Neural Modularity Helps Organisms Evolve to Learn New Skills without Forgetting Old Skills
Texte intégral
Figure





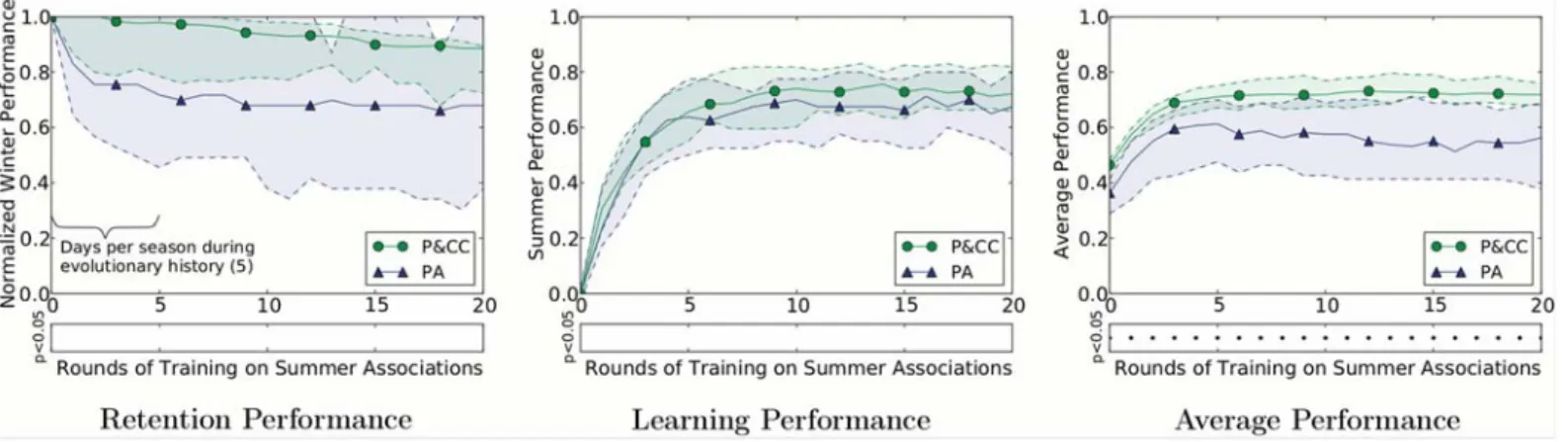



Documents relatifs
Comparing the key concepts outlined earlier from the lean startup approach to comparable findings from network-based research in the entrepreneurial field (Table
[r]
Statistical significance, therefore, does not automatically equate to substantive or practical effect – some statistically significant effects may be
La question fiscale des activités économiques associatives est déterminante dans la prise en compte de la spécificité de l’économie associative au niveau du
Changing the depth from 50 to 101 increases the quality of the results. This implies that a deeper backbone may always result in better quality. However, our results show that a
For what concerns the k-fold learning strategy, we can notice that the results achieved by the model not using the k-fold learning strategy (1 STL NO K-FOLD) are always lower than
The percentages of misclassified examples, presented in Tables 7 8, showed that even with a much smaller training dataset, with four or five base models the architecture
Ce bref rappel historique, qui ne vise nullement à l’exhaustivité, montre à la fois la variété et la diversité des entreprises d’économie sociale tout en relevant de
