Directoryless shared memory coherence using execution migration
13
0
0
Texte intégral
Figure

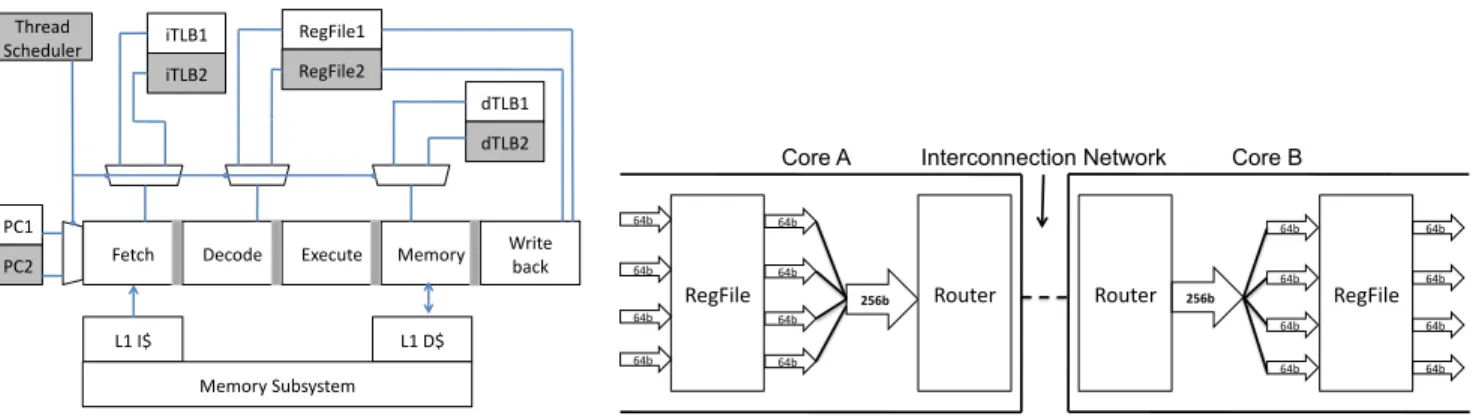
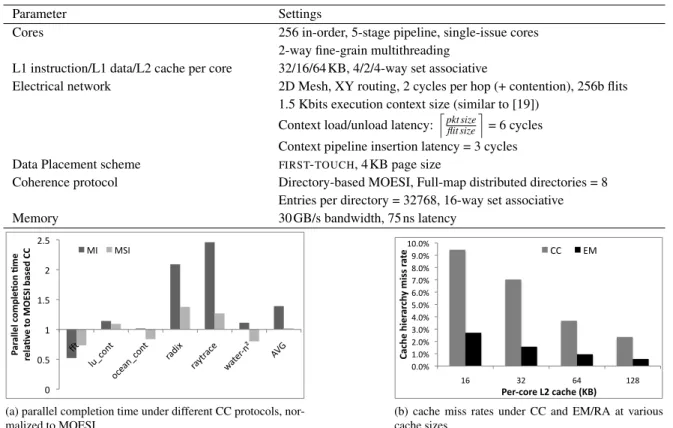
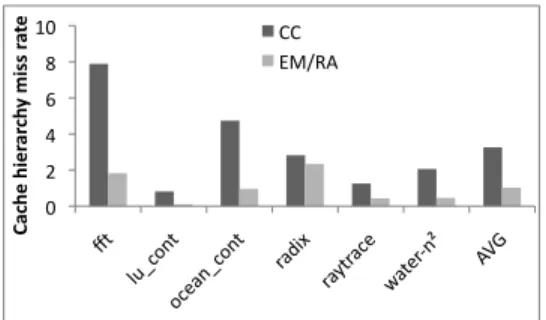
+4
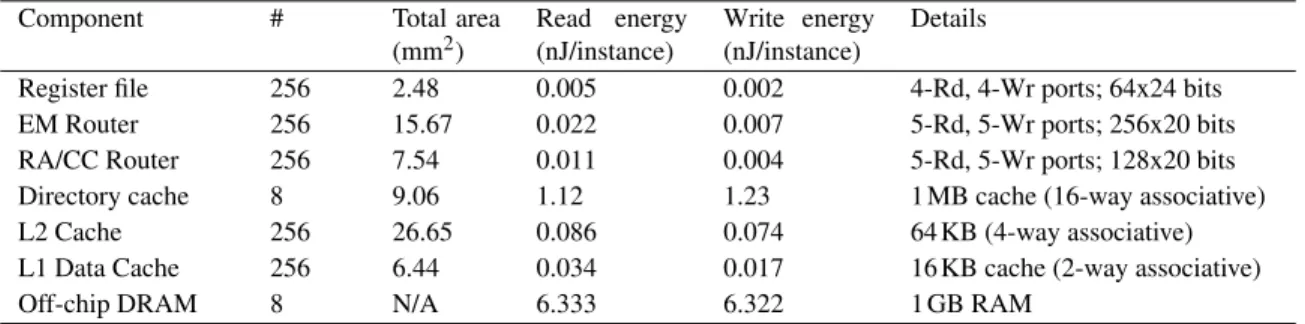

Documents relatifs
