Phonemic transcription of low-resource tonal languages
Texte intégral
Figure

Documents relatifs
For this, overcoming the language barrier is needed and this is what we propose in the ALFFA project 1 where two main aspects are involved: fundamentals of speech analysis
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
In the present paper, both a connectionist framework for the representation of tonal knowledge and for the simulation of perceptual learning in music are presented.. The
In addition, we present a repeatable use case for low-resource languages: using neural machine translation with humans- in-the-loop to improve global access to health care
In this paper we propose an efficient feed-forward deep neural network (DNN)-based acoustic model, using stacked bottleneck features, that together with the recently introduced
The paper presents a hierarchical naive Bayesian and lexicon based classifier for short text language identification (LID) useful for under resourced languages.. The algorithm
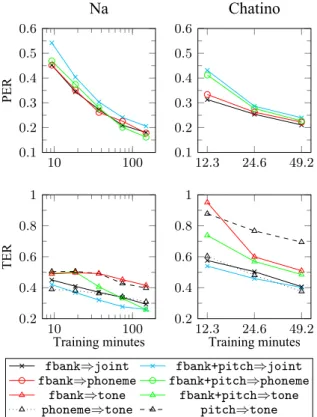
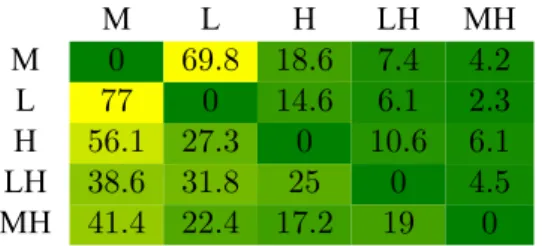
The tests reported here (on Yongning Na and other languages from the Pangloss Collection, an open archive of endangered languages) explore some possibilities for automating the
We proposed five prototypical curves that represent global tonal tension profiles and then we asked the listeners to select the curve that best represents the overall perceived
