System for Automatic Faces Detection
Amir Benzaoui, Houcine Bourouba and Abdelhani Boukrouche
Laboratory of Inverses Problems, Modeling, Information and Systems (PI:MIS)
Department of Electronics and Telecommunication, University of 08 Mai 1945, P.O box 401 Guelma - 24000 Algéria e-mail: [email protected], [email protected], [email protected]
Abstract—The effectiveness of biometric authentication based on face mainly depends on the method used to locate the face in the image or video. This paper presents a hybrid system for faces detection, in a color image or video, in unconstrained cases, i.e. situations in which illumination, pose, occlusion and size of the face are uncontrolled. To do this, the new method of detection proposed in this system is based primarily on a technique of automatic learning by using the decision of three neural networks, a new method of feature extraction based on the principal of energy compaction in the DC coefficient using the discrete cosine transform and a technique of segmentation by skin color to reduce the space of research and to accelerate the process of detection. A whole of pictures (faces and no faces) are transformed to vectors of data which will be used for entrain the neural networks to separate between the two classes while the discrete cosine transform is used to reduce the dimension of the vectors, to eliminate the redundancies of information, and to store only the useful information in a minimum number of coefficients. The experimental results have showed that this hybridization of methods will gave a very significant improvement of the rate of the recognition, quality of detection and the time of execution.
Keywords—face detection, facial biometrics, neural networks,
discrete cosine transform.
I. INTRODUCTION
Faces detection is a significant researching field of computer vision and pattern recognition. It impacts important applications in many areas such as entrance control system and video surveillance. This problem is considered like the first stage of any biometric system based on the face as a mean for identification. Faces have several advantages for personnel identification compared with other systems of biometrics: they have a rich structure to differentiate between people, modality accepted by people, acquisition can be affected without participation of the subject and can be captured from distance.
Several methods of detection have appeared in the two last decades, Yang and al [1] classify these methods in four classes: solutions based on rules, solutions based on invariant characteristics, solutions based on the mapping and the solutions based on techniques of automatic learning. For the first approach, the construction of the system is based on geometrical rules to seek candidates, and each candidate is determined as a face or not according to his edge characteristics. For the second approach, the solutions aim at finding characteristics structural of the face which are invariant when the conditions of image such: position, point of view, lighting… vary and to use them to find faces. The characteristics often used are: form, texture, skin color, edge [2]… The third approach includes a solution that identifies faces by comparing each part of the image with a pattern of face which was built before [3]. On the contrary, the methods based on techniques of automatic learning create models during the learning and then use them to find faces [4, 5]. However, the systems of the human vision have a good effectiveness because they have a solutions provided naturally by the human brain whereas
the computerized solutions of vision don't present a great resemblance [6].
The objective of the proposed system aims at improving the performances and the quality of detection in a real context and to fill the gap between the computerized models of the vision and their human counterparts. With this intention, we have proposed a system of faces detection with high quality of detection in unconstrained cases. This system is based primarily on automatic learning by using the decision of three neuronal networks; the learning is carried out starting from two databases of pictures (faces, not faces) which represent two classes to be separated. This system is characterized by learning at the frequency level by using the discrete cosine transform (DCT), this latter is a technique which has a very great effectiveness in term of energy’s compaction, it makes it possible to represent a maximum of pixels in one coefficients (DC) located in the left higher corner of the matrix. We have profited the advantage from this transformation in order to reduce the dimension of the vectors and to eliminate a very great quantity from useless information what makes it possible to gradually improve quality of the learning.
In this paper, we present our faces detection system in the following sections. Section II illustrates the principle of images compression by DCT. Section III presents the framework of the system of detection. The experimental results are exposed in section IV. Conclusion will be drawn in section V with directions to the future works.
II. DISCRETE COSINE TRANSFORM
Data compression without loss of information is a very important problem in the field of patterns recognition; it makes a change from a higher dimensional space to a lower dimensional space. The basic goal of data compression (extraction of the useful information) is to represent an image (matrix) with minimum number of coefficients of an acceptable image quality.
Several transformations are used in this kind of problems; most widespread are the transform of Fourier (DFT), the transform of Karhunen-Loève (KLT) and that as the discrete cosine transform (DCT) who will be used in the design of our system [7]. The transform of Karhunen-Loève is recognized by its precision and its exactitude but it presents a major disadvantage due to its complexity of calculations. The discrete transform of Fourier (DFT) is a very fast method due to the simplicity of its algorithms but its periodicity horizontally and vertically causes an inaccuracy in certain cases. The discrete transform as a cosine came to balance the existing compromise between the precision and the speed; it inherited the exactitude of the KLT and the performance the DFT, due to its simple, fast and effective algorithms [7].
The discrete cosine transform is a mathematical transformation which converting a signal into a spectrum of elementary frequency components [8], it allows a change in the field of study while maintaining exactly the same function studied. It is widely used in JPEG norm compression.
Image Processing Theory, Tools and Applications
In our case, we study an image, i.e. a function with two dimensions: X and Y indicating the spatial coordinates of the pixel and output value (coefficient) in this point. The DCT of a discrete signal with two dimensions is defined as follows:
F(x,y):The function describing a sequence of length N×N. The 2D Discrete Cosine Transform of the sequence F(x,y) denoted C(u,v)as follows [9]: C u, v 2 NC u C v f x, y cos 2x 1 u 2N N N cos 2y 1 v 2N C u , C v √ for u, v 0 1 otherwise (1)
Like other transforms, the discrete cosine transform (DCT) attempts to decorrelate the image data. After decorrelation each transform coefficient can be encoded independently without losing compression efficiency. The DCT has a very great effectiveness in terms of compaction of energy, it makes it possible to store a maximum of information in a minimum of coefficients located low frequency (left higher corner) and each time that one goes down again towards the high frequencies (in bottom on the right) there will be a degradation of information [10]. This makes it possible to eliminate the coefficients having relatively small amplitudes without presenting a deformation of the characteristics of the image (fig.1).
(a) (b)
Fig. 1. Frequency distribution of DCT of coefficients [10]. (a) Original image (b) Image after transformation
Fig. 2. DC point, AC point and zigzag sequence.
We consider now that we have a block of 8×8 pixels, The DC coefficients (fig. 02) is the measure of the average value of the 64
image samples. Because there is usually strong correlation between the DC coefficients of adjacent 8x8 blocks, the quantized DC coefficient is encoded as the difference from the DC term of the previous block in the encoding order. The remaining AC (fig. 02) coefficients are ordered into the zigzag sequence, which helps to facilitate entropy coding by placing low-frequency coefficients before high-frequency coefficients.
III.FRAMWORK OF THE PROPOSED SYSTEM
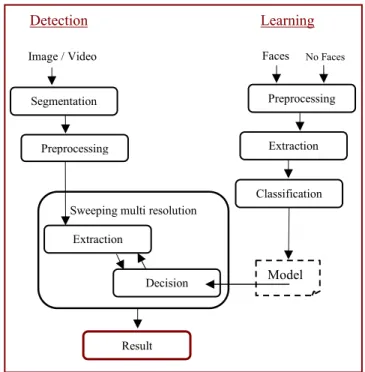
As shown in figure 3, our structure of the proposed system of faces detection comprises two phases: learning and detection.
Fig. 3. Framework of proposed system.
The learning phase is a very important step, because the face is a dynamic entity which changes constantly under the influence of several factors, which contribute to the complexity of the task of any detection’s system. In this mode, the system must have in entry two databases of pictures (fig.3) which represent the two classes to be separated. These pictures are standardized with the size 19×19 of pixels. One of them contains images of human faces (fig.3), these faces are different from each other according to the people and of the position from the face (inclined, right, rotation…), in more, these images are taken under conditions varied concerning the environment (luminosity, lighting…), in order to as well as possible cover the real conditions of use later. The other base contains images of not faces (objects, part of face…) considered as counter examples (fig.3). The system will analyze the problem, extract a data, classify the images and will create a model of learning (function of classification) according to parameters which will give a the best result, then will store the model to be used at the phase of detection.
Figure 4. Faces and No Faces examples.
Detection Learning Preprocessing Extraction Classification Segmentation Preprocessing
Sweeping multi resolution
Faces No Faces Image / Video Model Decision Extraction Result DC AC 01 AC 70 AC 77 AC 01
The process of the learning is devised into three main parts: preprocessing, feature extraction and classification.
The objective of the preprocessing is the modification of the representation of the sources pictures to facilitate the work of the following modules and to improve the detection’s quality. First, all pictures of faces and not faces are converted to gray level pictures. Next, every grayscale picture is filtered by median filter to suppress noise. Lastly, the noise suppression picture is then adjusted to improve the picture contrast.
After the above preprocessing, a step of feature extraction is used to prepare data for learning the classifier, by selecting the pertinent information from each picture. Our system reposes on a global approach which is based on pixel information. We have used the Discrete Cosine Transform (DCT), as a method of compression data, to extract a vector of pertinent coefficient which represents the parameters necessary to modeling the original picture.
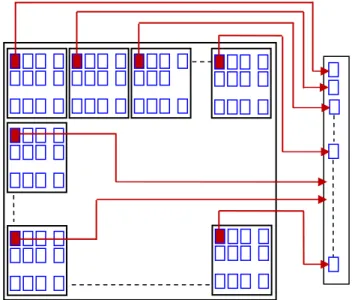
The transform coding algorithm usually starts by partitioning the original picture into subimages (blocks) of small size (usually 8×8 pixels). For each block the discrete cosine transform coefficients are calculated, effectively converting the original 8×8 array of pixel values into an array of coefficients within which the coefficient of the top-left corner (DC) usually contains most of the information needed to represent the useful information. Finally, the construction of the pertinent vector is carried out by selecting the DC coefficients of each block as shown in fig.5.
Fig. 6. Construction of the vector of DC coefficients. The stain of the module of classification is to employ the vectors of coefficients provided by the preceding stage (feature extraction) to assign the objects of interest to a category or a class (positive or negative) (fig.7). In other term, starting from a whole of vectors of extracted coefficients, a method of learning is employed to form an effective function of classification.
Our system employs an artificial neurological network (RNA) like classifier. Like there are several types of neuronal networks, we have chosen the most common model of neurological network is the perceptron multi-layer MLP, the MLP learns from the sample of entry and the value of corresponding exit of output by changing the synaptic weights between connections. So that the MLP analyzes the problem given, it is necessary to make him learning, the latter acted on the weights of the network in a manner so that the error of detection is lower than a certain threshold. The algorithm of learning used in this module is the retro-propagation of gradient. In order to render the system more effective, i.e. to reduce the number of false detections, we have entrained three neuronal networks to classify, and then to
choose according to their answers, those which must be preserved or eliminated. The performances of each MLP depend on the initialization of the weights, the rate of learning and the number of neurons of the hidden layer, this is why we have carried out several tests before preserving a topology giving the best performance (the training is stopped when the average quadratic error is < 0.001).
: No face : Face
Fig. 7. Classification.
In the detection mode, the system receives in entry a color image (or video), the image (sequence of image) will be pretreated and swept by a frame of fixed size , in its turn, it will pass by the function of decision to see if the frame contains a face or not. The process of the detection is devised into five main parts: segmentation, preprocessing, sweep multi resolution, feature extraction and decision.
To accelerate the process of detection, we have used a technique of segmentation by the color of human skin; this technique is largely used and proved effective in several applications such as the detection of human movement and the video monitoring. It is advantageous to use this additional information to isolate the areas which contain the faces. Indeed, the elimination of the areas not having the color of the skin reduces the number of frames which are sent to the two modules (compaction and decision).
Although, the color of human skin can widely vary, recent research shows that the principal difference is in the intensity rather than in the chrominance [11]. Several spaces of color are used to label the pixels of color of human skin: RGB, RGB standardized, HSV, YCrCb, YIQ, etc. [11]. Moreover, there are methods proposed to build a model of color of human skin: methods using the tonality of pixel, non-parametric methods based on the histogram, and methods parametric using a Gaussian function [11].
For our work, a simple, effective, robust, and real time method to segment the blobs color of human skin is the good choice. For this, we chose a method of segmentation by thresholdingusingthe spacecolor RGB [11]. The thresholding of this space is applied to the three channels (Red, Green, and Blue); the whole of the pixels of the image is classified in two classes, color skin and not-color skin, according to the rule of following classification [11]:
(R > 95), (G > 40), (B > 20) (Max (R, G, B) – Min (R, G, B)) > 15) (2)
(ABS (R-G) > 15), (R > G), (R > B)
One will obtain in end treatment an image where only the pixels appear which check the conditions fixed for the color of skin. An
Window Scaling Sweeping of the image Sweeping of the reduced image
example of skin detection based on this method is shown in (fig.8). We have found also that this method is very effective in detecting skin regions.
(a) (b) Fig. 8. Segmentation by color of the human skin.
(a) Original Image. (b) Segmented Image.
The required objective of the system is the detection of the faces in the image. To do this, a window of fixed size (19x19 of pixels) is defined, which traverses in all the areas of the skin colors the image to research of the faces. This window has a fixed size to serve the data entering to the classifier. Also, the detection of face will be able to take place only on images of a minimal size of 19x19 pixels. Sweeping will start on an image with its initial size, and then the image will be successively reduced to each scaling in order to be able to recover faces more or less close to this image (fig.9).
Fig. 9. Sweeping multi resolution. IV. EXPERIMENTAL RESULTS
The method of detection proposed in this system was trained and tested by the “MIT CBCL” database [12]. This database contains 31022 pictures, composed of 2 parts (learning and test). The part of learning is composed of 6977 pictures (2429 faces, 4548 not faces) and the second part is composed of 24045 pictures (472 faces, 23573 not faces). These pictures are on the level of gray and have a fixed size of 19 ×19 pixels.
The following table has the best results obtained during the evaluation of the system of detection, and that is done by successive tests carried out according to several configurations of the neural networks, while also comparing between the three following modes:
• MLP: the classifier MLP will be used only without compression.
• MLP- DCT: the classifier will be used with compaction of energy by selecting the coefficients closer to the top-left corner of each block (tested in other work).
• MLP- DC: the classifier will be used with selection of the DC coefficients.
Table 1. Best rates of detection obtained.
Rate of recognition Rates of false acceptante
MLP 77.03 7.46
MLP-DCT 92.33 2.11
MLP-DC 96.33 1.78
According to the results obtained, we have deduced that the use of the new method of feature extraction based on DC coefficients associated with the neural networks is very interesting to improve the rate of recognition. The method proposed in this paper has several advantages compared with other methods of detection, it is characterized by:
• Real time detection: reduction of the space of research by using a technique of segmentation of the color of human skin. • Robust method (in lighting, occlusion, position…): the
great capacity of generalization of the neural networks • Precision: improvement of the quality of the learning by the
reduction and the selection of the most relevant parameters by using a new technique of feature extraction.
Starting from the learning which we have carried out by using the MLP-DC approach, we also carried out some tests on images which we took by a personal camera. The tests are carried out on faces which are presented in various colors and various orientations and scales (fig.10).
Fig. 10. Examples of testing images and faces detection results. V. CONCLUSION
In this paper, we have presented a hybrid system for human faces detection in unconstrained cases. The objective of our system aims to improve the performances and the qualities of detection in a real context and filling the gap between the computerized models of the vision and their human counterparts. The new proposed method in this system is primarily based on a technique of automatic learning by using the decision of three neural networks. Our method is
characterized by learning at the frequency level by using the discrete cosine transform as a technique of energy compaction, which makes it possible to store a maximum of information in a minimum of coefficients located in the lows frequencies and to eliminate the coefficients having relatively small amplitudes without presenting a deformation of the characteristics of the image. Also, the technique of segmentation by the color of human skin has been used to reduce the space of research at the image. The experimental results showed that the new proposed method gave a very significant improvement at the rate of recognition, quality of detection, and the time of execution compared with other methods of detection.
One of the prospects for this work is to learn the system with other databases that presents strong variations in the light and the position of the head. Also, we can consider the possibility of employing it for an approach based on the characteristic’ elements of the face.
REFERENCES
[1] Xue Dong Yang, Peter Kort, Richard Dosselmann. Automatically Log Off Upon Disappearance of Facial Image. DRDC Ottawa CR (2005-05). [2] Hsiuao-Ying Chen, Chung-Lin Huang, Chih-Ming Fu. Hybrid-boost
learning for multi-pose face detection and facial expression recognition. Pattern Recognition 41 pp. 1173 – 1185 (2008).
[3] S. Phimoltares, C. Lursinsap, K. Chamnongthai. Face detection and facial feature localization without considering the appearance of image context. Image and Vision Computing 25 pp. 741–753 (2007).
[4] Hyeon Bae, Sungshin Kim. Real time face detection and recognition using hybrid information extracted from face space and facial features. Image and Vision Computing 23 pp. 1181-1191 (2005).
[5] Ignas Kukenys, Brendan McCane. Support Vector Machines for Human Face Detection. NZCSRSC 2008, Christchurch New Zealand (April 2008).
[6] Z. Li Stan, Anil K. Jain. Handbook of Face Recognition. Springer – First Edition– (2004).
[7] SA. Khayem. The Discete Cosine Transform: Theory and Application. Department of Electrical & Computer Engineering Michigan State University, (March 2003).
[8] Ken Cabeen and Peter Gent. Image Compressing and the Discrete Cosine Transform. Math 45, College of the Redwoods.
[9] Dubey R B, Gupta R. High Quality Image Compression. WebmedCentral MISCELLANEOUS 2011; 2(3):WMC001673.
[10] Vijaya Prakash.A.M, K.S.Gurumurthy. A Novel VLSI Architecture for Digital Image Compression Using Discrete Cosine Transform and Quantization”, IJCSNS International Journal of Computer Science and Network Security, VOL.10 No.9,( September 2010).
[11] Thanh Phuong Nguyen. Détection de visage dans images de couleur en utilisant une caractéristique invariante. 3rd International Conference: Sciences of Electronic, Technologies of Information and Telecommunications, SETIT, TUNISIA (2005).
[12] MIT CBCL Face Data Set, http ://www.ai.mit .edu/projects/ cbcl/ softwar- edatasets/ FaceData2.html.