accesses for "one-off" accesses and will migrate for multiple accesses (> 2) to the same home core. Suppose a thread executes 'Since all instructions are initially considered as remote-accesses, setting the instruction as a remote-access instruction will have no effect if it has not been classified as a migratory instruction.
If the instruction was migratory (i.e., its PC is in the predictor), however, it reverts back to the
a sequence of memory instructions, I1 1 I7 (non-memory instructions are ignored in
this example because they do not change the entry content nor affect the mechanism). The PC of each instruction from 1 to 17 is PC1, PC2, ... PC7, respectively, and the home core for the memory address that each instruction accesses is specified next to each PC. When 1 is first executed, the entry {Home, Depth, Start PC} will hold the value of {A, 1, PC1}. Then, when 12 is executed, since the home core of I2 (B)
is different from Home which maintains the home core of the previous instruction I1
(A), the entry is reset with the information of '2. Since the Depth to core A has not reached the depth threshold, PC1 is considered a remote-access instruction (default).
The same thing happens for 13, setting PC2 as a remote-access instruction. Now when
14 is executed, it accesses the same home core C and thus only the Depth field needs to be updated (incremented by one). For 15 and I6 which keep accessing the same home core C, we need not update the entry because the depth has already reached the threshold 0, which we assumed to be 2. Lastly, when 17 is executed, since the Depth to core C has reached the threshold, PC3 in the Start PC field, which represents the first instruction (13) that accessed this home core C, is classified as a migratory instruction and thus is added to the migration predictor. Finally, the predictor resets the entry and starts a new memory sequence starting from PC7 for the home core A. When an instruction (or PC) that has been added to the migration predictor is encountered again, the thread will directly migrate instead of sending a remote request and waiting for a reply. Suppose the example sequence I, ~ 17 we used in Figure 3-2 is repeated as a loop (i.e., I1, I2, ... 17, 1,, ... ) by a thread originating at core A. Under a standard, remote-access-only architecture where the thread will never leave its native core A, every loop will incur five round-trip remote accesses; among seven instructions from 1 to I7, only two of them (I, and 17) are accessing core A which result in core hits. Under our migration predictor with 0 = 2, on the other hand,
PC3 and PC7 will be added in the migration predictor and thus the thread will now migrate at 13 and 17 in the steady state. As shown in Figure 3-3, every loop incurs two migrations, turning 14, 15, and I6 into core hits (i.e., local accesses) at core C: overall 4 out of 7 memory accesses complete locally. The benefit of migrating a thread
PC3
.
......
(a) I2 is served via a remote-access since its
PC, PC2, is not in the migration predictor.
/WA B
(c) By migrating the thread to core C, three successive accesses to core C (14, 15 and 16) now turn into local memory accesses.
...
A
(b) The thread migrates when it
encoun-ters 13 since it hits in the migration pre-dictor.
PC A
(d) On I7, the thread migrates back to core
A. Overall, two migrations and one remote
access are incurred for a single loop.
Figure 3-3: An example of how the decision between remote access and thread migration is made for every memory access.
becomes even more significant with a longer sequence of successive memory accesses to the same non-native core (core C in this example).
3.2.3
Possible Thrashing in the Migration Predictor
Since we use a fixed size data structure for our migration predictor, collisions between different migratory PCs can result in suboptimal performance. While we have chosen a size that results in good performance, some designs may need larger (or smaller) predictors. Another subtlety is that mispredictions may occur if memory access patterns for the same PC differ across two threads (one native thread and one guest thread) running on the same core simultaneously because they share the same per-core predictor and may override each other's decisions. Should this interference become significant, it can be resolved by implementing two predictors instead of one per core-one for the native context and the other for the guest context.
In our set of benchmarks, we rarely observed performance degradation due to these collisions and mispredictions with a fairly small predictor (about 1KB per core) shared by both native and guest context. This is because each worker thread executes very similar instructions (althoiTgh on different data) and thus, the detected migratory instructions for threads are very similar. While such application behavior may keep the predictor simple, however, our migration predictor is not restricted to any specific applications and can be extended if necessary as described above. It is important to note that even if a rare misprediction occurs due to either predictor eviction or interference between threads, the memory access will still be carried out correctly, and the functional correctness of the program is still maintained.
3.3
Experimental Setup
We use Pin [5] and Graphite [43] to model the proposed hybrid architecture that supports both remote-access and thread migration. Pin enables runtime binary instrumentation of parallel programs; Graphite implements a tile-based multicore, memory subsystem, and network, modeling performance and ensuring functional correctness. The default system parameters are summarized in Table 3.1.
Parameter Settings
Cores 64 in-order, 5-stage pipeline, single issue cores, 2-way fine-grain multithreading
L1/L2 cache per core 32/128 KB, 2/4-way set associative, 64B block
Electrical network 2D Mesh, XY routing, 2 cycles per hop (+ contention), 128b flits
Migration Overhead 3.1 Kbits full execution context size, Full context
load/unload latency: =
26
cycles
Iflit sizeI =
Pipeline insertion latency = 3 cycles
Data Placement First-touch after initialization, 4 KB page size
Table 3.1: System configurations used
Experiments were performed using Graphite's model of an electrical mesh network with XY routing with 128-bit flits. Since modern NoC routers are pipelined [19], and
2- or even 1-cycle per hop router latencies [38] have been demonstrated, we model a 2-cycle per-hop router delay; we also account for the pipeline latencies associated with loading/unloading packets onto the network. In addition to the fixed per-hop latency, we model contention delays using a probabilistic model as in [37].
For data placement, we use the first-touch after initialization policy which allocates the page to the core that first accesses it after parallel processing has started. This allows private pages to be mapped locally to the core that uses them, and avoids all the pages being mapped to the same core where the main data structure is initialized before the actual parallel region starts.
3.3.1
Application Benchmarks
Our experiments use a parallel perceptron cross-validation (prcn+cv) benchmark and a set of Splash-2 [60] benchmarks with the recommended input set for the number of cores used2: fft, lu-contiguous, ocean-contiguous, radi?, raytrace and water-nsq.
Chunk 1 Chunk 2 Chunk 3 Chunk 4
Experiment 1 Training data
Parallel execution
Experiment 2 (Each thread runs a separate
experiment, which sequentially
Experiment 3 trains the model with (K-1) data
chunks and test with the last chunk)
Experiment 4 Train
Total data spread across L2 cache slices
( Data chunk i is mapped to Core i )
Figure 3-4: Parallel K-fold cross-validation using perceptron
Parallel cross-validation (prcn+cv) is a popular machine learning technique for optimizing model accuracy. In the k-fold cross-validation, as illustrated in Figure 3-4, data samples are split into k disjoint chunks and used to run k independent
leave-one-2
Some were not included due to simulation issues.
3
Unlike other Splash-2 benchmarks, radix was originally filling an input array with random numbers (not a primary part of radix-sort algorithm) in the parallel region; thus, we moved the initialization part prior to spawning worker threads so that the parallel region solely performs the actual sorting.
out experiments. Each thread runs a separate experiment, which sequentially trains the model with k - 1 data chunks (training data) and tests with the last chunk (test data). The results of k experiments are used either to better estimate the final prediction accuracy of the algorithm being trained, or, when used with different parameter values, to pick the parameter that results in the best accuracy. Since the experiments are computationally independent, they naturally map to multiple threads. Indeed, for sequential machine learning algorithms, such as stochastic gradient descent, this is the
only practical form of parallelization because the model used in each experiment is necessarily sequential. The chunks are typically spread across the shared cache shards, and each experiment repeatedly accesses a given chunk before moving on to the next one.
Our set of Splash-2 benchmarks are slightly modified from their original versions: while both the remote-access-only baseline and our proposed architecture do not allow replication for any kinds of data at the hardware level, read-only data can actually be replicated without breaking cache coherence even without directories and a coherence protocol. We, therefore, applied source-level read-only data replication to these benchmarks; more details on this can be found in Appendix A. Our optimizations were limited to rearranging and replicating some data structures (i.e., only tens of lines of code changed) and did not alter the algorithm used; automating this replication is outside of the scope of this work. It is important to note that both the remote-access-only baseline and our hybrid architecture benefit almost equally from these optimizations.
Each application was run to completion; for each simulation run, we measured the core miss rate, the number of core-miss memory accesses divided by the total number of memory accesses. Since each core-miss memory access must be handled either by remote access or by thread migration, the core miss rate can further be broken down into remote access rate and migration rate. For the baseline remote-access-only architecture, the core miss rate equals the remote access rate (i.e., no migrations); for our hybrid design, the core miss rate is the sum of the remote access rate and the migration rate. For performance, we measured the parallel completion time (the
longest completion time in the parallel region). Migration overheads (cf. Chapter 2.4) for our hybrid architecture are taken into account.
3.3.2
Evaluated Systems
Since our primary focus in this chapter is to improve the capability of exploiting data locality at remote cores by using thread migrations judiciously, we compare our hybrid directoryless architecture against the remote-access-only directoryless architecture4. We refer to the directoryless, remote-access-only architecture as NoDirRA and the hybrid architecture with our migration predictor as NoDirPred-Full. The suffix of -Full means that the entire thread context is always migrated upon thread migrations.
3.4
Simulation Results
3.4.1
Performance
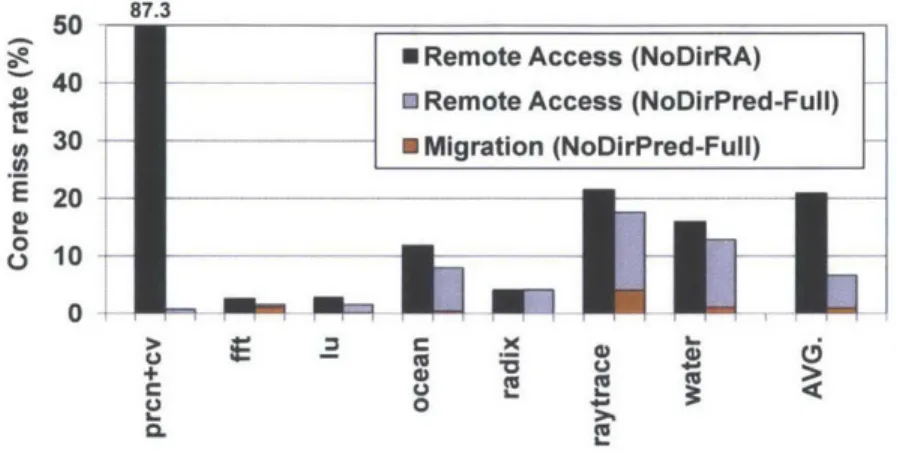
We first compare the core miss rates for a directoryless system without and with thread migration: the results are shown in Figure 3-5. The depth threshold 9 is set to 3 for our migration predictor, which aims to perform remote accesses for memory sequences with one or two accesses and migrations for those with > 3 accesses to the same core. Although we have evaluated our system with different values of 0, we consistently use 9 = 3 here since increasing 9 only makes our hybrid design converge to the remote-access-only design and does not provide any further insight.
While 21% of total memory accesses result in core misses for the remote-access-only design on average, the directoryless architecture with our migration predictor results in a core miss rate of 6.7%, a 68% improvement in data locality. Figure 3-5 also shows the fraction of core miss accesses handled by remote accesses and thread migrations in our design. We observe that a large fraction of remote accesses are successfully replaced with a much smaller number of migrations. For example, prcn+cv shows the best scenario where it originally incurred a 87% remote access rate under
4
The performance comparison against a conventional directory-based scheme is provided in Chapter 4.