HAL Id: hal-02408012
https://hal.archives-ouvertes.fr/hal-02408012
Submitted on 12 Dec 2019
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of
sci-entific research documents, whether they are
pub-lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destinée au dépôt et à la diffusion de documents
scientifiques de niveau recherche, publiés ou non,
émanant des établissements d’enseignement et de
recherche français ou étrangers, des laboratoires
publics ou privés.
Brigitte Grau
To cite this version:
Brigitte Grau. Evaluation des systèmes de question-réponse. S. Chaudiron. Evaluation des systèmes
de traitement de l’information, Hesmès, 2004, Traité des sciences et techniques de l’information.
�hal-02408012�
Evaluation des systèmes de question-réponse
1 Les différentes dimensions d’une tâche question-réponse
Très souvent les utilisateurs se posent des questions précises dont ils espèrent trouver la réponse dans une source particulière de données. Cette source peut-être un document ou une collection de documents, des pages Web, une base de connaissances (par exemple une encyclopédie) ou une base de données (par exemple des horaires de trains, des offres de locations). Le problème, pour l'utilisateur, est de disposer d'un moyen simple de poser sa question et d'obtenir rapidement la réponse qu'il souhaite. Cet objectif étant posé, il y a plusieurs façons de l’atteindre, dépendant essentiellement de l'utilisateur du système. En ce qui concerne les questions, un utilisateur spécialiste pourra utiliser des langages spécialisés (requête SQL2 ou requête booléenne) ; un utilisateur occasionnel préfèrera utiliser la langue naturelle ou une interface conviviale ; enfin un utilisateur habitué du système appréciera que ce dernier se souviennent de ses préférences afin d'éviter de tout expliciter à chaque interrogation. On trouve aussi de la diversité côté réponses. Un utilisateur non-spécialiste cherchant la définition d'un terme ou un fait précis n'attend pas une réponse du même niveau de granularité qu'un spécialiste du domaine. Cependant, l'aspect essentiel qui entre en jeu quant à la nature des réponses à fournir est la prise en compte du besoin d'information de l'utilisateur. Sa question est-elle de nature thématique, appelant alors plutôt un document en réponse ou de nature factuelle, appelant une réponse plus ciblée ? Désire-t-il juste une
Chapitre rédigé par Brigitte GRAU
réponse courte et précise ou une récapitulation des faits, un résumé ? Cherche-t-il toutes les réponses possibles figurant dans la source interrogée ou une seule lui suffit-elle ?
Ainsi qu'on peut le voir, un système de question-réponse sera caractérisé par plusieurs dimensions. Premièrement la nature de la source d'information, allant d'une base de données spécialisée à des textes portant sur tout domaine. Ensuite viennent les types de questions qu'il peut traiter, des requêtes factuelles du type
« Quand est mort Charles de Gaulle ? » à des questions plus complexes comme
« Quelle est la cause de la guerre en Irak ? ». Le type de demande amène des types de réponses différents, allant de la donnée d’un simple fait « 9 novembre 1970 » ou
« 1970 » à la production d’une synthèse à partir de plusieurs éléments de réponses ou la production d’un résumé. On peut aussi envisager des systèmes interactifs où répondre à une question entraîne plusieurs échanges (plusieurs questions enchaînées sur un sujet ou des demandes de précision par exemple). De cette diversité découle l’utilisation de techniques de résolution différentes, mettant en œuvre des approches linguistiques, une utilisation intensive de connaissances, ou des modèles reposant sur des statistiques.
Bien que chercher à répondre à des questions existe depuis le début des travaux en traitement automatique de la langue, c'est l'introduction d'une tâche d'évaluation dans la campagne TREC en 1999, campagne d’évaluation en recherche d’information, qui a relancé le thème, en le recentrant sur des questions tout domaine et de nature factuelle dont la réponse peut être extraite de documents ([VOO 01a], [HIR 01]).
Idéalement, l'évaluation d'un système de question-réponse devrait mesurer ses différentes dimensions [BUR 01] [LIN 03] :
– La justesse de la réponse ;
– La concision et la complétude : ne pas trop en dire, mais dire tout ce qui est nécessaire ;
– La pertinence de la réponse: la réponse peut être différente selon le contexte ; – L’interaction avec l'utilisateur ;
– Le temps de réponse ;
– La facilité d'utilisation du système.
La plupart des systèmes de question-réponse actuellement développés, prennent une question posée en langue naturelle en entrée et fournissent automatiquement une ou plusieurs réponses extraites de textes en sortie, utilisant pour ce faire des ressources et méthodes diverses. La plupart traitent des questions en domaine ouvert. Jusqu'à présent, leur évaluation a porté principalement sur l'évaluation de leur exactitude, et mesure ainsi la compréhension que le système a des questions qui
lui sont posées. Ces évaluations sont menées dans le cadre de campagnes récurrentes portant sur l'évaluation des travaux en recherche d'information : TREC pour les systèmes travaillant sur l'anglais (cinq évaluations ont déjà eu lieu en question-réponse), CLEF pour les systèmes travaillant sur une langue européenne et les systèmes multilingues (première tâche question-réponse réalisée en 2003) et NTCIR pour le japonais, du moins en ce qui concerne la tâche question-réponse (première évaluation en question-réponse en 2003 aussi). Ces évaluations donnent une mesure du résultat final produit par les systèmes et ces protocoles permettent ainsi de savoir, pour un concepteur donné, si, d'une version à l'autre, son système s’est amélioré. Dans cette dernière optique, des travaux ont été réalisés afin d'évaluer les composants d'un système et leur impact sur le résultat final. Cela apporte des éléments méthodologiques utiles lors de l'élaboration d'une solution. Par ailleurs, des projets sont en cours afin de prospecter ce que pourront être les futurs systèmes de question-réponse (projet AQUAINT3), ou pour évaluer des systèmes travaillant sur le français (campagne EQUER4).
Ainsi que ce survol le fait apparaître, peu de propositions existent quant à l'évaluation de l'utilité d'un système de question-réponse pour un utilisateur. Citons néanmoins les travaux de Belkin et al. [BEL 00] qui ont comparé différentes présentations des réponses dans une tâche de question-réponse dans le cadre de la piste interactive de TREC9 et Lin et al. [LIN 03] qui ont étudié le rôle du contexte lors de la production des réponses et montré qu’un utilisateur préfère disposer du paragraphe dans lequel la réponse a été trouvée.
Avant de présenter en détail ces travaux section 4, la section 2 resitue la problématique question-réponse dans le temps et la section 3 décrit les différents composants d'un système de question-réponse.
2. Les systèmes de question-réponse dans le temps
Si les systèmes de question-réponse faisaient partie du Traitement Automatique de la Langue (TAL) à leurs débuts, ils réapparaissent maintenant en Recherche d’Information (RI). Si ils avaient alors pour ambition de traiter en profondeur des problèmes de compréhension dans des domaines restreints, et s’étaient naturellement orientés vers des systèmes de dialogue, ils abordent maintenant la résolution de questions dont la réponse peut être extraite de textes portant sur n’importe quel domaine, en se limitant en général à une interaction. Si les premiers essais se sont
3 http://www.ic-arda.org/InfoExploit/aquaint
4 Cette campagne est menée dans le cadre du projet EVALDA soutenu par l’appel Technolangue du ministère de la recherche français
soldés par un échec à cause des connaissances à modéliser, les nouveaux systèmes obtiennent de bons résultats et leur utilisabilité est réelle.
Les premiers systèmes des années 1960-1970 ont été développés dans un but de recherche d'information ou d'interface en langue naturelle. Il en est ainsi de BASEBALL en 1963, SIR en 1968, LUNAR en 1973 et LADDER en 1977 (voir [BAR 81] pour une description de ces systèmes) qui permettaient tous quatre d'interroger une base de connaissances structurée. Alors que pour ces systèmes le problème central n'était pas le traitement de questions, mais la recherche d'information ou la réalisation d'une interface en langue, Lehnert, avec son système QUALM [LEH 77], a posé le problème de la modélisation des questions et de l'élaboration de stratégies de résolution selon le type d'information demandé. Elle a ainsi apporté des solutions dont se sont inspirés bon nombre de systèmes actuels. Cependant QUALM était fondé sur l’utilisation de connaissances élaborées représentées par des scripts [SCH 77]. Même si cette approche peut théoriquement s'appliquer sur des textes portant sur tout domaine, elle requiert des bases de connaissances très structurées représentant la sémantique et la pragmatique de la langue et du monde en général, connaissances qu'il n'est ni envisageable ni même possible de fournir à un système. Néanmoins, une approche purement TAL peut être réalisée pour un domaine d’application limité, tel que cela a été fait dans le système Extrans [MOL 00] qui répond à des questions portant sur les commandes Unix.
Évoquons enfin l’utilisation de questions afin d’évaluer la bonne compréhension d’un texte. Cette approche avait été utilisée chez Schank pour montrer la validité des processus de compréhension automatique d’histoires, et a été réintroduite par Hirschman [HIR 99] qui a proposé la mise en place de tests de compréhension à partir de textes et de questions de compréhension destinés aux enfants.
3. Description d’un système de question-réponse
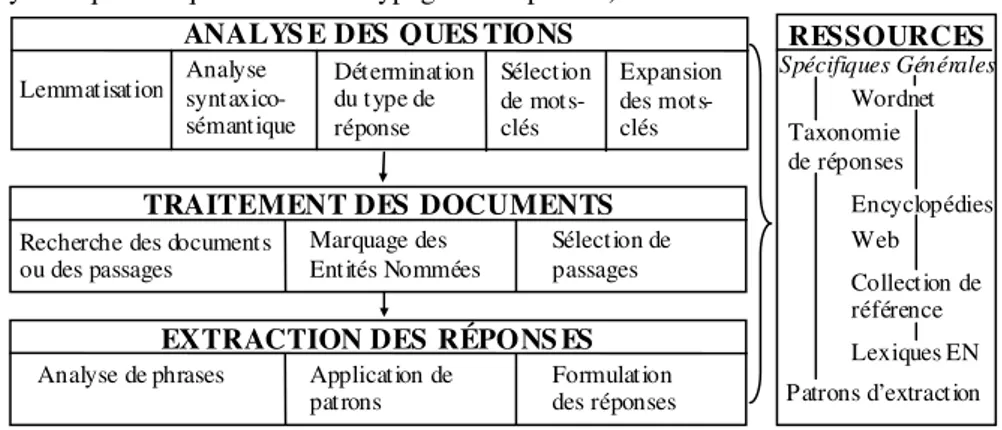
Comme le montre la figure 1, un système de question-réponse comporte de nombreux modules. L’analyse des questions est une étape primordiale pour déduire des questions l’information cherchée, comment elle pourra être reconnue dans les documents, et la requête qui permettra de ne travailler que sur un sous ensemble de la collection. L’analyse des questions réalise au minimum le typage des réponses par les types d’entités nommées pouvant répondre à la question. Par exemple à partir de la question « Combien de personnes vivent aux Falklands ?», l’analyseur prédit une réponse du type NOMBRE. Cette analyse permet également d’extraire les termes, simples ou composés, qui seront recherchés, soit tels quels soit sous forme d’une variante, dans les documents ou passages sélectionnés par un moteur de recherche. Dans l’exemple, il sera pertinent de retenir Falklands et éventuellement vivre et
principes peuvent avoir été élaborés par apprentissage automatique (pour l’analyse syntaxique des questions ou le typage des réponses).
Spécifiques Générales
Sélection de passages Marquage des
Entités Nommées Recherche des documents
ou des passages
TRAITEMENT DES DOCUMENTS ANALYS E DES QUES TIONS
Lemmatisation Analyse syntaxico-sémantique Détermination du type de réponse Sélection de mots-clés Expansion des mots-clés Formulation des réponses Application de patrons Analyse de phrases
EXTRACTION DES RÉPONS ES
RESSOURCES Wordnet Taxonomie de réponses Encyclopédies Lexiques EN Patrons d’extraction Collection de référence Web
Figure 1. Architecture d’un système de question-réponse
Ensuite le système applique les processus relatifs à la recherche des documents dans la collection de référence et à la sélection des passages pertinents selon des critères de nombre de mots communs, ou similaires, entre la question et le passage, la proximité de ces mots entre eux et la présence du type de réponse attendu. Cela signifie que le processus de reconnaissance des entités nommées [GRI 95] permettant de typer des syntagmes a eu lieu et a conduit à l’annotation du document. Les moteurs de recherche utilisés sont de natures très variées, mais il a été constaté que les moteurs booléens produisent de bons résultats pour cette tâche, et permettent de gérer précisément l’expansion de requête. En effet, un deuxième enseignement porte sur la nécessaire expansion des requêtes à partir de connaissances sémantiques, en général WordNet [FEL 98].
Enfin, la dernière étape concerne l’extraction des réponses, processus fondé souvent sur l’application de patrons locaux. Par exemple, la phrase réponse de la question précédente est la suivante « La population des Falklands, de 2 100
habitants, est concentrée … ». On voit ainsi qu’il est nécessaire de gérer la variabilité de la langue, présente sous de nombreux aspects, entre les mots de la question et les mots du document : 1) la variabilité lexicale avec des variations sémantiques (utilisation de synonymes, d’hyperonymes ou d’hyponymes) ; 2) les variations morphologiques (passage du verbe à la nominalisation ou plus généralement reconnaissance de termes appartenant à la même famille morphologique); et enfin 3) la variabilité syntaxique avec les différentes formulations sous lesquelles peuvent apparaître les réponses.
Globalement, tous les systèmes procèdent de cette architecture, avec éventuellement des rétroactions entre modules. Ils mêlent en général des approches numériques et symboliques pour les différents composants. Signalons cependant que l’un des meilleurs systèmes ([HAR 00], [HAR 01], [MOL 99], [MOL 02]) utilise de manière poussée des processus de TAL et de la déduction logique. Une autre approche très efficace ([SOU 01], [SOU 02]) est fondée sur l’utilisation intensive de patrons d’extraction. Enfin, l’une des stratégies qui est souvent mise en œuvre consiste à utiliser le Web, que ce soit exclusivement pour chercher des réponses [BRI 01], ou l’exploiter conjointement avec une base de textes ([CHA 03], [CHU 02], [CLA 01], [MAG 02]).
4. Évaluation de la production finale du système : les campagnes d’évaluation
Le succès que remporte la tâche question-réponse et sa complexité toujours croissante sont une preuve de la vitalité des recherches effectuées. Le principe de l'évaluation consiste à poser un jeu de question aux participants, questions factuelles portant sur n’importe quel domaine. Ils ont une semaine pour les traiter, c’est-à-dire extraire automatiquement les réponses d’une collection d’articles de journaux distribuée au préalable. L’évaluation de leurs soumissions est réalisée par des juges humains. Les réponses doivent être accompagnées du numéro du document qui justifie la réponse. Ainsi une réponse, exacte sur la valeur, mais qui n'est pas justifiée dans le document proposé ne sera pas comptabilisée dans les réponses correctes.
Nous allons maintenant présenter les campagnes actuelles, puis les différents points qui caractérisent une évaluation, et enfin les résultats obtenus lors de chacune d’elles.
4.1. Campagnes d’évaluation TREC
Il est intéressant de voir comment la tâche a progressé au cours de ses cinq années d’existence. TREC8 (1999) proposait deux cents questions. Il s'agissait alors de retourner cinq extraits ordonnés de 50 ou 250 caractères contenant la réponse, extraits recherchés sur un corpus de 1,9 gigaoctets, soit 528 000 documents. Les documents provenaient de journaux américains, avec le Los Angeles Times, le
Financial Times, le FBIS et le Federal Register. Dès cette première campagne, une vingtaine de participants se sont manifestés. Il est clairement apparu la nécessité d'utiliser des programmes de traitement automatique de la langue (TAL) ainsi que des connaissances sémantiques. Et c’est bien ce qui caractérise cette tâche, la nécessité de faire cohabiter des méthodes différentes, issues de domaines de
recherche différents. Si le problème de question-réponse faisait partie du TAL dans les années 70-80s, il est maintenant à la croisée de la RI et du TAL.
La campagne TREC9, l'année suivante, proposait toujours les deux pistes aux participants, au nombre de vingt-huit. L’accent a été mis sur la constitution des questions, et la tâche en comportait 700. La taille de la collection a presque doublé, avec 980 000 documents formant 3 gigaoctets.
TREC10 (2001) revenait à 500 questions mais complexifiait la tâche puisque seules les réponses courtes étaient autorisées, et que certaines questions n'avaient pas de réponses dans les documents. Deux nouvelles tâches ont été introduites. La tâche « liste » visait l’évaluation de questions dont la réponse est constituée de plusieurs valeurs, du type « Quelles sont les trois couleurs du drapeau français ? ». La tâche « contexte » avait pour but la mise en œuvre d’un dialogue au sujet d’une même thématique. Le nombre de participants s'est stabilisé autour de trente cinq. Parmi ceux-ci, dix ont participé à la tâche « liste » et six à la tâche « contexte ».
La difficulté de TREC11 (2002) portait sur trois points : ne donner que la chaîne de caractères constituant la réponse et non un court passage, ne donner qu'une seule réponse par question et classer les réponses selon la confiance du système. La collection de référence a été remplacée par le corpus AQUAINT, de taille équivalente. La piste « contexte » a été abandonnée. Hormis le premier système [MOL 02] qui obtint plus de quatre cents réponses sur cinq cents et utilise une analyse fine des phrases conjointement à un processus d’abduction pour justifier la réponse, les autres systèmes, qui diffèrent certes dans certains de leurs modules, mais qui globalement essaient tous de marier des processus de TAL de surface, l'utilisation de connaissances sémantiques et des techniques de recherche d'information, obtiennent des résultats pouvant encore être nettement améliorés. La plupart de ces systèmes ont recherché des réponses sur le Web, que ce soit exclusivement ou non. Se pose alors la question des bases de connaissances autorisées pour l’évaluation.
La campagne TREC12 (2003) a introduit des questions de définition, en supposant un contexte défini a priori et le même pour toutes les questions, afin de limiter le nombre de réponses pertinentes. Un pilote a été mis en place préalablement afin de mettre au point une mesure d'évaluation de l’ensemble des informations constituant une réponse aux questions de définition.
4.2. Campagne d’évaluation CLEF
En Europe, la campagne CLEF a pour but l’évaluation de systèmes en recherche d’information qu’ils soient monolingues de langue européenne ou multilingues. La
campagne CLEF5 a intégré en 2003 une piste question-réponse. La différence avec la campagne TREC vient des langues traitées et de l’introduction de pistes multilingues.
Les tâches monolingues comportent 200 questions en italien, espagnol et hollandais, qui ont des réponses dans les trois corpus. Les corpus sont constitués d’articles de journaux de tailles allant de 200 à 540 megabytes. Parmi ces questions, dix pour cent n’ont pas de réponses dans le corpus de référence. Pour les tâches multilingues, il s’agit de rechercher les réponses à des questions posées dans une des trois langues dans des documents en anglais. La campagne 2004 comportera plus de croisements de langues. Les participants pouvaient fournir trois réponses par question. Notons qu’il n’y a pas eu énormément de participants dans chacune des tâches, et c’est pour cette raison que nous n’en donnerons pas les résultats. Cette première évaluation a permis de fournir un cadre pour l’évaluation multilingue.
4.3. Campagne d’évaluation NTCIR
La campagne NTCIR6 a pour but l’évaluation en recherche d’information pour
les langues asiatiques. La recherche s’effectue aussi sur des journaux, japonais pour la tâche question-réponse proposée en 2003. Les tâches envisagées ont pour but de rechercher une réponse à des questions, que ce soit des questions attendant une seule réponse ou plusieurs réponses (une liste). Trois pistes ont ainsi été définies : la première consiste à donner jusqu’à cinq réponses sous forme d’une chaîne contenant seulement la réponse, à 200 questions. Si plusieurs réponses existent à une question, il suffit d’en produire une ; la deuxième consiste à donner toutes les réponses justifiées par la base de documents. En effet, les réponses ne doivent pas forcément être extraites des documents, mais elles doivent y être justifiées et peuvent en être des paraphrases ; la dernière piste comporte des questions enchaînées et est analogue à la piste « contexte » de TREC. Cette évaluation a mis en concurrence 14 participants.
4.4. Les questions
La définition d’un bon ensemble de test se décline selon plusieurs dimensions : — Les questions vues en fonction de leurs réponses, de manière à disposer de résultats évaluables ;
— Les questions utiles à un utilisateur ;
— Les questions menant à des processus de résolution différents.
5 http://www.clef-campaign.org 6
4.4.1. Les questions vues en fonction de leurs réponses
Les questions doivent porter sur des faits précis, pouvant être explicités en peu de mots, et tels que l’évaluation de leur justesse en tant que réponse possible ne fasse pas intervenir d’interprétation subjective. Ainsi, les questions portent sur des personnes à nommer, « Qui a construit le Tour Eiffel ? », des dates, « Quand a été
construite la Tour Eiffel ? », des lieux, « Où trouve-t-on la Tour Eiffel ? », des mesures, « Quelle est la hauteur de la Tour Eiffel ? », des objets ou des entités,
« Quels monuments peut-on visiter à Paris ? » ou « Qu’a découvert Christophe
Colomb ? », ou même des événements ou des réalisations, «À quoi sert un
stéthoscope ? ». On évite ainsi les questions de type procédural dont la réponse correspond à une succession d’items « Comment obtenir un passeport français ? ».
Cette définition étant posée, elle n’est cependant pas suffisante. Ainsi, des questions sont ambiguës : il existe une Tour Eiffel à Prague, une reproduction de la Tour Eiffel n’a pas la même taille que le véritable monument. Aussi, on suppose un contexte d’interrogation par défaut, établissant que l’on recherche une information à propos d’un objet célèbre, et non une réplique ou une imitation. Cela n’est pas toujours suffisant puisque le problème est apparu à TREC [VOO 00a] avec une question demandant où était situé le Taj Mahal, qui est aussi un casino à Atlantic City, et qui semblait à l’assesseur suffisamment connu pour que l’on puisse en demander sa localisation. Par ailleurs, il existe des questions amenant beaucoup trop de réponses possibles, comme « Que fabrique l’entreprise Peugeot ? » qui avaient treize réponses différentes possibles dans le corpus : des voitures, des véhicules, des moteurs Diesel, des composants en plastique, des véhicules électriques, des modèles de voiture (Peugeot 405 etc.). Ces questions ne sont pas toujours identifiables a
priori, sans avoir recherché toutes les réponses possibles dans la collection. 4.4.2. Les questions d’un utilisateur
L’introduction d’une tâche d’évaluation des systèmes de question-réponse est liée à un besoin chez les utilisateurs de ce type de compétence dans un système de recherche d’information. Cependant, les questions de la première campagne ont été construites de manière assez artificielle puisqu'une majeure partie venait de propositions des participants. Ce premier ensemble est donc moins réaliste et moins significatif de la tâche, car beaucoup de questions sont des reformulations (ou des retro-formulations) des réponses figurant dans les documents.
Les questions de TREC9 [VOO 00b] sont elles issues des questions posées à l’encyclopédie Encarta, qui sont exprimées par des phrases grammaticales, et des requêtes posées au moteur Excite qui ont servies de source d’inspiration afin de créer des questions sans se référer aux documents. Les questions ont été sélectionnées par l'organisateur sur des critères de portée de la question
(suffisamment générale) et conduisant à des réponses évaluables. Les questions TREC10 [VOO 01b] proviennent des logs de AskJeeves et MSNSearch, ont été réellement formulées comme des questions et ensuite filtrées par les organisateurs pour retenir des questions factuelles.
Il n’y a pas de contrôle sur le type de questions (leur forme syntaxique ou le type de réponse attendu), partant du fait que si elles sont représentatives d’un usage, elles figureront dans l’ensemble de test. Néanmoins, un contrôle a été réalisé sur les questions de définition dans TREC11. Pour TREC10, le jeu de 500 questions contenaient 135 questions de définitions qui ont entraîné des problèmes lors de l'évaluation, puisque les réponses peuvent être très disparates, allant de la proposition d'un concept générique à une partie seulement de la définition. En effet, des questions, « Qu’est-ce qu’un atome ?», ou « Qui est Collin Powell ?», amènent des réponses de différents niveaux de généralité et il est difficile d’évaluer leur complétude : quelle est l’information qu’il faut donner pour être suffisamment informatif ? Ces questions ont été réintroduites à TREC12, où elles étaient explicitement typées, et la réponse consistait à produire tous les éléments d’information qui répondent partiellement à la question. Ainsi, à une question du type « Qui est M. X ? », on attend sa fonction, son age, sa position sociale, etc..
Les questions de CLEF [MAG 03] ont été construites à partir des « topics » donnés aux tâches de recherche de documents, et ne correspondent pas à de réelles questions utilisateurs. La difficulté supplémentaire à CLEF réside dans le fait qu’une question doit avoir une réponse dans les différents corpus monolingues, de manière à produire des ressources permettant l’alignement. Par ailleurs, les questions en anglais, qui constituaient l’ensemble de départ pour les pistes multilingues et qui a été traduit ensuite dans les différentes langues, ont été formées à partir d’extraits de documents. On retrouve ici le biais introduit par le fait de partir des réponses. 1200 questions à NTCIR ont été produites par l’organisateur et 20 par participants, parmi lesquelles 200 ont été retenus pour l’évaluation, les autres ont permis la constitution de ressources.
Les questions portant sur des listes sont de même type et contiennent le nombre de réponses attendues (TREC10 et 11), ou non (TREC12 et NTCIR). Elles sont produites par les organisateurs, ainsi que les questions enchaînées, de tels exemples étant impossibles à trouver lors d’interrogations réelles.
4.4.3. Les questions menant à des processus de résolutions différents
Quelques points ont été testés pouvant entraîner des processus spécifiques. Des reformulations ont été introduites à TREC9, au nombre de 200. On s’aperçoit ainsi qu’il n’est pas aisé de reconnaître une véritable reformulation, car le type de réponse attendu varie souvent avec celle-ci. Un autre aspect, qui figure dans la plupart des
évaluations, consiste à introduire des questions sans réponse dans le corpus. On en trouve ainsi environ 10% dans les jeux de test.
4.4.4. Conclusion
À cause de la difficulté de juger les réponses, la plupart des évaluations actuelles se recentrent sur des questions factuelles portant sur une entité. Les questions portant sur la causalité d’un événement, sur une définition ou un processus sont écartées pour l’instant, faute d’un cadre adéquat à leur évaluation. Pour certains aspects, on se rapprocherait de l’évaluation du dialogue, mais en domaine ouvert, et pour d’autres on serait assez proche du résumé, car poser une question plus thématique consiste à former une synthèse constituée des principaux points.
4.5. Les mesures
Lorsque le système produit une liste de réponses par questions, son score est la moyenne sur le total des questions, de l’inverse du rang de la réponse correcte si elle est présente (MRR7). Fukamoto et al. [FUK 03] à NTCIR ont comparé cette mesure
à la proportion de réponses correctes placées au premier rang, ainsi qu’à la proportion de bonnes réponses, quelque soit leurs places. Ils ont obtenu quasiment le même classement des systèmes, à l’exception d’une inversion pour chacune des mesures. On peut donc en conclure que le MRR est une mesure stable.
Lorsque les systèmes ont rendu leur résultat à TREC11 en ne donnant qu’une réponse par question et en les classant en fonction de leur confiance dans la réponse trouvée, la mesure utilisée, CWS8, était la suivante, où Q représente le nombre total de questions à traiter :
∑
= = Q i CWS 1 i i rang au correctes réponses de Nombre Q 1Voorhees [VOR 02] a mené une comparaison des résultats obtenus par les systèmes sur des jeux de questions différents, afin de voir si le jeu de test avait un impact sur l’évaluation des systèmes. Si un jeu de question favorise certains systèmes au détriment d’autres, alors ce jeu de question n’est pas représentatif de la tâche. Aussi les scores ont été calculés à partir de jeux de tests différents, et il est apparu qu’un taux d’erreur de 5% dans l’évaluation d’un système, ce qui est communément admis, entraîne une différence de seulement 0.07 dans son score.
7 Mean Reciprocal Rank 8 Confidence-Weighted Score
En revanche, cette mesure favorisait les systèmes qui classaient bien leurs réponses et a conduit à un classement assez différent de celui qui aurait été produit par une mesure du rappel (cf. Table 4 section 4.7) et il a semblé que ce dernier caractérisait mieux les performances des systèmes. Aussi, l’évaluation TREC12 a évalué les systèmes selon une mesure de rappel, et comme l’ensemble de test comportait des questions factuelles, des questions amenant des listes en réponse ainsi que des questions de définition, la combinaison figurant dans la mesure score ci-dessous a été adoptée. Pour les questions de définition, les systèmes ont produit un ensemble d’items, tels la date de naissance et la fonction à une question du type
« Qui est M. X », et ce sont ces éléments qui sont jugés par les assesseurs essentiels à la réponse ou bien plus accessoires.
(
nombre d'itemsessentiels nombred'itemsacceptables)
100 autorisée Taille produits items des totale taille totale Taille totale taille autorisée taille totale taille -1 sinon autorisée taille totale taille si 1 déf Précision_ corrects essentiels items d' total Nb corrects essentiels items d' Nb Rappel_déf Rappel_déf déf Précision_ 25 Rappel_déf déf Précision_ 26 Moy _ produites réponses de total Nb distinctes correctes réponses de Nb liste Précision_ correctes réponses de total Nb distinctes correctes réponses de Nb te Rappel_lis liste Précision_ te Rappel_lis liste Précision_ te Rappel_lis 2 Moy _ factuelles questions de Nb correctes jugées réponses de Nb 4 1 4 1 2 1 + ∗ = = < = = + ∗ ∗ ∗ = = = + ∗ ∗ = = ∗ + ∗ + ∗ = def score liste score score_fact score_déf e score_list score_fact score
On peut le constater, toutes les mesures proposées reposent sur le rappel. Sachant que les protocoles ne proposent que cinq réponses au maximum, celui-ci est très pertinent. L’introduction de la précision a eu lieu pour évaluer les réponses de type listes. Dans ce cas, faut-il laisser les systèmes proposer un nombre indéterminé de réponses ou faut-il le limiter ? Il ne semble pas opportun de laisser les systèmes proposer trop de réponses, cela vient à l’encontre du type de tâche traitée, où l’utilisateur attend des réponses, remises dans leur contexte, mais telles qu’elles n’entraînent pas l’exploration et l’évaluation de nombreuses propositions.
4.6. La méthode d’évaluation
La méthodologie présentée ici est celle adoptée à TREC. Elle a en effet été éprouvée à plusieurs reprises et certains enseignements en ont été tirés. Lors de la première évaluation [VOO 00a], trois assesseurs ont évalué les réponses des systèmes. C’est à dire qu’en fonction de la réponse produite, et du document associé, ils avaient à estimer si la réponse était une réponse acceptable, même si, pour cette première campagne, les réponses n’avaient pas besoin d’être justifiées par le document retourné pour être considérées comme valides. Les réponses acceptables doivent être la réponse à la question, et non pas une information qui permettrait d’inférer cette réponse [SPA 03]. Or, ce type de réponse est préférable à pas de réponse du tout, aussi ce serait intéressant de les considérer dans l’évaluation.
Il a été constaté des différences d’opinion entre juges, notamment quant à ce qu’il est nécessaire de préciser dans la réponse. Pour nommer une personne, parfois le nom seul suffisait à certains mais pas à d’autres, de plus la nécessité de cette précision dépendait aussi de la question. Il en a été de même pour les lieux et pour les dates. Cependant l’évaluation relative d’un système s’est montrée stable (cf. [VOO 00a] pour le détail des tests effectués). Il a donc été décidé de ne faire juger les réponses d’un système que par un seul assesseur lors de TREC9. Seulement un certain nombre d’erreurs de jugements se sont produites, qui n’étaient pas dues à des différences d’opinion, mais à de véritables erreurs. Aussi plusieurs assesseurs ont de nouveau évalué les résultats des systèmes par la suite, et lorsqu’il y a désaccord, ceux-ci sont étudiés et une décision est éventuellement corrigée. En moyenne, il y a 5% de désaccords, dont 30% sont des erreurs.
4.7. Les résultats
Il est intéressant de comparer les résultats lors des différentes campagnes, ceux-ci étant alors significatifs du fait que le problème est résolu ou non. D’autre part, la création de ces campagnes a permis la constitution de jeux de test et d’apprentissage. La mise à disposition des patrons des réponses correctes sous forme d’expressions régulières permet d’évaluer un système au cours de sa mise en œuvre ; et même si cette évaluation est un peu plus laxiste, elle est néanmoins significative. Breck et al. [BRE 02] proposent une première version d’une méthode un peu différente pour évaluer automatiquement des réponses, fondée sur la présence de certains mots-clés, sans que la formulation exacte entre en jeu.
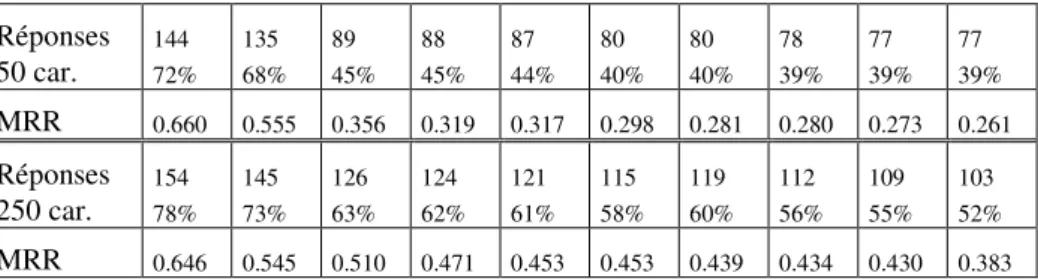
TREC8 comportait 200 questions et deux tâches. Pour la première, les systèmes devaient retourner 5 réponses ordonnées ne dépassant pas 50 caractères chacune ; pour la seconde, la taille autorisée était de 250 caractères. La Table 1 montre les résultats des dix premiers systèmes à chacune des tâches, avec le nombre de
questions résolues et leur score. Dès cette première campagne, les systèmes étaient capables de répondre à 50% des questions lorsqu’ils produisaient un passage, équivalent à une ou deux phrases. Leurs performances étaient moindres lors de l’extraction d’un passage court, et cela a révélé la nécessité d’aller au-delà des traitements numériques classiquement utilisés en recherche d’information, afin de leur associer des traitements plus élaborés de traitement de la langue. S’est aussi révélée la nécessité d’utiliser des connaissances sémantiques afin de gérer la variabilité de la langue. Réponses 50 car. 144 72% 135 68% 89 45% 88 45% 87 44% 80 40% 80 40% 78 39% 77 39% 77 39% MRR 0.660 0.555 0.356 0.319 0.317 0.298 0.281 0.280 0.273 0.261 Réponses 250 car. 154 78% 145 73% 126 63% 124 62% 121 61% 115 58% 119 60% 112 56% 109 55% 103 52% MRR 0.646 0.545 0.510 0.471 0.453 0.453 0.439 0.434 0.430 0.383
Table 1. Résultats des 10 premiers systèmes à TREC8
À la différence de TREC8, TREC9 comportait plus de questions, 700, et plus de documents (3 gigasoctets). Parmi les 700 questions, 200 étaient des reformulations produites à partir de certaines questions ; seules 682 ont été jugées, les autres étant trop ambiguës ou comportant des fautes d’anglais.
Réponses 50 car. 453 66% 297 43% 287 42% 280 41% 288 42% 281 41% 246 36% 243 35% 231 34% 229 34% MRR 0.58 0.32 0.32 0.32 0.29 0.28 0.25 0.23 0.23 0.23 Réponses 250 car. 587 86% 419 61% 418 61% 417 61% 388 57% 375 55% 383 56% 363 53% 334 49% 357 52% MRR 0.76 0.46 0.46 0.46 0.42 0.41 0.39 0.39 0.39 0.37
Table 2.Résultats des 10 premiers systèmes à TREC9
Les résultats (cf. Table 2) se sont montrés assez stables, et même en légère diminution malgré l’amélioration des systèmes. Cela est sans doute dû au fait que les questions comportaient plus de variations linguistiques par rapport à la formulation des réponses car elles n’avaient pas été conçues à partir des documents. Il faut aussi
noter l’écart important entre le premier système et les autres, signe que toutes les équipes n’ont pas atteint le même niveau de technologie.
Les résultats Table 3 illustrent le fait que les questions étaient plus difficiles à TREC10, celles-ci comportant beaucoup de demandes de définitions, dont les réponses sont aussi plus difficiles à évaluer. Aussi, ce type de questions a été supprimé pour TREC11 et les systèmes se sont concentrés sur la production de la seule réponse, et d’une seule réponse par question. Beaucoup de systèmes ont amélioré leurs résultats en se servant du Web comme source de connaissances supplémentaires. Par ailleurs, l’évaluation du fait que la réponse existe ou non dans le corpus semble une tâche difficile pour la plupart des systèmes puisque seul le premier obtient une précision de 0.76 pour ces réponses et seulement cinq systèmes dépassent 0.25. Réponses 50 car. 348 70% 329 66% 307 61% 295 59% 288 58% 280 56% 282 56% 280 56% 258 52% 236 47% MRR 0.68 0.57 0.48 0.43 0.43 0.41 0.39 0.36 0.35 0.33
Table 3.Résultats des 10 premiers systèmes à TREC10
La Table 4 confirme la supériorité du premier système, et avec 83% de questions résolues, on peut sans doute considérer que le problème tel qu’il a été posé à TREC11 est résolu. En effet, cette année-là, 80% des questions environ attendaient une entité nommée en réponse. Il a été décidé de construire un jeu de questions mêlant différents types de questions pour TREC12 et de réintroduire une tâche concernant la production de passages, afin de constituer des corpus d’apprentissage pour ce composant utilisé par tous les systèmes de question-réponse, préféré à la sélection de documents dans leur intégralité.
Réponses 50 car. 415 83% 271 54% 290 58% 192 38% 179 36% 184 37% 142 28% 149 30% 133 27% 181 36% CWS 0.856 0.691 0.610 0.589 0.588 0.512 0.499 0.498 0.497 0.496
Table 4.Résultats des 10 premiers systèmes à TREC11
Il est intéressant de comparer ces résultats avec ceux obtenus par les systèmes participant à NTCIR. Une variante a été introduite puisque les systèmes devaient fournir toutes les réponses existant dans le corpus dans l’une des tâches (ligne
MF-toutes Table 5). Les questions de type liste n’étant pas typées dans le jeu de test mais elles contenaient explicitement le nombre d’éléments à trouver. Pour cette dernière, la mesure adoptée, MF, est la moyenne des f-mesures pour chaque question, où le rappel est calculé en fonction du nombre de résultats donnés par chaque système.
MRR-1 rép. 0.61 0.52 0.46 0.39 0.38 0.37 O.36 0.31 0.3 0.3 MF-toutes 0.36 0.27 0.21 0.16 0.15 0.14 0.09 0.06 0.06 0.05
Table 5.Résultats des 10 premiers systèmes à NTCIR03
Le premier système de la deuxième tâche a toujours retourné une liste avec une seule réponse et a trouvé 40% de réponses exactes, un autre a systématiquement retourné dix réponses, qui contiennent 45% de bonnes réponses, et a obtenu un score de 0.09. Trois quarts des questions attendaient une seule réponse. Les systèmes présents à l’évaluation sur le japonais ont mis en oeuvre surtout des approches numériques, même pour l’extraction de la réponse, toutefois trois quarts des questions portaient sur des entités nommées classiques.
5. Facteurs affectant les performances d’un système de question-réponse
Des analyses ont été menées afin de déterminer les facteurs ayant une influence sur les performances d’un système de question-réponse. Nous ne retiendrons dans cette section que les facteurs extérieurs aux systèmes. Le premier facteur testé dans Light et al. [LIG 01] est la redondance d’une réponse dans le corpus. Ils ont étudié 50 questions de TREC8 en fonction du nombre de réponses produit par les systèmes et ont mis en évidence une forte corrélation entre les performances des systèmes et la redondance des réponses dans le corpus. Par exemple 80% des systèmes trouvent la réponse à une question ayant 67 occurrences dans le corpus (la question au sujet de Peugeot). En revanche, les questions n’ayant qu’une réponse dans le corpus sont résolues par 2 à 60% des systèmes selon les questions et 27% des systèmes en moyenne leur trouvent une réponse alors que 50% environ réussissent sur des questions ayant un facteur de redondance de sept. Il aurait été intéressant d’adjoindre à cette analyse la notion de difficulté de résolution des questions. Moldovan et al. [MOL 03] en propose une classification en cinq types :
— réponse factuelle : la réponse est extraite telle quelle ou moyennant quelques variations morphologiques simples. Une approche mot-clés peut alors tout à fait convenir.
— réponse issue d’un raisonnement simple : la réponse est extraite d’un court passage toujours mais amène à recourir à des connaissances sémantiques pour gérer
des variations ou élaborer un raisonnement simple. Ces questions sont du type
« Comment est mort Socrate ? » où la réponse « en buvant du vin empoisonné » nécessite de faire le lien entre mort et empoisonner.
— fusion de réponses : les éléments de réponses sont répartis sur plusieurs documents et il s’agit de les assembler en un tout cohérent. Cela peut aller de simples listes à la constitution de modes d’emploi.
— interaction à gérer : ce sont les questions s’enchaînant dans un même contexte, relatif à la première question
— raisonnement par analogie : les réponses ne sont pas explicites dans les documents et entraînent la décomposition en plusieurs questions et leur interprétation par analogie aux faits existant.
Parmi les 1393 questions de TREC, Moldovan et al. en répertorient 71% en classe un et 29% en classe deux. Les deux classes suivantes correspondent aux deux autres pistes de TREC, et la cinquième ne comporte aucune des questions TREC. Une piste consisterait à tenir compte de la difficulté des questions pour établir les jeux de tests. Comme on a pu le voir, beaucoup de systèmes se comportent bien sur les tâches actuelles, aussi complexifier le jeu de questions, non pas du point de vue du type de la demande, mais selon la complexité de résolution, serait un autre moyen de faire progresser le domaine.
De la même manière, Light et al. ont montré que la présence de plusieurs occurrences du type de réponse attendu dans les passages sélectionnés est un facteur qui peut être pénalisant si les systèmes ne disposent pas de processus d’extraction élaboré. Selon leur étude, un système qui sélectionnerait juste l’extrait du type attendu ne peut dépasser 59% de précision, même en cas de processus amont parfaits. Si on se limite à des types d’entités nommées moins ambigus, c’est-à-dire en supprimant les types GN (un groupe nominal en réponse) et GV (un groupe verbal), le taux d’ambiguïté reste néanmoins important (30%). Cette analyse peut aussi conduire à évaluer l’ensemble des types de réponses attendus définis dans les systèmes.
Un système de question-réponse est un système complexe, comportant de nombreux modules (cf. section 3) et sa réalisation et l’amélioration de ses performances requièrent que les performances de chacun de ses composants ou de l’architecture globale soit évaluées, afin de déceler les points faibles et les raisons des erreurs.
6. Evaluation des composants d’un système de question-réponse
Plusieurs travaux portent sur l’évaluation des composants d’un système. Pour une part, ce sont les auteurs des systèmes qui ont établi ces protocoles ([MOL 03], [BER 00], [ITT 01], [HUR 02], [MON 03]) afin de déterminer les points faibles éventuels de leurs approches ou au contraire de montrer l’efficacité de l’un de leurs composants. Ces travaux procurent des éléments qui pourraient permettre d’établir des cadres d’évaluation systématiques, voire des plates-formes. Il n’est en effet pas facile d’établir quelles approches sont efficaces pour chaque processus à réaliser, et quel peut être l’impact d’un processus sur le résultat global. On ne peut comparer à l’heure actuelle que les résultats finaux, sans savoir pourquoi un système se comporte comme il le fait.
Un autre type de travail consiste à proposer un cadre d’évaluation d’un composant tel qu’il a été réalisé dans plusieurs systèmes [TEL 03]. Il s’agit ici d’évaluer l’étape de recherche des passages pertinents, en liaison avec le type de moteur de recherche des documents utilisé. Cela va vers la constitution de protocoles d’évaluation pour les composants – beaucoup de matériel existe à l’heure actuelle pour que ce soit envisageable – et leur réutilisation systématique dans le cadre de campagnes d’évaluations serait source d’enseignements riches.
7. Conclusion
Les campagnes d'évaluation existantes reprennent toutes les mêmes principes : questions factuelles, extraction de la réponse uniquement et recherche de toutes les réponses dans le corpus. Certains systèmes y obtiennent d’ailleurs d’excellents résultats. Afin d'étudier des problèmes plus complexes, un programme américain a été lancé, le programme AQUAINT9. On y retrouve des points figurant dans le
«roadmap» [BUR 01] rédigé par un ensemble de chercheurs. Ainsi les futurs systèmes de question réponse devront pouvoir réaliser des interprétations en contexte, de la recherche multidocuments et multimédia afin de proposer une réponse complète, être multilingues et concevoir une présentation appropriée des réponses. La recherche multidocuments a été introduite dans la dernière évaluation TREC en 2003, et la recherche multilingue fait partir de la campagne CLEF. La réalisation de raisonnements plus poussés devront pouvoir être évalués et l’on se ramène alors au problème de l’évaluation de processus de TAL (résolution d’anaphores, analyse sémantique de phrases) et d’IA (inférence et justification). Ce sont des points difficiles, mais la tâche question-réponse permet de les aborder et d’y apporter une réponse par un travail sur une classification des questions en fonction des processus nécessaires à leur résolution.
Outre ces aspects, l'accent devra aussi être mis sur la fiabilité des réponses données et leur justification. On peut ainsi réfléchir à une évaluation des réponses en fonction de leur intérêt pour l’utilisateur : pénaliser les réponses qui ne sont d’aucune aide, même si elles sont correctes, pénaliser des réponses fausses plus que l’absence de réponse de manière à ce que les systèmes sachent évaluer leurs propositions. Il est en effet préférable de ne pas donner de réponse que de donner des réponses fausses.
Le dernier point important consiste à réfléchir à une évaluation centrée sur l’utilisateur, autorisant l’interactivité en cas de demandes ambiguës, et l’élaboration de modèles utilisateurs. Le travail effectué en dialogue homme-machine peut sans doute servir de base à l’établissement de tels protocoles, et dans ce cadre, ce ne serait plus uniquement la justesse d’une réponse qui serait évaluée, mais aussi la satisfaction de l’utilisateur.
8. Bibliographie
[BAR 81] Barr A., Feigenbaum E. A., (Eds), The Handbook of Artificial Intelligence, vol1, William Kaufmann, Inc, pp. 281-316, 1981
[BEL 00] Belkin N. J., Keller A., Kelly D., Perez-Carballo J., Sikora C., Sun Y., Support for Question-Answering in Interactive Information Retrieval : Rutgers’ TREC-9 Interactive Track Experience, Proceedings of TREC9, Gaithersburg, MD, 2000.
[BER 03] Berthelin J.B., Grau, B., Hurault-Plantet, M., “ Two levels of evaluation in a complex NL system” , workshop on Open-Domain Question-Answering, ACL, 2000. [BRE 02] Breck E. J., Burger J. D., Ferro L., Hirshmann L., House D., Light M., Mani I.,
“How to Evaluate your Question Answering System Every Day … and Still Get Real Work Done”, Proceedings of the second conference on Language Resources Evaluation
(LREC 2002), 2002
[BRI 01] Brill E., Lin J., Banko M., Dumais S., Ng A., “Data-Intensive Question Answering”,
Proceedings of TREC10, Gaithersburg, MD, 2001
[BUR 01] Burger J., Cardie C., Chaudhri V., Gaizauskas R., Harabagiu S., Israel D., Jacquemin C., Lin C.-Y., Maiorano S., Miller G., Moldovan D., Ogden B., Prager J., Riloff E., Singhal A. Shrihari R., Strzalkowski T., Voorhees E., Weishedel R., “Issues, Tasks and Program Structures to Roadmap Research in Question & Answering (Q&A)”,
http://www-nlpir.nist.gov/projects/duc/roadmapping.html
[CHA 03] de Chalendar G., Ferret, O., Grau, B., ElKateb F., Hurault-Plantet, M., Monceaux L., G., Robba I., Vilnat A., « Confronter des sources de connaissances différentes pour obtenir une réponse plus fiable », actes de la conférence TALN, Nancy, 2003
[CHU 02] Chu-Caroll J., Prager J., Welty C., Czuba K., Ferucci D., “A Multi-Strategy and Multi-Source Approach to Question Answering”, Proceedings of TREC11, Gaithersburg, MD, 2002.
[CLA 01] Clarke C.L.A., Cormack G.V., Lynam T.R., Li C.M.,McLearn G.L., “Web Reinforced Question Answering (MultiText Experiments for TREC 2001)”, Proceedings
of TREC10, Gaithersburg, MD, 2001
[FEL 98] Fellbaum C., WordNet: An Electronic Lexical Database, MIT Press, Cambridge, MA, 1998.
[FUK 03] Fukumoto J., Kato T., Masui F.,Question Answering Challenge (QAC-1) : An Evaluation of Question Answering Task at NTCIRWorkshop 3, Proceedings of the third NTCIR Workshop, 2003
[GRI 95] Grishman R., Sundheim B., “Design of the MUC6 evaluation”, Proceedings of
MUC-6, Morgan Kauffmann Publisher, Columbia, MD, 1995.
[HAR 00] Harabagiu, S., Pasca, M., Maiorano, J., “Experiments with Open-Domain Textual Question Answering”. Proceedings of Coling'2000, Saarbrucken, Germany, 2000. [HAR 01] Harabagiu S., Moldovan, D., Pasca M., Mihalcea R., Surdeanu R., Bunescu M.,
Girju R., Goodrum R., Rus V., Morarescu P. “The Role of Lexico-semantic Feedback in Open-Domain Question Answering”, proceedings of the ACL, Toulouse, 2001
[HIR 01] Hirschman L., Gaizauskas R., “Natural language question-answering: the view from here”, Journal of Natural Language Engineering, p. 1-25, 2001.
[HIR 99] Hirshmann L., Light M., Breck E. J., Burger J. D., “Deep Read: A reading comprehension system”, Proceedings of the 37th Annual Meeting of the Association for
Computational Linguistics, pp.325-332, 1999
[HUR 02] Hurault-Plantet, M., Monceaux L., “Cooperation between black box and glass box approaches for the evaluation of a question-answering system”. Proceedings of theThird
International Conference on Resources and Evaluation ( LREC), Las Palmas, pp. 577-584, 2002
[ITT 01] Ittycheriah, A., Franz, M. & Roukos, S., “IBM’s Statistical Question Answering System – TREC-10”. Proceedings of the Text retrieval conference, TREC 10,
Gaithersburg, MD. NIST Eds., 2001
[LEH 77] Lehnert W., “Human and computational question answering”, Cognitive Science, vol. 1, p. 47-63, 1977.
[LIG 01] Light M., Mann G. S., Riloff E., Breck E., “Analyses for Elucidating Current Question Answering Technology”, Journal of Natural Language Engineering, 2001. [LIN 03] Lin J., Quann D., Sinha V., Bakshi K., Huynh D., Katz B., Karger D. R., “What
Makes a Good Answer? The Role of Context in Question Answering”, Proceedings of the
Ninth IFIP TC13 International Conference on Human-Computer Interaction (INTERACT 2003, 2003
[MAG 02] Magnini B., Negri M., Prevete R., Tanev H., “Mining Knowledge from Repeated Co-occurrences: DIOGENE at TREC 2002”, Proceedings of the Text retrieval
[MAG 03] Magnini B., Romagnoli S., Vallin A., Herrera J., Penas A., Peinado V., Verdejo F., de Rijke M., “Mining The Multiple Language Question Answering Track at Clef 2003”,
Proceedings of CLEF, 2003
[MOL 00] Mollá Aliod D., Schwitter R., Hess M., Fournier R., « Extrans, an answer extraction system », Traitement Automatique des Langues, vol. 41, n°2, p. 496-522, 2000. [MOL 02] Moldovan, D., Harabagiu S., Girju R., Morrarescu P., Lacatusu F., Novishi A., Badulescu A., Bolohan O., “LCC Tools for Question Answering”, Proceedings of the
Text retrieval conference, TREC11, Gaithersburg, MD. NIST Eds, 2002
[MOL 03] Moldovan, D., Pasca M., Harabagiu S., Surdeanu M., “Performance Issues and Error Analysis in an Open-Domain Question Answering system”, ACM transactions on
Information Systems (TOIS), p. 133-154, 2003
[MOL 99] Moldovan D. et al., “LASSO: a tool for surfing the answer net”, TREC 8
Proceedings, pp 65-73, 1999.
[MON 03] Monz C., “Document retrieval in the Context of Question Answering”,
proceedings of ECIR 03, p. 571-579, 2003
[SCH 77] Schank R. C., Abelson R. P., Scripts, plans, goals and understanding, Erlbaum, 1977
[SOU 01] Soubbotin, M. M., Soubbotin, S. M., “Patterns of Potential Answer Expressions as Clues to the Right Answers”. Proceedings of the Text retrieval conference, TREC 10, Gaithersburg, MD. NIST Eds. , 2001.
[SOU 02] Soubbotin, M. M., Soubbotin, S. M., “Use of patterns for Detection of Likely Answer Strings: a Systematic Approach”, Proceedings of the Text retrieval conference,
TREC 11, Gaithersburg, MD. NIST Eds., 2002
[SPA 03] Spärk Jones K., “is question answering a rational task? ”, Proceedings of theColognet-Elsnet Symposium: Question and Answers: Theoritical and Applied Perspectives, 2003
[TEL 03] TellexS., Katz B., Lin J., Fernandes A., Marton G., Quantitative Evaluation of Passage retrieval Algorithms for Question Answering, Proceedings of the 26th annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2003), Student Paper, 2003
[VOO 00a] Voorhees E. M., Tice D.M.,“Building a question answering test collection”,
Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and
Development in Information Retrieval, pp. 200-207, 2000
[VOO 00b] Voorhees E. M., “Overview of the TREC-9 Question Answering track”,
Proceedings of the Text retrieval conference, TREC 9, Gaithersburg, MD. NIST Eds., 2000
[VOO 01a] Voorhees E. M., “The TREC question answering track”, Journal of Natural
[VOO 01b] Voorhees E. M., “Overview of the TREC 2001 Question Answering track”,
Proceedings of the Text retrieval conference, TREC 2001, Gaithersburg, MD. NIST Eds., 2001
[VOO 02] Voorhees E. M., “Overview of the TREC 2002 Question Answering track”,
Proceedings of the Text retrieval conference, TREC 2002, Gaithersburg, MD. NIST Eds., 2002