Progenetix: 12 years of oncogenomic data curation
8
0
0
Texte intégral
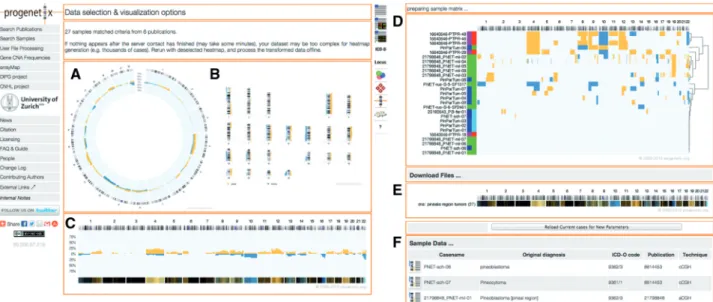
Figure


Documents relatifs