Effets de pairs et consommation intertemporelle
Texte intégral
Figure
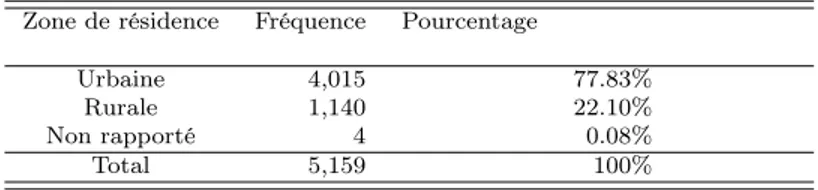
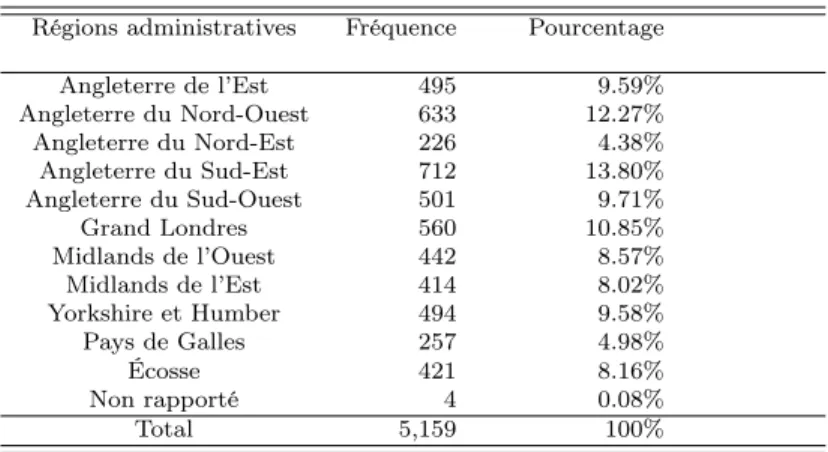
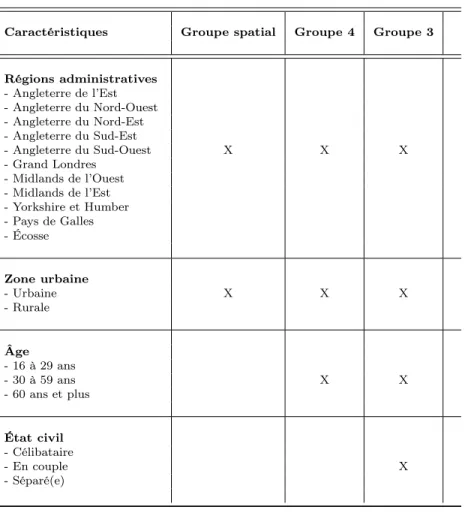
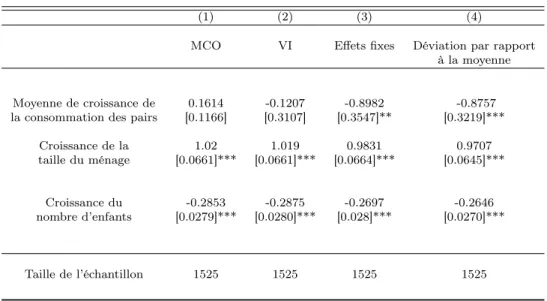
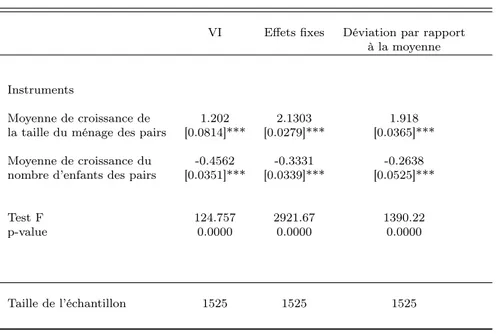
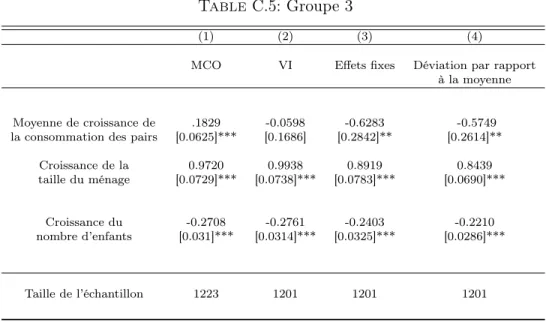
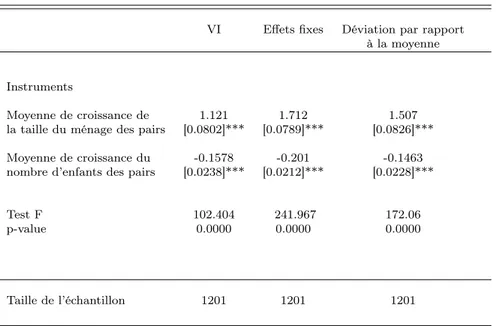
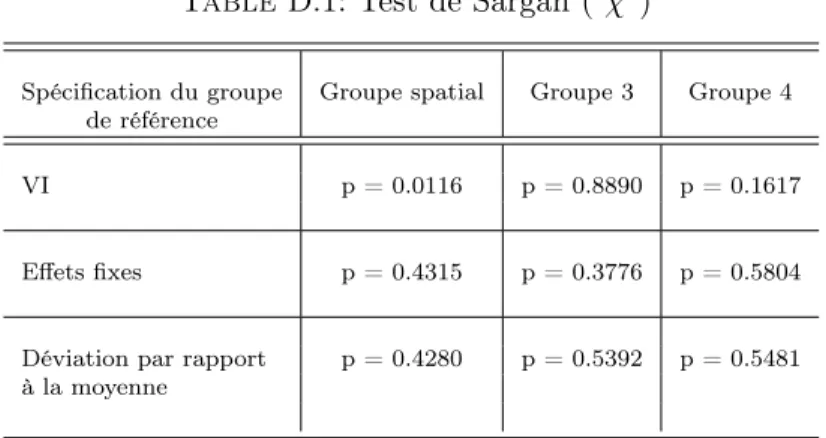
Documents relatifs
Until now we have focused primarily on intra-household effects, that is, on the utility changes in a particular household when bargaining power shifts within that household. Via
La méthode proposée basée sur un calcul de sensibilités par la technique des récurrences simplifiées et l'algorithme DFP a prouvé sa capacité à converger rapidement vers
(2011) répertorie les mécanismes intervenant lors d’une décontamination de particules contaminant une surface et dresse le bilan des forces et moments. Les mécanismes suivants
No obstante, si antes de la convocatoria el Director General recibiera el ofrecimiento de algún Estado Miembro para servir de sede para la referida reunión, el Comité Ejecutivo,
La fin de vie crépusculaire est décrite dans Pathos (13) sous le profil de soins M2 comme impliquant des « simples soins palliatifs de confort : i eau de soi s d a o
S’agissant de la « fatigue », elle sera représentée d’un côté par le taux de chômage et le climat des affaires, deux variables qui peuvent appeler une politique en
L’objectif premier du projet complet de maîtrise est de déterminer les meilleures approches pour optimiser la production de biomasse de Scenedesmus obliquus en utilisant
Nous avons montré que HP1, l’un des partenaires les plus importants dans la suppression génique induite par Suv39h1, est également présente sur les régions promotrices
