HAL Id: tel-02938383
https://tel.archives-ouvertes.fr/tel-02938383v2
Submitted on 7 Jul 2021HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés.
A contribution to fact-checking automation mechanisms
for augmented journalism
Edouard Ngor Sarr
To cite this version:
Edouard Ngor Sarr. A contribution to fact-checking automation mechanisms for augmented journal-ism. Web. Université de Thiès (Sénégal), 2019. Français. �tel-02938383v2�
UNIVERSITÉ DE THIES
Ecole Doctorale Développement Durable et Société (ED2DS) _____________________ Année académique : 2017/2018 N° d’ordre : 001/2019
THESE DE DOCTORAT
Spécialité : Informatique
Présentée par :Edouard Ngor SARR
Contribution aux mécanismes d’automatisation du
fact-checking pour un journalisme augmenté
Soutenu le 12/01/2019 devant le jury composé de :
M. Cheikh SARR Professeur Titulaire, Université de THIES Président
M. Mouhamadou THIAM Maître de Conférences, Université de THIES Examinateur
M. Mamadou BOUSSO Maître de Conférences, Université de THIES Examinateur
M. Moussa LO Professeur Titulaire, Université Virtuelle du Sénégal
Rapporteur
M. Cheikh Talibouya DIOP Professeur Titulaire, Université Gaston Berger de
Saint-Louis Rapporteur
M. Idrissa SARR Maître de Conférences, Université Cheikh Anta DIOP de Dakar
Rapporteur
iii
R
ESUME
Cette thèse traite les questions relatives à l’automatisation de la vérification des faits (fact-checking) dans le contexte web journalistique. Faire du fact-checking consiste pour les médias et les professionnels de l’information, à vérifier la véracité des faits tenus dans l’espace médiatique, c’est-à-dire, à valider l’exactitude des affirmations. Une étude de l’état de l’art montre qu’il s’agissait plus d’une pratique manuelle qui a d’ailleurs montrée ses limites face à la vélocité, au volume et à la variété des données traitées sur internet. D’où la nécessité de disposer de nouvelles méthodes et outils automatisés pour vérifier les faits en temps réel. Nous cherchons dans quelle mesure le fact-checking, en tant que genre journalistique est automatisable. En d’autres termes, nous cherchons à mettre au point des algorithmes et des agents de fact-checking automatisés mais aussi, à proposer de nouvelles orientations pour l’évolution du métier journalistique. Cinq contributions sont présentées dans la thèse. La première contribution est un collecteur automatique d’articles et d’affirmations factuelles à partir de la presse en ligne (FactExtract). La deuxième contribution est un identificateur-étiqueteur automatique de faits dans les discours en langue française (FactTagger). Un générateur de jeux de données synthétiques, personnalisables et proches de l’environnement réel (JFact) et deux algorithmes non-supervisés de vérification des faits (SnVera et SenFact) sont aussi proposés.
Mots-clés : Journalisme, Fact-checking, Fakenew, datajournalisme, journalisme augmenté, Algorithme, Datasets, web sémantique, Ordonnancement des faits, Web Scraping, Fusion de données & Tagging des faits.
iv
A
BSTRACT
This thesis deals with the questions related to automation of the fact-checking in the journalistic web context. It consists, for the media and the professionals of information, of checking the veracity of facts in the media sphere. In other words, this is to authenticate the accuracy of the statements. An investigation of the state of the art shows that it was more conerned with manual practice which is restricted regarding the velocity, the volume and the variety of processed data on internet. Hence, the necessity to have new methods and automated tools in order to verify the facts at due time. This research analyses how the fact-checking, as a journalistic genre, is automatable. To put it in another, we seek to focus on the algorithms and the agents of automated fact-checking but also, to propose new orientations for the evolution of the journalistic profession. Five contributions are presented in the thesis. The first contribution that is presented is an automatic collection (web scraping) of articles and factuals claims from the online press (FactExtract). The second contribution is an automatic tagger of facts in French-language speeches (FactTagger). A synthetic data set generator, customizable and close to the real journalistic environment (JFact) and two algorithms of fact-checking (SnVera and SenFact) are available.
Keywords : Journalism, Fact-checking, Fakenew, Facts-checking, datajournalism, increased journalism, Algorithm, Datasets, semantic web, facts’ organization, Web Scraping, data merging & Facts Tagging
v
T
ABLE DES MATIÈRES
Remerciements ... Erreur ! Le signet n’est pas défini.
Résume ... iii
Abstract ... iv
liste des figures ... x
liste des tableaux ... xii
Liste des formules ... xiii
Table des définitions ... xiv
Introduction générale ... 1 1. Contexte ... 1 2. Problématique ... 2 3. Contributions ... 4 4. Plan du manuscrit ... 5 Chapitre 1 : Le fact-checking ... 7 Sommaire ... 7 1.1. Introduction ... 8
1.2. Le journalisme à l’ère du big data et de l’open data ... 8
1.2.1. Le contexte des Big Data ... 9
1.2.2. L’open Data ... 10
1.2.3. Le datajournalisme ... 11
1.3. La prolifération des fakenews ... 12
1.3.1. Définitions ... 12
1.3.2. Les formes de fakenews dans le journalisme ... 13
1.3.2.1. Le Buzz ... 13
1.3.2.2. Le Framing ... 14
1.3.2.3. La ré-information ... 14
1.3.2.4. La rumeur ... 14
vi
1.3.2.6. Le complot ... 15
1.3.2.7. Les fausses citations ... 15
1.4. Le fact-checking ... 16
1.4.1. Definitions ... 16
1.4.1.1. Affirmation factuelle ... 16
1.4.1.2. Les faits ... 16
1.4.1.3. La véracité d’un fait ... 18
1.4.1.4. La fiabilité d’une source ... 19
1.4.1.5. Le fact-checking ... 19
1.4.2. Historique du fact-checking ... 19
1.5. Le fact-checking web ... 21
1.6. Le fact-checking automatique ... 24
1.6.1. Les enjeux ... 24
1.6.2. Les processus de fact-checking automatisé ... 27
1.7. Conclusion ... 28
Chapitre 2 : Etat de l’art ... 29
2.1. Introduction ... 30
2.2. Les datasets ... 30
2.2.1. Définitions ... 30
2.2.2. Généralité sur les datasets en fact-checking ... 31
2.2.3. Les datasets réels ... 33
2.2.4. La fabrication de données synthétiques de test ... 37
2.3. Les algorithmes de fact-checking ... 39
2.3.1. Les concepts de base ... 39
2.3.2. Les principales approches ... 40
2.3.3. Les algorithmes de fact-checking ... 42
2.3.3.1. Généricité ... 42
2.3.3.2. Algorithme ... 44
vii
2.4.1. L’extraction et l’identification des faits factuels ... 50
2.4.2. Le tagging automatique des faits ... 52
2.4.2.1. Le TALN ... 52
2.4.2.2. L’étiquetage morphosyntaxique ... 53
2.4.2.3. Tagging des faits ... 56
2.5. Les tentatives d’automatisation du fact-checking ... 56
2.6. Conclusion ... 60
Chapitre 3 : Extraction et Etiquetage automatique des faits ... 62
3.1. Introduction ... 63
3.2. FactExtract ... 63
3.2.1. Présentation ... 63
3.2.1.1. MEA, l’extracteur automatique d’articles de presse ... 64
3.2.1.2. MFA, la fusion et la segmentation des articles en faits ... 66
3.2.2. Utilisation de FactExtract ... 70
3.2.3. Paramétrage de l’extracteur ... 70
3.2.4. Dataset de faits journalistiques réels. ... 71
3.3. FactTagger ... 72
3.3.1. Presentation ... 72
3.3.2. Prétraitement et Pre-etiquettage avec Treetagger ... 73
3.3.3. Réduction du Tagset ... 76
3.3.4. Le regroupement sémantique ... 77
3.3.5. Etiquetage des Faits ... 79
3.4. Conclusion ... 80
Chapitre 4 : JFact et SnVera ... 81
4.1. Introduction ... 82
4.2. JFact ... 82
4.2.1. Description de l’API ... 82
4.2.2. Mode de fonctionnement et Architecture ... 83
viii 4.2.4. Etude comparative ... 88 4.3. SnVera ... 89 4.3.1. Description ... 89 4.3.2. Hypothèses ... 89 4.3.3. Le calcul de la fiabilité ... 90 4.3.4. Le calcul de la véracité ... 91 4.3.5. Evaluation du modèle ... 94
4.3.5.1. Constitution des corpus ... 94
4.3.5.1.1. Jeux de données synthétiques ... 94
4.3.5.1.2. Jeux de données réelles (SnDataset) ... 95
4.3.6. Méthodologies d’évaluation ... 95
4.3.7. Résultats et interprétations ... 96
4.3.7.1. Résultats sur Jeux de données synthétiques ... 96
4.3.7.2. Résultats sur les données réelles ... 101
4.4. Conclusion ... 103
Chapitre 5 : Architecture Générale proposée ... 104
5.1. Introduction ... 105
5.2. Architecture ... 105
5.3. Fonctionnement ... 109
5.4. Conclusion ... 110
Conclusion générale et perspectives ... 111
Nos contributions : ... 111
Les Perspectives ... 112
Liste des publications tirées de la thèse ... 114
Liste des articles acceptés pour publication ... 115
Liste des communications ... 116
Bibliographie ... 117
ix Annexe 2 : Affirmations.json ... 134 Annexe 3 : Article .Json ... 136
x
LISTE DES FIGURES
Figure 1. Tâches du Datajournalisme ... 11
Figure 2. Évolution de la recherche du terme « fakenews » dans le monde selon Google trends, depuis le 1er janvier 2012 ... 13
Figure 3. Représentation visuelle du fait ... 17
Figure 4. Illustration de faits ... 17
Figure 5. Score de véracité ... 18
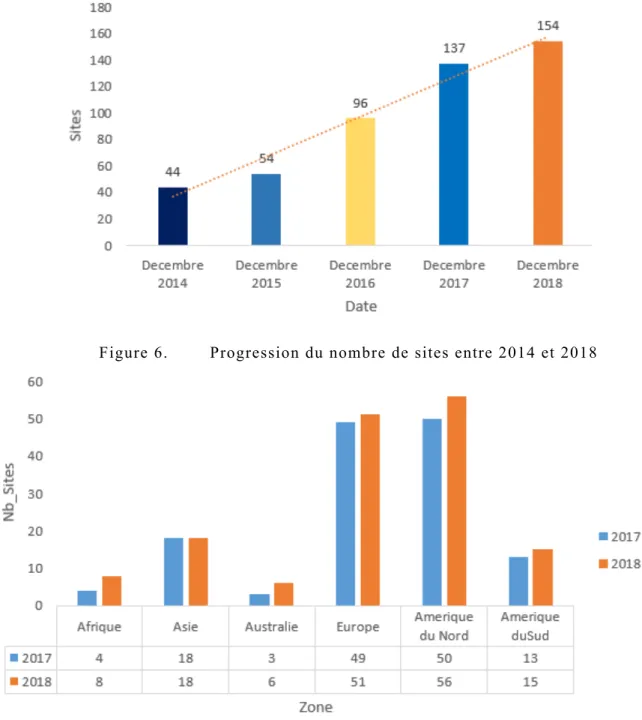
Figure 6. Progression du nombre de sites entre 2014 et 2018 ... 22
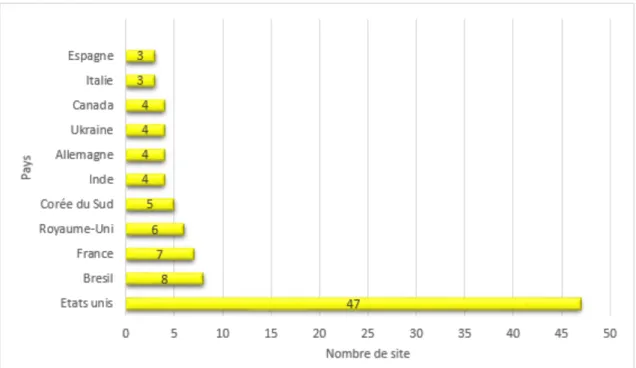
Figure 7. Progression du nombre de sites de fact-checking par zone entre 2017 et 2018 ... 22
Figure 8. Progression du nombre de sites de fact-checking ces 10 derniers années ... 23
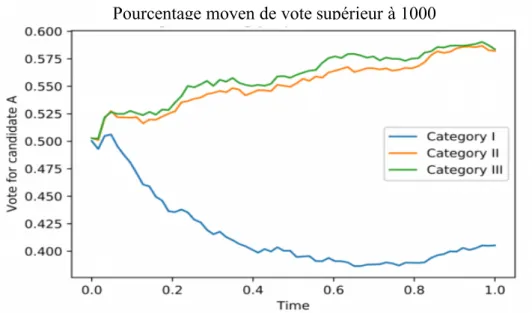
Figure 9. Les pays avec plus de 3 sites de fact-checking ... 23
Figure 10. Influence des fakenews dans les élections ... 25
Figure 11. Les étapes de l’automatisation du fact-checking ... 27
Figure 12. Un fichier d’affirmations claim1.csv du Dataset Population ... 32
Figure 13. Un fichier d’affirmations flights_claim1.csv issu du Dataset Flights ... 32
Figure 14. Le fichier des valeurs vraies du dataset Biography ... 33
Figure 15. Le fichier des valeurs vraies du dataset Weather ... 33
Figure 16. Répartition des faits ... 39
Figure 17. Algorithme générique de fact-checking non supervisé ... 42
Figure 18. Algorithme générique de fact-checking supervisé ... 43
Figure 19. Etude comparative des algorithmes de fact-checking sur 3 jeux de données réelles. 48 Figure 20. Web scraping ... 51
Figure 21. Architecture générale de FactExtract ... 64
Figure 22. Exemple d’extraction ... 66
Figure 23. Aperçu du fichier Sn_Affirmation_Datasets.json ... 68
xi
Figure 25. Progression du nombre d’articles ... 72
Figure 26. The tagging pipeline ... 73
Figure 27. Fonction de réduction du Tagset ... 77
Figure 28. Fonction de regroupement ... 78
Figure 29. Extrait des résultats de FactTagger ... 80
Figure 30. Architecture de HFact ... 86
Figure 31. Sortie de la commande JFACT ... 87
Figure 32. Algorithme de calcul de la fiabilité ... 92
Figure 33. Algorithme de calcul de la véracité ... 93
Figure 34. Précision des algorithmes sur les datasets ... 98
Figure 35. Tendance des précisions de SnVera suivant l’augmentation du nombre de sources 99 Figure 36. Tendance des précisions de SUMS suivant l’augmentation du nombre de sources 99 Figure 37. Tendance des précisions de AverageLog suivant l’augmentation du nombre de sources 100 Figure 38. Tendance des précisions de l’algorithme VOTE suivant l’augmentation du nombre de sources 100 Figure 39. Représentation des résultats avec SnDataset ... 102
Figure 40. Architecture de la plateforme ... 105
Figure 41. Algorithme de fonctionnement de la plateforme ... 109
xii
LISTE DES TABLEAUX
Tableau 1 Les formes de fakenews ... 15
Tableau 2 Exemple d’affirmations factuelles. ... 17
Tableau 3 Signification des notations utilisées ... 40
Tableau 4 Tableau comparatif des algorithmes de vérification des faits tiré de [27] ... 48
Tableau 5 Concepts de base de l’étiquetage morpho-syntaxique ... 54
Tableau 6 Exemple de segmentation et étiquetage manuels ... 56
Tableau 7 Répartition des projets de fact-checking automatisé ... 60
Tableau 8 Liste des stopwords en français ... 65
Tableau 9 Variables JSON du fichier Sn_Articles_Datasets.json ... 67
Tableau 10 Variables JSON du fichier Sn_Affirmation_Datasets.json ... 68
Tableau 11 Détails de la collecte ... 71
Tableau 12 Treetagger Tagset ... 74
Tableau 13 Quelques règles de transformation ... 75
Tableau 14 Quelques mots et caractères vides éliminés ... 76
Tableau 15 Extrait du corpus de test ... 79
Tableau 16 Vision partielle du fichier Sources.csv ... 84
Tableau 17 Vision partielle du fichier Objet34.csv ... 85
Tableau 18 Vision partielle du fichier des valeurs vraie. ... 85
Tableau 19 Aperçu du fichier des affirmations Affirmations23.csv. ... 86
Tableau 20 Caractère aléatoire de JFact ... 88
Tableau 21 Etude comparative entre JFact et les autres datasets ... 88
Tableau 22 Interprétation des résultats potentiels ... 93
Tableau 23 Datasets synthetiques ... 94
Tableau 24 Etude comparative sur les jeux de données synthetiques ... 97
xiii
L
ISTE DES FORMULES
(1) Exemple de calcul de la veracité d’un fait ... 19
(2) Exemple de calcul de la fiabilité d’une source ... 19
(3) Calcul de la precision ... 33
(4) Calcul de la taille du dataset selon l’approche de la de la fiabilité initiale ... 33
(5) Calcul de la taille du dataset selon l’approche de la de la liberté à la production ... 38
(6) Calcul du degré de centralit ... 38
(7) Calcul de la fiabilité de l’algorithme SUMS ... 44
(8) Calcul de veracité de l’algorithme SUMS ... 45
(9) Calcul de veracité de l’algorithme TrustFinder ... 45
(10) Calcul de la fiabilité de l’algorithme TrustFinder ... 45
(11) Calcul de veracité de l’algorithme AverageLog ... 45
(12) Calcul de la fiabilité de l’algorithme AverageLog ... 45
(13) Calcul de veracité de l’algorithme Investment ... 46
(14) Calcul de la fiabilité de l’algorithme Investment ... 46
(15) Calcul de veracité de l’algorithme Adapted Sums ... 46
(16) Calcul de la fiabilité de l’algorithme Adapted Sums ... 46
(17) Calcul de la fiabilité de l’algorithme TrustFinder ... 91
(18) Calcul de la fiabilité de l’algorithme SnVera ... 91
(19) Calcul de la fiabilité de l’algorithme SnVera ... 91
(20) Calcul du Score de confirmation de l’algorithme SnVera ... 92
(21) Calcul du Score de contestation de l’algorithme SnVera ... 92
xiv
T
ABLE DES DEFINITIONS
Le Big data ... 9
Le Volume ... 9
La Variété ... 9
La vélocité ... 9
La valeur ... 10
La véracité en Big Data ... 10
L’open data ... 10 Le datajournalisme ... 11 Un fakenew ou « infaux » ... 13 Un Buzz ... 13 Le Framing ... 14 La ré-information ... 14 La rumeur ... 14 Un canular ... 14 Le complot ... 15
Les fausses citations ... 15
Un article de presse ... 16
Une affirmation factuelle ... 16
Un fait ... 16 Un sujet ... 16 Un prédicat ... 17 Une valeur ... 17 La véracité ... 18 La fiabilité ... 19
xv
Le fact-checking automatique ... 27
Un jeu de données (Dataset) ... 30
Les datasets réels ... 30
Les datasets synthétiques ... 31
L’extraction, l’identification et le tagging des faits (EIT) ... 50
Le Traitement Automatique de la langue Naturelle (TALN) ... 52
L’étiquetage morphosyntaxique (Tagging) ... 53
1
I
NTRODUCTION GENERALE
1. Contexte
L’augmentation rapide des médias en ligne et la course effrénée à la publication d’articles de presse (produire vite et en masse) ont entrainé la prolifération des fausses informations dans l’espace médiatique. Cette forte concurrence pousse aujourd’hui certains journalistes à accélérer les publications des articles en omettant ainsi, la phase de vérification des faits : le socle même du journalisme et la pierre angulaire du journaliste [10]. C’est précisément cette responsabilité du journalisme face à l’information qu’elle véhicule qui est souligné dans code de la presse sénégalais adopté par l’assemblé nationale du Sénégal le 20 Juin 2017 (Projet de loi N°14/2017). En effet, autorités étatiques, parlementaires et professionnels de l’information et de la communication ont dessiné les contours de ce qui va désormais régir l’exercice de la profession journalistique. Ce code de 233 articles recouvre la définition du statut des journalistes et techniciens travaillant dans les médias, les « droits » et « devoirs » des journalistes, ainsi que les règles encadrant l’aspect économique des entreprises de presse1. Avec ce code, les sites d’informations seront désormais très encadrés pour lutter contre la prolifération des fakenews.
Cette prolifération des fausses informations s’est accentuée avec l’avènement des réseaux sociaux où chaque internaute devient son propre journaliste donc, producteur d’informations. Ce phénomène de partage sans possibilité de confrontation ni de vérification des propos relatés, fait que, les fausses informations inondent l’espace médiatique surtout la presse en ligne. Les faussetés prennent aujourd’hui plusieurs formes : les politiciens et les annonceurs font de fausses déclarations, les journalistes font des erreurs, et la facilité de publication et de partage permet aux théories les plus incroyables de se répandre rapidement. Le risque d'interpréter les contre-vérités comme des vérités est aujourd’hui très significatif et ne fait qu'augmenter. L’internaute n’a alors aucune garantie sur la véracité des faits qui lui parviennent et il ne lui est pas toujours facile de déterminer à priori les sources fiables. Pour cause, il n’y a plus une nette distinction entre les sites d’informations généraux, réputés fiables et d’autres comme sites de propagande, les blogs et les réseaux sociaux. A tout cela s’ajoute les limites et l’incapacité du journaliste actuel à traiter et filtrer manuellement cette masse d’informations lui parvenant chaque jour. Face à tous ces manquements et problèmes, la vérification
2
des faits ou Fact-checking est devenue aujourd’hui plus que jamais, un enjeu et une nécessité pour les entreprises et les gouvernements mais aussi, une forte demande sociale [98].
La vérification des faits plus connue sous son nom anglais fact-checking consiste, à fouiller des sources supposées fiables, d'en extraire des données pertinentes, les analyser pour trouver des informations de vérification confirmant ou infirmant le fait mis en jeu. C’est donc un processus d'analyse d'une information en la confrontant avec une ou des connaissance(s) existante(s) dans le but de pouvoir vérifier son exactitude. Sur le Web, le fact-checking est devenu un format journalistique à part entière. Ce n’est plus un domaine comme jadis réservé seulement aux journalistes. Il est aujourd’hui à la frontière de plusieurs disciplines et requiert cependant, des compétences multiples, allant de l’extraction des données à partir des pages web à la vérification en passant par l’étiquetage, le traitement automatique de la langue naturelle (TALN) et la visualisation des résultats. Malgré cette pluridisciplinarité, la pratique demeure manuelle et a atteint ses limites face aux big data et les réseaux sociaux.
Aujourd’hui sur les 220 sites de fact-checking en ligne, 64 ont échoués soit 34 % [41]. Plusieurs projets sont aujourd’hui entrepris dans le but d’automatiser le fact-checking [96, 97, 98]. A terme, il permettrait d’interroger de façon presque automatique des milliers de sources pour vérifier un fait tenu dans l’espace public et d’en élucider les lecteurs. La tâche reste ardue car des questions demeurent sans réponses.
2. Problématique
La principale question qui se pose ici est de savoir, si cette pratique du fact-checking journalistique est automatisable. En d’autres termes, s’il est possible de mettre en place des modèles et des algorithmes d’aide à la vérification pour les journalistes et surtout en temps réel. Cette problématique centrale peut être décomposée en plusieurs sous-problèmes.
Le premier est la modélisation de la véracité. Comment arriver à des modèles informatiques (algorithmes) capables d’évaluer la véracité d’un fait en tenant compte de son caractère subjectif et temporel? En effet, le calcul de la véracité est un exercice mental consistant à porter un jugement à partir de quelques éléments temporels qui ne sont pas nécessairement représentatifs. Ceci fait que, l’appréhension de la véracité est souvent personnelle et ne fait pas toujours l’unanimité. Elle conduit souvent à une multitude de valeurs potentiellement vraies instantanément ou dans le temps. Aussi, dans la plus part des modèles de fact-checking de la littérature [21] [4] [18] [6], la véracité est déduite des fiabilités des sources qui affirment le fait et inversement, la fiabilité d’une source, de la confiance accordée à ses faits [4] [18]. Ainsi, il était possible de calculer la véracité d’un fait (la confiance)
3
connaissant la fiabilité des sources l’ayant exprimé. Nous considérons ici des sources de confirmations c’est dire les sources qui proposent la même valeur que celle du fait en question. Cependant, qu’en n’est-il des sources infirmant le fait ? Ne sont-elles pas des indices (variables) pertinents dans le calcul de la véracité? Pourtant, une étude de la bibliographie montre que très peu de modèles s’intéressent à la fiabilité des sources infirmant le fait [4] et aucun de ces modèles ne l’utilisent pour déterminer la véracité d’un fait et parallèlement la fiabilité de sa source.
Le deuxième problème incontournable est la carence de jeux de données de test (Dataset) et leur non-conformité avec l’environnement web journalistique. En effet, un algorithme doit toujours être évalué sur des jeux de données afin de montrer son applicabilité en environnement réel. La réussite ou l'échec d’un algorithme s'explique très souvent à partir des caractéristiques des données de test car, les données de test sont souvent des répliques conformes des données réelles de production. Le fact-checking n’en demeure pas moins. Malgré leur importance capitale, seuls quelques datasets de test de fact-checking sont aujourd’hui disponibles [26, 39, 55]. Cette carence s’explique par le fait que l’automatisation du fact-checking est un domaine de recherche assez récent mais aussi du fait que, l’acquisition de jeux de données réelles nécessite un temps de collecte considérable une grande capacité de stockage. Il faut aussi noter que, les jeux de données de test disponibles ne reflètent pas dans leur majorité les caractéristiques de l’environnement réel web journalistique. En effet, ce dernier est caractérisé par : la temporalité des faits, la grande taille des corpus, la liberté de la source à la production et la répartition arbitraire des valeurs vraies. La temporalité des faits exprime l’instant exact où la valeur de la propriété du sujet est produite. Une fois ce paramètre pris en compte, il matérialise l’actualité de la presse, c’est-à-dire, le fait qu’un site internet puisse produire plusieurs fois le même objet avec ou pas la même valeur à des dates distinctes. C’est le cas des contributions, des correctifs et des mises à jour. La taille importante du corpus permet de mesurer le passage à l’échelle. Sa connaissance permettra d’anticiper sur les éventuels problèmes liés à l’optimisation en temps et en ressource des algorithmes. Restreindre un dataset à une dizaine de source ne répond pas à la complexité du web journalisme dans lequel, des milliers de sources donnent des opinions simultanément sur le même sujet. En outre, un média n’est pas toujours sensé produire une valeur pour chaque sujet. Il choisit quotidiennement ses propres sujets d’actualités et, ces derniers peuvent aussi être différents ou identiques à ceux d’un autre média. Ceci fait que, le nombre total d’affirmations (taille du corpus) ne peut être un simple produit entre le nombre de sources et celui de faits. La répartition aléatoire de la valeur vraie d’un fait est arbitraire et ne suit pas une logique.
Le troisième problème est lié à l’extraction, l’identification et le l’étiquetage morpho-syntaxique ou le tagging des faits. C’est évidement la partie du fact-checking web la plus complexe et la plus couteuse en temps et en ressources surtout lorsqu’elle est traitée manuellement. La complexité se
4
situe à deux niveaux : dans l’extraction des données web journalistique et dans le traitement automatique de la langue naturelle (TALN). Pourtant, plusieurs travaux sont menés dans le web scraping [3, 5, 6] et dans TALN deux domaines [67, 69, 70]. Seulement, aucune des solutions proposées aujourd’hui n’est à mesure de reproduire fidèlement les processus manuels de collecte, d’identification et de tagging des faits, opérés par les journalistes. Il s’agit en premier lieu d’identifier les sources supposées fiables, d’extraire et de structurer les articles de presse, de segmenter chaque article en plusieurs affirmations, de sélectionner et d’ordonner les affirmations factuelles et enfin, d’identifier dans chaque affirmation, le sujet, le prédicat et la valeur. Pour le processus d’extraction, il faut noter que les informations les plus pertinentes aujourd’hui pour le fact-checker se trouvent entre autres sources. Or, les données que contiennent ces derniers sont souvent non-structurées ou semi-structurées au meilleur des cas. Cette situation a favorisé la montée en puissance des techniques de web scraping. En effet, un scrapeur est un logiciel qui simule la navigation humaine sur le web pour collecter les données spécifiques provenant de différents sites. Aujourd’hui, peu de travaux sont orientés dans le scraping des données journalistiques web. La seule solution existante [50] est préconfigurée pour la langue anglaise et il nécessite une implémentation pour l’adapter au français. En plus, celle-ci se limite juste à la phase de collecte de l’article dans sa généralité laissant à la charge du fact-checker, la tâche de prétraitement, de segmentation et de structuration. Cette tâche consiste, après segmentation de l’article en affirmation et une étude morphosyntaxique de chaque affirmation, à identifier et à étiqueter automatiquement le (s) sujet (s), le (s) prédicat (s) et la (les) valeur (s). Malgré les avancées notables du TALN, réaliser une analyse linguistique sur les faits en langue française demeure aujourd’hui une véritable problématique. D’une part, les taggers actuels s’accordent mal avec la définition du fait en fact-checking et d’autre part, la complexité de la langue française réduit considérablement leurs performances.
3. Contributions
Quatre propositions sont alors détaillées dans cette thèse comme des contributions majeures dans l’automatisation du fact-checking dans le contexte web journalistique :
• JFact : Une API JAVA faisant office de générateur automatique de datasets synthétiques à
valeurs numériques pour les algorithmes de fact-checking à fort conflit d’opinions. L’objectif visé ici est de reproduire le comportement de l’environnement web journalistique et produire rapidement des datasets de tests personnalisables en fonction des besoins en complexité. Cette personnalisation peut se faire suivant le nombre de sources, le nombre de sujets, le nombre de propriétés, la répartition de la valeur vraie etc ;
5
• SnVera: Un algorithme de vérification des faits basé sur la confrontation des opinions, c’est-à-dire, l’utilisation de la connaissance du domaine comme élément clé dans le processus de fact-checking. Dans notre approche, nous pensons que la connaissance des sources infirmant le fait (les sources de contestation) est un élément clé dans le calcul de la véracité. Cette approche consiste donc à faire ressortir la véracité d’un fait en utilisant d’autres faits du corpus ;
• FactExtract : Un extracteur automatique d’article et d’affirmations factuelles à partir de la presse en ligne. C’est un moteur de web scraping d’affirmations factuelles interconnecté à des sources de données (des sites web d’informations) externes. Il est constitué de deux modules : un module d’extraction d’articles (MEA) et un module de segmentation et de fusion (MFA) ;
• FactTagger : un outil de segmentation et d’étiquetage automatique de faits dans les discours en langue française. L’intérêt est clairement de permettre à une machine de pouvoir reconnaître seule une affirmation factuelle dans un discours mais aussi et surtout, d’offrir la possibilité d’instaurer des services automatiques de fact-checking comprenant le sens du fait.
4. Plan du manuscrit
Ce manuscrit est organisé en cinq grandes parties hormis l’introduction générale et la conclusion. Dans l’introduction générale nous présentons le contexte de notre étude, la problématique et l’annonce du plan du manuscrit. Une synthèse des contributions et les perspectives sont exposées dans la conclusion générale.
Chapitre 1 : Le fact-checking
Dans ce chapitre, nous présentons une étude détaillée sur le Fact-checking dans le contexte web journalistique. Dans la première section nous étudions le journalisme à l’ère du Big Data et de l’Open data. Nous présentons dans la section suivante les contours du fact-checking : l’historique, les concepts de base, les enjeux, les défis et la pratique actuelle du fact-checking. Enfin, la dernière section de ce chapitre expose une étude détaillée sur l’automatisation du Fact-checking.
Chapitre 2 : Etat de l’art
Dans ce chapitre, nous présentons l’état de l’art de l’automatisation du Fact-checking dans le contexte web journalistique. Nous commençons par un état de l’art des datasets de tests et des techniques de web scraping. Nous poursuivons par une étude des algorithmes et approches de vérification des faits. Nous finissons ce chapitre, par une présentation des tentatives actuelles d’automatisation du fact-checking.
6
Dans la section 1 de ce chapitre nous présentons notre première contribution, un extracteur automatique d’articles et d’affirmations factuelles dans les articles de presse en ligne nommé FactExtract. La dernière section présente un étiqueteur de fait en langue française.
Chapitre 4 : JFact et SnVera
Nous présentons dans ce chapitre deux contributions : JFact et SnVera. JFact est un générateur de datasets synthétiques. SnVera est un algorithme de vérification des faits. Dans la première section nous présentons JFact et ses résultats. La section 2 est consacrée à l’algorithme SnVera, une amélioration de SenFact [131].
Chapitre 5 : Plateforme de Fact-checking web proposée
Dans ce chapitre nous présentons une architecture générale d’une plateforme de fact-checking web dont l’ensemble des composants ont été présentés comme nos contributions. La plateforme utilise des données textuelles des sites web journalistiques, des encyclopédies et des sources scientifiques comme corpus. Ces sites web sont enregistrés et paramétrés au départ. Cependant, d’autres sites web peuvent être ajoutés dans le temps.
7
C
HAPITRE
1 :
L
E FACT
-
CHECKING
Sommaire
1.1. Introduction ... 8
1.2. Le journalisme à l’ère du big data et de l’open data ... 8
1.2.1. Le Big Data ... 9
1.2.2. L’open Data ... 10
1.2.3. Le datajournalisme ... 11
1.3. La prolifération des fakenews ... 12
1.3.1. Définitions ... 12
1.3.2. Les formes de fakenews dans le journalisme ... 13
1.4. Le fact-checking ... 16 1.4.1. Definitions ... 16 1.4.2. Historique du fact-checking ... 19 1.5. Le fact-checking web ... 21 1.6. Le fact-checking automatique ... 24 1.6.1. Les enjeux ... 24
1.6.2. Les processus de fact-checking automatique ... 27
8
1.1. Introduction
Au moment où certains prônaient la mort du journalisme [40], ce dernier a su évoluer en multipliant ses formes d’existence et en suivant l’avancée fulgurante des technologies de l’information et de la communication [19]. Cette évolution vers un journalisme de données (Datajournalisme) est d’autant plus nécessaire avec l’avènement du web 2.0 et du web des objets. En effet, avec les Forums, les blogs, les wikis, les réseaux sociaux et les plateformes d'échanges, le web 2.0 donne la main aux internautes dans de nombreux aspects de leur vie en ligne. C’est maintenant à eux de produire et de partager du contenu. Aussi, l'intégration de tout appareil interrogeable ou contrôlable à distance, dans le monde du World Wide Web, est d’une part, responsable de l’accroissement exponentiel du volume de données générées sur le réseau et à l'origine du Big Data. Face à ces mutations du web, le journalisme a subi des transformations très profondes dans les activités, dans le fonctionnement et dans les habitudes touchant ainsi à l’organisation même de l’information dans toutes ses phases : depuis la sélection de l’information, sa transformation en actualité jusqu’à sa publication. Cependant, ces transformations ne sont pas sans conséquences. Elles ont impacté sur la qualité de l’information produite et une des illustrations directes est, la prolifération de fausses informations dans la presse surtout celle en ligne. C’est d’ailleurs pour lutter contre ces fausses informations (fakenews), qu’un nouveau genre journalistique est apparu : le fact-checking ou « la vérification des faits ».
Dans ce chapitre, nous présentons une étude détaillée sur le fact-checking dans le contexte journalistique. La première section de ce chapitre est consacrée au big data, à l’open data, au datajournalisme et à la prolifération des fausses informations. La deuxième section est consacrée à l’étude détaillée de la pratique du fact-checking journalistique : les définitions, l’historique, les enjeux. Nous finissons ce chapitre par une présentation de fact-checking automatisé.
1.2. Le journalisme à l’ère du big data et de l’open data
Aujourd’hui, le journalisme tend à utiliser de plus en plus les big data pour les « faire parler ». Collecter, trier, et analyser cette masse de données (big data) nécessite cependant des compétences diverses et pointues. Toutefois, face à cette diversité des compétences requises, des coopérations voient souvent le jour entre des journalistes et de nombreux professionnels de la donnée numérique (informaticiens et statisticiens). Cette collaboration a permis de mieux répondre aux exigences de rapidité et de performance du traitement d'informations propres aux industries médiatiques contemporaines [78]. Le datajournalisme témoigne ainsi du rapprochement du monde de la presse et du monde du traitement automatique de l’information.
9
1.2.1. Le contexte des Big Data
Les Big data sont de grosses quantités de données accumulées et traitées à une haute vitesse, issues de sources hétérogènes et dont les actifs exigent une nouvelle approche qualité dans l’utilisation. Il est aussi souvent défini suivant la règle des 5V ou des 5 dimensions [72]. Les 5 V sont les suivants : le Volume, la Vélocité, la Variété, la Valeur et la Véracité.
Le Volume est l’aspect quantitatif des Big Data. Il fait référence à la masse des données accumulée. Ainsi du gigaoctet (109 octets) nous sommes passés aujourd'hui au zettaoctet (1021 octets). L'évolution de cette production est exponentielle : 90% des données actuelles ont été produites durant les deux dernières années [72]. Avec le zettaoctet, l’homme est entré dans le domaine du «big data» poussant les spécialistes à inventer des unités de mesure au fur et à mesure. Pour bien comprendre le phénomène, il est intéressant de savoir que 90% des données actuelles ont été produites durant les deux dernières années [72]. Il suffit de penser à tous les e-mails, tweets, photos, vidéos, les données des capteurs que nous produisons et partageons chaque seconde. Deux phénomènes sont à l’origine
de ce flux massive de données numériques (data-déluge): le cloud computing et la multiplication des objets connectés. En effet, le Cloud computing ou la démocratisation des moyens de stockage et de traitement désigne à la fois les applications en tant que services sur internet, le matériel et les logiciels qui permettent de fournir ces services. Il a permis de rendre accessible et exploitable des données et des applications à travers le réseau internet. Les objets connectés en réseau eux, pourraient compter jusqu’à 38,5 milliards d’ici 2020, soit une augmentation de 285% par rapport au chiffre actuel de 13,4 milliards [74].
La Variété matérialise la diversité des sources, de format et de l’usage. En effet, ces données proviennent de diverses sources : des entreprises, des gouvernements ou des particuliers. Aussi, elles ne sont plus forcément structurées selon un schéma rigide (la table) mais peuvent être de formats divers (texte, micro-texte, image, photo, vidéo, audio etc.) rendant ainsi très complexe la manipulation. Ce format classique en données structurées est celui des bases de données relationnelles classiques. Les usages faits sur ces données sont aussi très variés, allant de l’analyse à la prédiction en passant par la prise de décisions.
La vélocité (la vitesse) désigne à la fois la rapidité d’accumulation mais aussi l’extrême puissance de traitement nécessaire pour manipuler ces données numériques en quasi réel. Pour exemple, pensons juste aux millions de messages, vidéos et photos lancés sur un réseau social par minute. L’analyse de ses données nécessite des logiciels puissants avec une extrême rapidité. C’est dans ce contexte qu’interviennent les «supercalculateurs» dans les centres de données (datacenters). Les capacités de traitement sont pour l’instant à la traîne derrière les capacités de collecte. Plusieurs
10 techniques sont utilisées aujourd’hui pour le développement des infrastructures de traitement rapide des données. Nous pouvons citer la miniaturisation des microprocesseurs et le parallélisme. En effet, grâce à la miniaturisation, il est possible de faire plus sur un espace identique. Le parallélisme permet ainsi de découper un problème en petits morceaux, qui seront résolus par différentes machines.
La valeur symbolise la capacité intrinsèque de la donnée à générer du profil. Il est aussi primordial que les entreprises évaluent la rentabilité d’une récolte de données. Car, il est bien beau d’avoir accès à une masse de données mais encore faut-il à les valoriser. Nous parlerons alors de valeur d'impact sur un contexte, de valeur de modélisation, de valeur de prédiction, de valeur de management, de valeur économique ou de revente... [72]. Il est bien de noter aussi que la valeur d’une donnée est relative au temps et au contexte d’interprétation.
La véracité fait référence à la fiabilité des données. Elle permet de s’assurer que les informations sur lesquels porte notre étude sont déjà vérifiées ou sont dignes de confiance. En effet, de gros volume de données doivent être interprétées avec prudence surtout si elles doivent être utilisées ultérieurement à des fins cliniques. Toute interprétation utilisant de fausses données peut engendrer des turbulences sur l'ensemble des systèmes associés et provoquer des sinistres conséquents lorsque des décisions sont prises [72]. C’est effectivement sur cette dernière dimension des big data (la véracité) que se porte notre travail.
Aujourd’hui, les techniques et les technologies du big data ont apporté des mutations considérables aux pratiques économiques, sociales et politiques. Ils ont modifié notre rapport au monde en repoussant parfois certaines limites. Cependant, le mode d’accès « ouvert » (Open data) à ces données a aussi été un facteur non négligeable dans l’émergence du journalisme de données.
1.2.2. L’open Data
L’open data désigne à la fois une injonction à la mise à disposition des données issues du secteur public ou du secteur privé et un processus d’ouverture progressive de telles données qui se traduit généralement par leur publication via des catalogues et des portails dédiés [78]. L'ouverture des données publiques s’inscrit dans des politiques de créativité, car elle fait sortir les données de leur contexte initial de production pour leur offrir un nouveau cadre d’interprétation et de traitement dans de nouveaux contextes grâce à la possibilité du croisement des données, par d’autres acteurs [81]. L’objectif principal visé est, de favoriser la réutilisation des données par un nombre illimité d’utilisateurs afin de les transformer en informations. Ces « données ouvertes » sont souvent diffusées de manière structurée selon une méthode et une licence ouverte garantissant son libre accès et sa réutilisation par tous, sans restriction technique, juridique ou financière.
11 Face à cette forte disponibilité des données, tous les secteurs engagent des mutations pour intégrer la « data » à leur modèle. L’entreprise adopte ainsi un nouveau modelé : le modèle « Data centric ». En effet, le modèle data centric préconise que l’entreprise se met en capacité de tirer de la valeur de toutes les données, qu’elles soient internes, externes ou non encore exploitées. Or, pour y arriver, l’entreprise doit modifier son approche actuelle de la donnée. La logique consiste à mettre en œuvre une structuration autour de la donnée afin d’apporter une nouvelle agilité au système d’information, en fournissant un espace de stockage et d’analyse global de toutes les données, qu’elles soient brutes ou raffinées, issues des sources internes ou en provenance de sources externes [82]. C’est dans ce contexte que s’est développée le datajournalisme ou le journalisme de données. Les données constituent pour les data journalistes à la fois une source d’information privilégiée et un outil de la construction d’une narration originale.
1.2.3. Le datajournalisme
Le datajournalisme implique la jonction des forces d’un assemblage hétérogène de compétences, de différents acteurs (journalistes, analystes, informaticiens, designers …) et de différents secteurs d’activités [3]. Il ne s’oppose pas au journalisme traditionnel, mais propose une autre manière de faire qui utilise des données numériques comme corpus. En effet, l'usage du « data » est un atout éditorial puissant pour le travail du journaliste. Tous les événements, les conflits, les catastrophes naturelles, les mouvements sociaux ou politiques, laissent toujours des traces publiques dans les réseaux, dont l'analyse peut s’avérer très utile. Recueillies, structurées et éclairées en temps réels, ces données révèlent les influenceurs, les émotions, les arguments et les communautés en jeu.
Il s'agit d'une pratique journalistique fondée sur le recueil et les traitements statistiques et algorithmiques des données, ce qui témoigne d'un rapprochement du monde de la presse et du monde de la programmation [78]. Au-delà des pratiques fondamentales du journalisme, à savoir rassembler des faits, les analyser, les transformer pour informer le public, le data journalisme comprend des dimensions inédites impliquant des compétences dans le domaine informatique [80]. Il peut être divisé en trois principaux processus : la collecte, le filtrage et la visualisation (Voir figure 1).
Figure 1. Tâches du Datajournalisme
•Indentification des sources •Extraction des articles Collecte de données •Selection des articles pertinents •Analyse •Verification Filtrage •Presenation des resultats •Publication de l'article Visualisation
12 La phase de collecte de données consiste d’abord, à identifier les sources de vérification, c’est-à-dire, les sources supposées à priori fiables puis, de rechercher dans celles-ci, les éléments pouvant consolider l’argumentation du datajournaliste. Ces données numériques collectées constituent avant tout un support permettant d’appuyer et d’argumenter une investigation plus globale. Lors de la phase d’analyse, les données collectées sont triées suivant leurs pertinences, analysées et vérifiées. Une fois cette analyse terminée, l’information qui en est issue est publiée suivant une visualisation appropriée à la cible.
La dimension participative est aussi fondamentale dans le datajournalisme où les journalistes via des plateformes de collaboration, sollicitent les internautes pour des contributions, des veilles ou des alertes sur des données jugées inexactes ou simplement pertinentes. Il a ainsi fait émerger de nouvelles branches journalistiques telles que les « journalistes programmeurs », les « journalistes hackers » et les « journalistes de vérification des faits».
Malgré cette diversité, la véracité des faits publiés demeure une problématique urgente. En effet même si le web est une large source de données il est bien de noter que tout n’est pas bon à prendre. Il est toujours bien de contrôler la qualité, la pertinence des données et la fiabilité des sources. Le datajournaliste doit désormais avoir une agilité et un flaire pour tirer et analyser la véracité des faits qui lui parviennent. Il devient ainsi un « Monsieur Tri » [4]. D'une manière générale, il doit rester vigilant par rapport à la crédibilité des données utilisées ou mises en open data. Ces données sont souvent élaborées dans une visée communicationnelle. De ce fait, le data journaliste doit accompagner toute exploration de l'open data par des investigations traditionnelles et souvent manuelles, basées sur l'enquête, la vérification des faits et la confrontation des sources. Sans cette vérification des faits en amont, l’information tirée de la donnée pourrait être fausse et, entrainer des répercutions graves dans la prise de décision ou dans l’opinion. Un travail qui hélas, n’est pas chose aisée et n’est pas toujours effectué vue le volume de données qui lui parviennent. Cette situation favorise alors une prolifération des fausses informations dans l’espace médiatique.
1.3. La prolifération des fakenews
1.3.1. Définitions
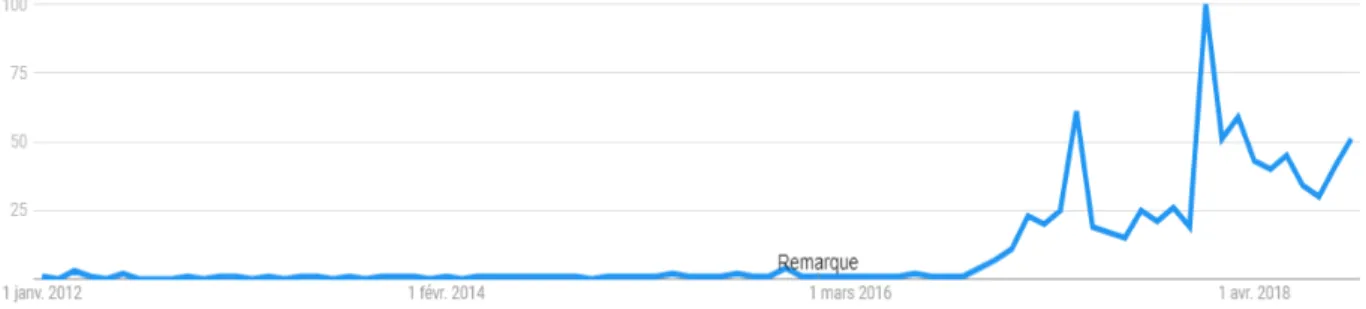
S’il est un terme qui a connu un succès en un temps record à partir de septembre 2016, c’est bien celui de « fakenews ». Ce terme a été popularisé comme en atteste la courbe mondiale de recherche
13 du terme sur Google2, avec un pic en janvier 2018, bien après l’élection américaine (Voir figure 2). Le terme fakenews a aussi été choisi comme mot de l’année 2017 par le Collins Dictionary3.
Figure 2. Évolution de la recherche du terme « fakenews » dans le monde selon Google trends, depuis le 1e r janvier 2012
Un fakenew ou infaux en français est une information fausse créée de toutes pièces avec aucun fondement de vérité, c’est-à-dire, des informations fallacieuses, trompeuses ou incorrectes, prétendant être de réelles informations concernant la politique, l’économie ou la culture [85]. Les origines ou causes présumées des fakenews, sont fréquemment les organes d’information et internet [86]. Son seul but est de faire passer pour vrai ce qui est faux d’une part et à manipuler ou à déstabiliser dans la perspective de faire réagir les personnes qui les lisent d’autre part. Elle peut aussi créer ou renforcer une rumeur [83]. Elle apparait par contre comme une information vraie dès l’instant qu’elle se présente souvent sous les traits d'un article de presse classique [84].
La prolifération des fausses informations dans l’espace médiatique n’est pas un phénomène nouveau. Ce qui l’est en revanche, c’est son ampleur et la vitesse avec laquelle les fausses informations se répandent, grâce aux médias numériques. Pourtant, au début de l’internet, les fausses informations dans le journalisme étaient souvent involontaires et issues de négligences ou d’erreurs. Elles sont aujourd'hui souvent diffusées de manière volontaire, c’est-à-dire, créée par un individu ou un groupe d’individus identifiable(s) ou non, dans un but humoristique, commercial, idéologique ou manipulatoire. Elles sont de diverses formes et peuvent s’appuyer sur des événements vrais qui ont été détournés.
1.3.2. Les formes de fakenews dans le journalisme
1.3.2.1. Le Buzz
Un Buzz est une fausse information souvent utilisée dans un but commercial et s’appuyant le plus souvent sur des faits existants. Son seul but est de générer du trafic donc des revenus publicitaires. Il
2 https://trends.google.fr/trends/explore?date=2012-01-01%202018-10-20&geo=FR&q=Fake%20news
14 se focalise sur des titres incitatifs et de mots-clés stratégiques dans le texte afin d’attirer les lecteurs. Sa dangerosité relève du contenu. Contrairement au Framing, le Buzz s’appuie sur un titre plus que positif et met en exergue des mots destinés à plaire au public [86].
1.3.2.2. Le Framing
Le Framing est un titre négatif ou non contextualisé d’un article presse existant basé sur des faits réels. Il est destiné à créer un climat hostile en mettant l’accent sur les titres négatifs. Le procédé consiste à sélectionner et à diffuser massivement des cas isolés d’un ensemble, de sorte que nous ayons l'impression que le comportement de certains membres d'un groupe aurait des effets sur le comportement de l'ensemble du groupe. La dangerosité du Framing réside dans l’existence des faits mis en avant et des titres mensongers utilisés pour les symboliser.
1.3.2.3. La ré-information
La ré-information est souvent le fruit d’une pression ou de la concurrence. Elle est souvent fréquente lors des directes ou des couvertures d’évènements inattendus tels que des attentats, le décès d’une haute personnalité. Dans ces cas de figure, le risque que les informations soient accompagnées de fakenews non confirmés est très grand. Pour répondre à la demande et jouer sur la concurrence, les médias surtout ceux en ligne sont soumis à une énorme pression et diffusent parfois des informations non vérifiées des réseaux sociaux [85].
1.3.2.4. La rumeur
La rumeur est une fausse information non vérifiée qui ne s’appuie sur aucun élément concret avéré et porté à l’endroit d’une personne ou d’un groupe de personnes, d’un événement ou d’un ensemble d’événements, etc. Elle peut aller jusqu’à un dénigrement, à une diffamation ou à une calomnie. Le dénigrement est une attaque à la réputation d’une personne. La diffamation est une allégation qui porte atteinte à l’honneur et à la considération d’une personne. La calomnie consiste à dénaturer sciemment quelque chose par de fausses interprétations. La rumeur est le socle des magazines people.
1.3.2.5. Le Canular ou hoax
Un canular est une fausse nouvelle sous la forme d’une blague. Cette farce vise à jouer avec la crédulité de ses destinataires. Les canulars ont une vocation généralement humoristique, même si certains canulars peuvent tendre vers la rumeur. L’exemple typique de canular est un poisson d'avril. L’objectif n’est pas souvent de nuire à une personne ou à un groupe de personnes mais plutôt d’amuser. Un des sites web pionniers dans la lutte contre les canulars sur internet est le site web francophone hoaxbuster.com4.
15 1.3.2.6. Le complot
Le complot une situation ou un événement (souvent politique) qui est expliqué (e) par une conspiration secrète de quelques personnes. Les arguments rationnels sont souvent ignorés et des mensonges sont utilisés comme preuves d'une existence d'un complot. L’objectif est de faire concurrence aux faits officiels établis. Sa principale caractéristique est que le complot ne repose pas sur des données disponibles. Les acteurs du complot vont se servir de tous les indices qui parlent en faveur de leur théorie, tout en dissimulant ceux qui vont à l'encontre. Aussi, le manque de preuves est considéré comme une preuve supplémentaire.
1.3.2.7. Les fausses citations
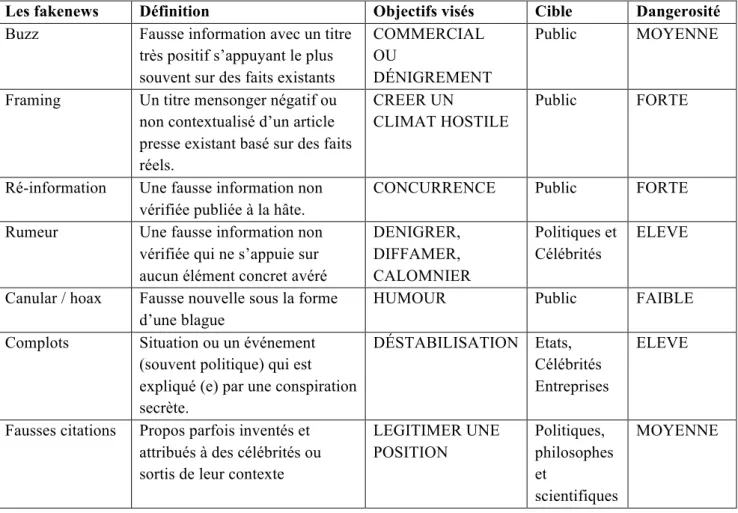
Les fausses citations sont des propos parfois inventés et attribués à des célébrités, à des savants ou à des politicien(ne)s et qu'ils n'ont pas tenus ou qui sont sortis de leur contexte. La notoriété intellectuelle des philosophes et scientifique est souvent utilisée pour légitimer une certaine vision du monde. Elles sont très faciles à vérifier en quelques clics sur Google. Le tableau 1 suivant montre un récapitulatif des formes de fakenews dans le journalisme [136]. Pour chacune de ces formes, les objectifs visés, la cible ainsi que le niveau de dangerosité sont dégagés [84, 86, 87]. Vous remarquerez sans doute que, les complots et les rumeurs constituent les formes de fakenews les plus dangereux.
Tableau 1 Les formes de fakenews
Les fakenews Définition Objectifs visés Cible Dangerosité Buzz Fausse information avec un titre
très positif s’appuyant le plus souvent sur des faits existants
COMMERCIAL OU
DÉNIGREMENT
Public MOYENNE
Framing Un titre mensonger négatif ou non contextualisé d’un article presse existant basé sur des faits réels.
CREER UN
CLIMAT HOSTILE
Public FORTE
Ré-information Une fausse information non vérifiée publiée à la hâte.
CONCURRENCE Public FORTE
Rumeur Une fausse information non vérifiée qui ne s’appuie sur aucun élément concret avéré
DENIGRER, DIFFAMER, CALOMNIER Politiques et Célébrités ELEVE
Canular / hoax Fausse nouvelle sous la forme d’une blague
HUMOUR Public FAIBLE
Complots Situation ou un événement (souvent politique) qui est expliqué (e) par une conspiration secrète.
DÉSTABILISATION Etats, Célébrités Entreprises
ELEVE
Fausses citations Propos parfois inventés et attribués à des célébrités ou sortis de leur contexte
LEGITIMER UNE POSITION Politiques, philosophes et scientifiques MOYENNE
16 Tandis que, partout dans le monde, se multiplient les signes de la prolifération des fakenews dans les medias, le débat sur les moyens de lutter contre les fakenews est appelé à s’intensifier. Cependant, il est brouillé par une mauvaise compréhension du phénomène, de ses origines et de ses réels dangers. Néanmoins, une branche du datajournalisme, les fact-checking, s’occupe spécifiquement de l’aspect véracité des faits. Cette nouvelle forme de journalisme de données se présente aujourd’hui comme étant l’alternative crédible voir même, un acteur incontournable pour le passage à un journalisme augmenté.
1.4. Le fact-checking
1.4.1. Definitions
1.4.1.1. Affirmation factuelle
Un article de presse est une compilation d’affirmations (opinions et/ou arguments) à priori non factuelles, c’est-à-dire, une opinion sur un sujet bien défini. Elle est produite par une source (site internet, encyclopédie, blogs …) à un instant bien précis. En effet, une opinion est un jugement, un avis personnel, une manière de penser ou de voir une chose. Contrairement à un fait, une opinion n’est pas toujours sensée avoir lieu ou basée sur des données réelles. Raison pour laquelle, la pertinence à la vérification d’une opinion n’est pas toujours importante.
Une affirmation factuelle est une phrase (une opinion de l’auteur) dont la pertinence à l’étude de sa véracité est importante [22]. L’algorithme de classification des faits ClaimBuster par exemple [23], catégorise les phrases dans les discours en trois groupes : les NFS, les UFS et les CFS. Les NFS (Non-Factual Sentence) sont des phrases sans revendications factuelles, c’est-à-dire, potentiellement vraie dont intitule de la soumettre à une vérification. Les UFS (Unimportant Factual Sentence) sont des phrases factuelles mais non pertinentes à la vérification pour le public. Les CFS (Check-worthy Factual Sentens) sont les phrases factuelles et dont l’étude de la véracité est très importante pour le public.
1.4.1.2. Les faits
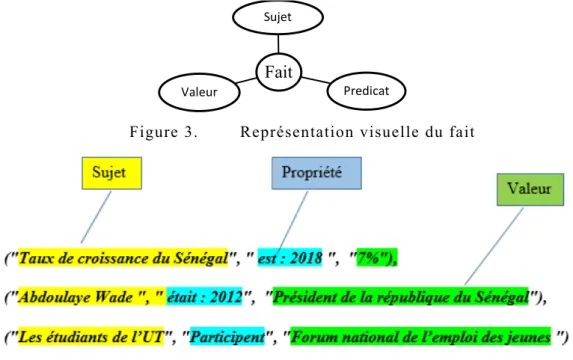
Un fait est une affirmation factuelle (CFS) objective qui a déjà été vérifiée ou qui peut l'être sur la base de sources fiables. Cette vérification ne peut être possible que si, l’affirmation factuelle en question contient les éléments de base suivants :
- Un sujet : Il délimite l’étude et permet d’identifier la chose ou l’individu sur lequel porte l’affirmation. Par exemple : Sénégal, Macky SALL, Taux de croissance du Sénégal, Liverpool etc ;
17 - Un prédicat : C’est un attribut, une propriété du sujet. Par exemple : Etre indépendant, Avoir
gagné, Etre égal, remporter etc ;
- Une valeur : C’est une donnée (textuelle ou numérique) affectée à la propriété du sujet. Par exemple : 1960, Elections présidentielles de 2012, 7%, la ligue des champion de 2019.
Le tableau 2 suivant montre un exemple de 4 affirmations factuelles décomposées en triplet : sujet, prédicat et valeur.
Tableau 2 Exemple d’affirmations factuelles.
Affirmation Sujet Prédicat Valeur
Le Sénégal est indépendant depuis 1960.
Sénégal Etre
indépendant
1960
Macky SALL a gagné les
élections présidentielles de 2012
Macky SALL Avoir gagné Elections
présidentielles 2012 Taux de croissance du Sénégal
est de 7% en 2018
Taux de croissance du Sénégal
Etre : 2018 7%
Liverpool remportera la ligue des champions 2019.
Liverpool Remporter : 2019
Ligue des champions
Un fait est toujours défini dans le temps (TimeStamp). En prenant en compte cette notion temporelle, le fait est modélisé sous la forme du triplet <sujet, prédicats : TimeStamp, valeur> où TimeStamp désigne l’instant précis où la propriété du sujet a pris la valeur (voir figures 3 et figure 4). La figure 3 montre une modélisation en triplet d’un fait. La figure 4 montre trois exemples de faits avec pour chacun son sujet, sa propriété et sa valeur à une date bien définie.
Figure 3. Représentation visuelle du fait
Figure 4. Illustration de faits
Fait
Sujet
Predicat Valeur
18 Un fait peut apparaitre à priori avec l’une des trois formes suivantes :
• Sa véracité est confirmée : Le fait est vrai et il contient suffisamment de preuves à l'appui. L’étude de sa véracité n’est plus utile ;
• Sa véracité est apparente : L'allégation semble exacte, mais doit être clarifiée ou mise en contexte. L’étude de sa véracité n’est plus nécessaire afin de consolider la supposition ; • Sa véracité est rejetée : L'allégation est fausse, mais doit être clarifiée ou mise en contexte.
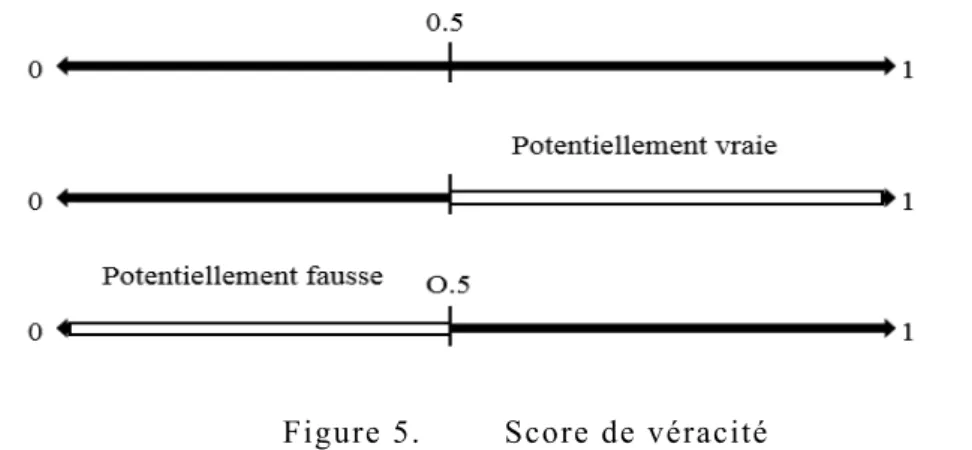
L’étude de sa fausseté n’est plus nécessaire afin de consolider la supposition. 1.4.1.3. La véracité d’un fait
La véracité d’un fait exprime la probabilité pour que le fait soit vrai. Dans la littérature, Elle est souvent notée !(#) ou % & . Un fait vrai sera celui sélectionné comme étant le plus digne de confiance parmi tous les faits candidats. Le terme confiance en un fait est aussi souvent utilisé pour désigner la véracité d’un fait. Il est bien de noter que nous parlons ici de la confiance décidée (Trust en anglais) et non de la confiance assurée (Confidence en anglais). La confiance décidée est un aspect « système » dont l’obtention peut durer dans le temps. La confiance assurée est une attitude, une décision prise à court terme face à un risque [99]. Dans la littérature [1, 6, 52, 58], la véracité est calculée en utilisant la fiabilité des sources ayant exprimées le fait.
La véracité est souvent modélisée sous la forme d’un score compris entre 0 et 1 avec un seuil de coupure entre le faux et ceux vrai fixé souvent à 0,5. Ce n’est donc pas une valeur bivalente (vraie ou fausse). Ainsi, un fait vrai aura un score de véracité !( # ≅ 1 et un fait faux !( # ≅ 0 (voir
figure 6).
Figure 5. Score de véracité
L’algorithme SUMS [6] par exemple adopte une procédure itérative dans laquelle le calcul de la confiance !( (#) à un fait f à l’itération i est déduit de la somme des fiabilités accordées aux faits qui
lui sont attribués et inversement (voir formule 1). Ce qui fait que, plus un fait est confirmé par des sources fiables plus sa véracité sera élevée de même, plus un fait sera infirmé par des sources fiables plus sa fiabilité sera réduite.
19
!( # = -( . / ∈ 12
(1)
1.4.1.4. La fiabilité d’une source
La fiabilité exprime la probabilité de la source à fournir des faits vrais. Un plus haut poids de fiabilité indique que la source est plus fiable et que l'information provenant de celle-ci est plus digne de confiance. Dans la majorité des modèles [1, 6, 52, 58], la fiabilité est fonction de la véracité. C’est-à-dire, une source sera d’autant plus fiable que lorsqu’elle produit des faits vrais. Voici par exemple la notation utilisée par l’algorithme TrustFinder [58] (voire formule 2) pour calculer la fiabilité -( . de la source s où %(<= & désigne la confiance accordée au fait c de la source s à l’itération
précédente (i-1) et |!/| l’ensemble des faits attribués à la source s.
-( . = ? ∈@A%(<= &
!/
(2)
Dans ce modelé la fiabilité -( . d’une source à l’itération i est retrouvée en sommant la véracité
%(<= & des faits à l’itération précédente i-1 le tout divisé par le nombre de faits produits par la source
|!/|.
1.4.1.5. Le fact-checking
La vérification des faits est au fondement du journalisme. Le fact-checking est devenu un genre à part entière au sein de certaines rédactions. Cette nouvelle forme journalistique consiste à interroger plusieurs sources de données, analyser les résultats pour déterminer la véracité ou non d’un fait. C’est donc un processus d'analyse d'une information en la confrontant avec une ou des connaissance(s) existante(s) dans le but de pouvoir vérifier son exactitude.
Le journaliste fact-checker effectue un travail d’édition censé privilégier la qualité à la quantité. Cette pratique est en réalité apparue aux États-Unis à compter des années 2000. Elle ne cesse de se développer grâce au travail de réseau IFCN (International Fact-Checking Network) basé à l’institut Poynter5, en Floride.L’objectif premier du fact-checking est d'identifier la vérité, parmi un ensemble
de propositions (faits) potentiellement contradictoires [6].
1.4.2. Historique du fact-checking
Le fact-checking n’est rien d’autre qu’une forme de journalisme d’investigation caractérisé par son objectif, qui est de dénoncer les abus et les atteintes à l'intérêt public. En se limitant à la simple vérification des faits politiques, l’histoire du fact-checking va alors au-delà des années 2000. Il a déjà été expérimenté, plus discrètement, sous d’autres formes [10]. En effet, il émane directement de la
20 tradition de vérification des faits dans le journalisme américain avec les journalistes d’investigation. Plus précisément, sa création remonte à 1923 avec la création du magazine Time6 qui recruta à
l’époque les premiers Fact-Checkers (journalistes des faits). A l’origine, le travail du fact-checker consistait à vérifier avant publication (à priori) les noms, dates, chiffres, citations et faits dans l’ensemble des articles du magazine. Il s’agissait de recontacter les sources à l’origine de tel ou tel fait puis de faire une confrontation avec les informations de l’auteur avant la publication de l’article.
Le fact-checking réapparait entre 1960 et 1970 sous une autre forme : le «watchdog journalism » ou journalisme de surveillance [88]. Son rôle fut à l’époque, de fournir aux citoyens des informations vérifiées pour lutter contre les abus et les fausses informations venant des institutions ou de la société même. Ce nouveau genre journalistique mena ardemment un combat pour le public à l'égard des puissants. Un des grands succès du « watchdog journalism » fut le Watergate [90]. Du travail de terrain, qui constituait auparavant la source principale de ses informations, il doit désormais avec l’arrivée du web, faire preuve de nouvelles compétences, plus connectées.
Depuis l’apparition du web en 1990 et du premier navigateur trois ans plus tard, le journalisme en ligne s’est considérablement développé. L’arrivée de cette presse en ligne, entraina une baisse considérable des effectifs des journalistes dans les groupes de presse. Le fact-checking prend alors une nouvelle tournure et réapparait sous un nouveau format : le fact-checking web. Celui-ci consiste alors à faire le même travail mais cette fois ci avec un corpus diffèrent et après publication de l’article (a posteriori). Aussi, le fact-checker web n’est plus forcément un journaliste interne au média mais, un indépendant ou un simple internaute.
La première tentative de fact-checking web a vu le jour en 2001 aux Etats unis avec le site
Spinsanity.org7 dont les auteurs vérifiaient les déclarations trompeuses de la presse [89]. Ce premier
projet de fact-checking citoyen fut abandonné en 2005. Le fact-checking web tel que nous le connaissons aujourd’hui est apparu en 2003 aux Etats unis avec le site FactCheck.org8. Il est suivi du populaire Politifact.com qui en plus de vérifier les faits, propose aujourd’hui entre autres un baromètre de mesure de la véracité des citations politiques le « Truth-O-Meter » et un autre pour mesurer si les promesses de campagnes des présidents américains sont tenues : le « Obameter9 » et «
Trump-O-Meter 10». Le fact-checking est popularisé en 2009 par la remise du prix Pulitzer au site
6 http://time.com/ visité le 10/07/2018 7 http://spinsanity.org/about/ visité le 10/07/2018 8 https://www.factcheck.org/ visité le 10/07/2018 9 https://www.politifact.com/truth-o-meter/promises/obameter/browse/ visité le 10/07/2018 10 https://www.politifact.com/truth-o-meter/promises/trumpometer/browse/ visité le 10/07/2018