Deep Linguistic Lensing
by
Amin Manna
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
September 2018
c
○ Massachusetts Institute of Technology 2018. All rights reserved.
Author . . . .
Department of Electrical Engineering and Computer Science
August 18, 2018
Certified by . . . .
Karthik Dinakar
Research Scientist, MIT Media Lab
Thesis Supervisor
Certified by . . . .
Roger Levy
Associate Professor, Dept of Brain and Cognitive Sciences
Thesis Supervisor
Accepted by . . . .
Katrina LaCurts
Chairman, Department Committee on Graduate Theses
Deep Linguistic Lensing
by
Amin Manna
Submitted to the Department of Electrical Engineering and Computer Science on August 18, 2018, in partial fulfillment of the
requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
Abstract
Language models and semantic word embeddings have become ubiquitous as sources for machine learning features in a wide range of predictive tasks and real-world ap-plications. We argue that language models trained on a corpus of text can learn the linguistic biases implicit in that corpus. We discuss linguistic biases, or differences in identity and perspective that account for the variation in language use from one speaker to another. We then describe methods to intentionally capture “linguistic lenses”: computational representations of these perspectives. We show how the cap-tured lenses can be used to guide machine learning models during training. We define a number of lenses for author-to-author similarity and word-to-word interchangeabil-ity. We demonstrate how lenses can be used during training time to imbue language models with perspectives about writing style, or to create lensed language models that learn less linguistic gender bias than their un-lensed counterparts.
Thesis Supervisor: Karthik Dinakar Title: Research Scientist, MIT Media Lab Thesis Supervisor: Roger Levy
Acknowledgments
First and foremost, I would like to thank my thesis supervisors, Karthik Dinakar and Roger Levy, for being constant sources of inspiration and advice. I spent a wondrous year letting my curiosity dictate my research questions, and it would not have been possible but for their trust and patience.
I am grateful to William Flesch, Micah Nathan, Shariann Lewitt, and Stacie Slotnick for their suggestions and ideas about English literature and writing . I am thankful for Barbara Zinn for reading my thesis as many times as I did, and for spending hours critiquing visualizations of author embeddings and lenses.
At the Media Lab, I am grateful to Joi Ito for his guidance and ideas. Joi and Karthik, alongside Tenzin Priyadarshi, Andre Uhl, and my fellow classmates, are responsible for making my last class at MIT, Principles of Awareness, a fantastic experience. At the WCC, Betsy Fox and Susan Spilecki critiqued my writing while simultaneously teaching me about writing style. At the MIT Linguistics department, Norvin Richards, Donca Steriade, David Pesetsky, Sabine Iatridou were among those who set me on this path.
I would like to thank James Frost for working his administrative magic in the Media Lab, and Dillon Erb and John Hilmes at Paperspace for providing me with GPUs and encouraging me to blog.
Finally, thank you to my friends - Aritro Biswas, Tally Portnoi, Carlos Henriquez, Nora Kelsall, Amir Farhat, Erica Yuen, Dou Dou, Antony Arango, Anvita Pandit, Daniel Mirny, Linda Jing, Alan Samboy, and Mayuri Sridhar - without whom this thesis would not have been completed. And to my brother, Rami Manna, who is my friend as well.
My parents were so excited when I managed to express my ideas in non-technical terms. I’m grateful to my entire family for cheering me on, and to the other families I’ve found in MEET (Middle East Entrepreneurs of Tomorrow) and in Cambridge and NYC’s dance scenes.
Contents
1 Introduction 13
1.1 Three Theoretical Forms of Lensing . . . 16
1.1.1 Lensing of Configuration Spaces . . . 16
1.1.2 Lensing of Parameter Spaces . . . 16
1.1.3 Lensing of Evidential Spaces . . . 17
1.2 Two Practical Forms of Lensing . . . 18
1.3 Introduction to Language Modeling . . . 18
1.3.1 Embedding Models . . . 19
1.3.2 Paragraph Vector . . . 19
1.3.3 Authorship Attribution and Style Embeddings . . . 20
1.4 Scope of the Thesis and Contributions . . . 22
2 Linguistic Lenses - Motivation 25 2.1 Lenses in Human Language Consumption . . . 25
2.1.1 Comprehension . . . 25
2.1.2 Quality Judgments . . . 27
2.2 Lenses in Human Language Production . . . 30
2.2.1 Lenses in Writing . . . 30
2.2.2 Lenses in Speech . . . 31
2.2.3 Implicit Lenses in Text Corpora . . . 31
3 Linguistic Lenses - Collection 39
3.1 Similarity Lenses and Confusion Lenses . . . 39
3.2 Corpus: The Gutenberg Story Dataset . . . 40
3.3 Lenses for Style . . . 41
3.3.1 Goodreads Readership Lens . . . 42
3.3.2 Google Scholar Lens . . . 46
3.4 Lenses for Word Choice . . . 47
3.5 Asymmetric Confusion Lenses . . . 50
4 Comprehension Lensing for Language Models 53 4.1 Lensing Embeddings . . . 53
4.2 Case Study: Paragraph Vector with Author Embedding Similarity Lens 54 4.2.1 Un-lensed Author Embedding Models . . . 54
4.2.2 Method . . . 56
4.2.3 Evaluation Metrics . . . 57
4.2.4 Results . . . 58
4.2.5 Analysis . . . 61
5 Production Lensing for Language Models 63 5.1 Lensing Softmax . . . 63
5.2 Case Study: Text Generation with Word Confusion Lens . . . 67
5.2.1 Method . . . 67 5.2.2 Results . . . 68 6 Conclusions 77 6.1 Summary of Contributions . . . 77 6.2 Future Work . . . 78 A Code Samples 79
List of Figures
1-1 Lensing involves a human-in-the-loop interpretive process . . . 15
1-2 Word2Vec CBOW: A shallow neural net that predicts a word, given its context. . . 19
1-3 Left to Right: PV-DM, PV-DBOW, and a variation on PV-DBOW that jointly learns word embeddings. . . 20
2-1 Critics vs Audience Average Score . . . 28
2-2 Speaker Word Production Variation by Location . . . 32
2-3 WS-353 Respondent Bias . . . 35
2-4 Google News Word2Vec embeddings . . . 36
3-1 Goodreads “Similar Authors” page for Oscar Wilde1 . . . 42
3-2 Goodreads Readership Lens . . . 43
3-3 Goodreads Readership Lens . . . 44
3-4 Goodreads Readership Lens . . . 45
3-5 “Oscar Wilde” and “Jane Austen” co-occur 6,460 times. . . 46
4-1 Author Embedding Models . . . 55
4-2 Correlation with held-out similarity lens . . . 59
4-3 Average correlation with word similarity datasets . . . 60
5-1 Generic language model to predict next word . . . 64
5-2 Training with Negative Log-Likelihood for Next Word Prediction . . . 64
5-3 The target word is a delta distribution . . . 65
5-5 Test set perplexity scores achieved by the 3 models . . . 69
5-6 Occupational Stereotypes in Generated Text . . . 73
A-1 Pairwise Similarity Function. Pytorch . . . 79
List of Tables
2.1 WordSim353 Word Similarity Judgments . . . 34
3.1 7 Gender Pronouns: A Gender-blind Confusion Lens . . . 49
3.2 7 Reversed Gender Pronouns: A Confusion Lens . . . 49
4.1 PV-DM Un-Lensed Model Hyperparameters . . . 56
5.1 Test set perplexity scores achieved by the 3 models . . . 68
5.2 Summary of occupational gender stereotypes in generated text com-pletions . . . 73
Chapter 1
Introduction
Learned bias is a topic that has recently been gaining traction in machine learn-ing community, givlearn-ing rise to the FAT-ML1 movement for Fairness, Accountability, and Transparency in Machine Learning. Biased algorithms in computer vision are trained predominantly on white male faces [7], and Google’s algorithms famously drew attention by mis-classifying people of color as gorillas [16]. Recidivism estima-tion algorithms used in the United States criminal justice system have been diagnosed with learned racism[24].
Similar examples of bias can be found in the field of Natural Language Processing (NLP). Language identifiers are more likely to not recognize AAE2 than SAE3, and
may filter AAE-aligned tweets out of “English” NLP training data [4]. And in speech recognition, YouTube auto-captioning more accurately transcribes male than female speakers [36].
In response, some companies are making an effort to create more diverse datasets. For example, after their gender classifier was shown to have a difference of 34.4% in error rate between lighter males and darker females [7], IBM promised to release a large dataset for facial analysis tasks, “equally distributed across skin tones, genders, and ages” with the explicit goal that it will be used to study bias in artificial intelli-gence [31]. And, efforts are being made to develop techniques for de-biasing machine
1fatml.org
2African American English 3Standard American English
learning algorithms. However, only a handful of these address biases in NLP. Our work will join their ranks.
Machine learning tasks are often framed as the problem of sampling from a latent variable distribution, with the goal of learning to approximate the distribution in inference. In this framework, machine learning datasets are ground truth samples. That is, they are considered to be unbiased representations of human understanding. In reality, a single corpus may contain data created by many humans, who have dif-ferent opinions and perspectives. The corpus, in turn, may be interpreted difdif-ferently by different human observers. For example, where one reader asked to write “like Shakespeare” may produce a couple lines of iambic pentameter, another reader might spin a tale of star-crossed lovers and mistaken identities, in Modern English. Cur-rently, most machine learning models don’t have a technique to deal with situations where the ground truth is subjective.
Dinakar et al. introduce lensing, “a mixed-initiative technique to (1) extract ‘lenses’ or mappings between machine-learned representations and perspectives of hu-man experts, and (2) generate ‘lensed’ models that afford multiple perspectives of the same dataset” and formally define it as “the iterative refinement of a latent variable model’s configuration, parameter, or evidential spaces using human priors, with the view of imbuing the human priors formally to the latent variable model’s representa-tion” [11].
A machine learning dataset is typically created by the great labor of many human annotators, who provide annotations for every example in the dataset. In lensing, we introduce an additional individual, who may be a domain expert, or whose point of view is more relevant, or who is more knowledgeable than the annotators. We refer to this individual as the informant. Since the informant’s time is typically very valuable, and it is not feasible for them to annotate an entire dataset, we have to design a technique that can more succinctly capture their perspective. Where traditional (un-lensed) machine learning models applies the powerful techniques of Bayesian statistics to estimate latent variables, lensed models combine this with an additional strength: human judgment and domain-specific expertise.
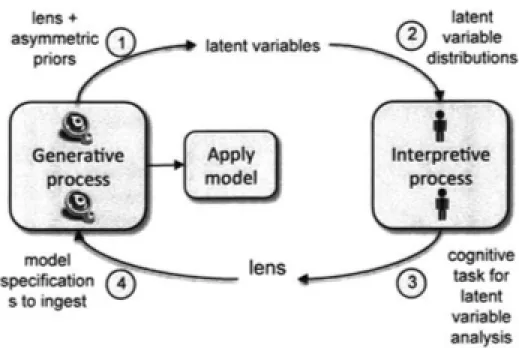
Lensing seeks to address the problem of biased algorithms, by translating between human perspectives and machine representations. Lensed machine learning models have an extra human-in-the-loop step in the machine learning process. Since machine learning is famously uninterpretable, this step involves an interpretive process that translates between the model’s training state and an intelligible representation that a human informant can critique. Then, the informant’s criticism is translated back and used to guide the machine learning algorithm, as seen in Figure 1-1. This is an itera-tive process that continues until the informant is satisfied. It allows us to intentionally explore the same data in different ways and infer alternate generalizations.
Figure 1-1: Lensing involves a human-in-the-loop interpretive process Source: Dinakar et al. [11], building in the spirit of model criticism [3]
Intuitively, lenses are mappings between human informant intuitions and machine representations.
1.1
Three Theoretical Forms of Lensing
Dinakar et al. [11] categorize lensing techniques into three different classes: config-urational, parametric, and evidential lensing. For completeness, we provide a brief description of each, but our work will focus exclusively on parametric lensing.
1.1.1
Lensing of Configuration Spaces
Configurational lensing seeks to capture an informant’s perspective on a latent vari-able space, and imbue a model with that information (or “lens”) during training.
In practice, configurational lensing is reminiscent of a grid search over model hyper-parameters. However, theoretically, it is more analogous to model criticism, in that the hyper-parameter search space is not predetermined, but explored according to the informant’s intuitions.
An example [11] of configurational lensing, is in setting the 𝐾 parameter in Latent Dirichlet Allocation (LDA). LDA is an algorithm for topic modeling, where it is assumed that all words in a document are drawn from a set of 𝐾 topics. Here, the informant is shown words labeled as coming from some topic, and asked to answer yes/no whether the words form a coherent topic. Instead of having to choose 𝐾 at the start of the algorithm, the algorithm can update its best guess for 𝐾, based on the informant’s intuitions.
1.1.2
Lensing of Parameter Spaces
Parameter lensing, like Configuration lensing, seeks to capture an informant’s per-spective on a latent variable space, and imbue a model with that information during training. However, in parameter lensing, a new variable, the lens, is introduced into the model’s objective function. The posterior is then conditioned not only on the model’s prior but also on the lens of the informant.
In lensing of parameter spaces, we extract the informant prior, i.e., a lens, and then condition the latent parameter of interest on both its natural
statistical prior and the lens [11].
L1 regularization, a familiar example, can be considered an instance of parameter lensing motivated by the researcher’s intuition that a space is sparse or that few features are relevant. A researcher can intentionally capture different parameter lenses by interviewing different informants with unique perspectives about the latent variable space.
1.1.3
Lensing of Evidential Spaces
The third type of lensing we discuss is lensing of evidential spaces. Often, the hidden layers learned by a machine learning model - even a well performing model - may not reflect the perspective of a domain expert. Moreover, a single informant may not have the expertise relevant to the entire latent variable space represented by the dataset. In this case, it may be difficult to use configuration or parameter lensing.
Dinakar et al. define lensing of evidential spaces as
the splitting up of data into subsets, using the perspective of the informant after she examines the latent variables estimated from an earlier [...] model [11].
Evidential lensing seeks to directly capture an informant’s intuitions about the dataset. Suppose we have a model for learning writing style embeddings for the writers in a corpus. Our professor of English literature may look at our clustering of writers, and remark that because our writers are so diverse, the only meaningful factor they are being clustered by is topic. He or she might remark that we need to partition our training dataset according to topic (that is, for each cluster of authors, their joint works are extracted to form a new dataset), and then retrain separate models for each topic. Then, new examples can be sent to the appropriate model in inference.
1.2
Two Practical Forms of Lensing
We further classify lenses along a new axis and label them as either structured or unstructured.
We propose that lensing, whether it falls into the theoretical classes of para-metric, evidential, or configurational lensing, may be structured or unstructured in practice. Structured lenses are lenses that can be completely captured before model training time. A structured lens, when it is possible to collect one, contains the an-swer (or a formula to get an anan-swer) for every question you would have needed to ask an informant during training. Unstructured lenses may be impossible to express, perhaps because the informant may not actually know how to explain their intuitions. Because deep learning is often a time consuming process, and in practice multiple ver-sions of a model are often trained in parallel with different hyper-parameters, it can be tedious or untenable for an expert informant to be provide their lens in an unstruc-tured manner. Instead, an expert may prefer to provide a detailed explanation of the process they would have performed during model criticism. If that explanation can be fully represented computationally, then you have created a lens that is identical in theory, but structured in practice.
1.3
Introduction to Language Modeling
Given a sequence of words, a statistical language model assigns it a probability of oc-currence. Language Modeling refers to natural language processing techniques that seek to learn good statistical language models, i.e. models that maximize the proba-bility of the sentences that speakers actually produce. These techniques range from dependency parsing and PCFGs to character-level RNNs to LSTMs and hybrid CNN-LSTM deep neural networks.
1.3.1
Embedding Models
Figure 1-2: Word2Vec CBOW: A shallow neural net that predicts a word, given its context.
In NLP, Embedding Models are models that learn word or character embeddings - vector representations that capture a word’s syntactic and semantic properties. Word2Vec CBOW models feature a shallow, two layer, neural network that predicts a word given its linguistic context, as shown in Figure 1-2. Other models, like Word2Vec Skipgram, can learn to predict the context given the word ??.
Once trained, Word2Vec networks are rarely used in inference. Instead, the mod-els’ most useful outputs are the learned word embeddings, which can be used in many other ML and NLP applications, such as machine translation, text generation (auto-complete), or text summarization.
Word embeddings can be “extrinsically” evaluated based on their usefulness in downstream tasks, or “intrinsically” evaluated by checking if the distance (cosine or Euclidean) between embeddings reflects speakers’ word similarity judgments. The latter metric is called Semantic Word Similarity, and we’ll discuss it in more depth in later sections. For now, just note that for an “intrinsic” metric it is highly subjective.
1.3.2
Paragraph Vector
Paragraph Vector [25] adds to traditional Word2Vec models by jointly training em-beddings for the paragraph (or document) from which the words are drawn. The
Paragraph Vector Distributed Memory model (PV-DM) is an extension of Word2Vec CBOW, in that the training objective is to predict a target word given its context words and document. The Paragraph Vector Distributed Bag of Words model (PV-DBOW) is analogous to Word2Vec Skipgram; the training objective is to predict the words given the document. A followup paper [9], mentions that jointly training word embeddings improves the quality of the paragraph vectors. Figure 1-3 shows all three of these paragraph vector models.
Figure 1-3: Left to Right: PV-DM, PV-DBOW, and a variation on PV-DBOW that jointly learns word embeddings.
Document embeddings have been shown to capture the topic of a paragraph or document. For example, NLP papers on arXiv may form a cluster in the document space. These paragraph vector models jointly train document and word embeddings, with the word embeddings serving as a representation of the local context, and the document embeddings as representations of the global context. Both contexts have been shown to be useful to the word prediction task [20].
1.3.3
Authorship Attribution and Style Embeddings
In the previous section, we discussed models which can guess a word, given its context. Another question asks whether it is possible to guess the author of a document, given its content. Authorship Attribution is the name given to the natural language processing (NLP) task that addresses this problem. Another related task asks how AI can effectively capture the writing style of an author. Despite recent advances in developing methods to answer this question, the question itself remains largely
underspecified. What, indeed, does it mean for two authors to differ in style, and how does one evaluate the intrinsic quality of the judgments made by any proposed system?
Accuracy, for authorship attribution, is a measure of the correct author inferences made by the system when presented with test sentences written by the same authors encountered in training. This metric looks fine at first glance but crumbles under scrutiny. Consider, for example, the confusion matrix generated by the system. The accuracy metric rewards a system for guessing the right author, and penalizes it equally for confusing the correct author with any other author in the dataset. A human tasked with guessing the author of a line of poetry could be forgiven for guessing the wrong poet, but they would undoubtedly be chagrined if their best guess had been a novelist, thereby revealing a fundamental failure to recognize the sample as poetry. The same rigor should be applied to the confusion matrix of an author classifier. When a system succeeds, we should ask ourselves why. When a system errs, we should ask where, and how.
A related issue is that of author embeddings. What intrinsic evaluation can we per-form to evaluate author embeddings? What is writing style? For word embeddings, which are now well established in the literature, we now have evaluation datasets containing human judgments of word similarity, and word embeddings can be as-signed a word similarity score by computing their correlation with a word similarity dataset. Although they is not typically described in these terms, this is an example of lensed evaluation; the word embeddings are evaluated through the lens of the humans (often Amazon Mechanical Turk workers) whose judgments on word similarities are combined to form the evaluation datasets. Analogously, author similarity datasets can capture different perspectives about style, providing lenses through which we can evaluate author embeddings.
1.4
Scope of the Thesis and Contributions
The motivation behind our work is the problem that linguistic biases in corpora of text are learned by language models. For example, while some linguistic biases are harmless, others are rooted in gender and ethnic stereotypes. For example, [13] identify stereotypes linking professions (e.g. housekeeper) and ethnicity (Hispanic) in Google News Word2Vec embeddings. These biases become encoded in the learned word embeddings, and when these embeddings are used in downstream tasks and sensitive applications, there are real world consequences, like the perpetuation of the societal imbalances that caused the biases in the first place.
Before introducing our response to this problem, we characterize the problem in terms of the evaluation methods that enabled it. We identify linguistic biases in the methods used to evaluate language models. We argue that the design of language model evaluation methods should contain an intentional de-biasing component rooted in human intuition. In the absence of such a component, we run the risk of systemi-cally blocking solutions to the problem, by actually penalizing language models that do a good job of filtering out undesirable linguistic stereotypes.
Then, we introduce our vision, a class of techniques, using lensing to selectively remove bias from language modeling algorithms. These techniques are inspired by Dinaker et al. 2017 [11] and share the following properties:
1. They are applied during training, and not as a post-processing step.
2. They explicitly represent the desired linguistic biases as computational linguistic “lenses”.
3. They are instances of Parameter Lensing, meaning that the “lenses” are first class members of the machine learning algorithms’ objective functions.
Respectively, these properties have the following implications:
(1) A useful lens available during training may teach a language model something that can be extended to data not specifically addressed by the lens. In
partic-ular, we will demonstrate an experiment where a lens is partitioned, and the language model achieves high correlation with the held-out lens partition.
(2) The lenses may be “unstructured”, meaning that a human-in-the-loop provides judgments in real-time during training. Or, they may be “structured”, meaning that the entire lens is defined prior to training-time. Structured lenses, when they are possible, enable us to embed algorithms with the human perspectives they represent without requiring the presence of an actual human during train-ing. Unstructured lenses are more powerful, and can be used when it is not feasible to capture judgments in advance about every possible question and a human informant is unable to provide a formula that explains their intuitions. We will define some structured lenses and use those in our experiments, but note that in every case a human (providing an unstructured lens) could be substituted for the structured lens. Requiring an actual human-in-the-loop during training is tedious and expensive, and we envision a future in which all models use lenses. Therefore, we imagine that it may be practical for most models to use structured lenses for the majority of training time, and unstructured lenses on auspicious occasions or when structured lensing is impossible.
Structured lensing is also attractive because it enables a collaborative process of lens critique and refinement as a future direction of research in artificial intelligence. We imagine that excellent structured lenses will eventually be published alongside machine learning datasets.
(3) Depending on the specific algorithm and lensing technique, keeping lenses small or sparse may be necessary to prevent the lensed version of an algorithm from being much more computationally expensive than its un-lensed counterpart. In our experiments, we keep the lenses frozen during training, and do not back-propagate changes to them. However, it may be interesting to do so in future work, because lenses are interpretable, and gradient-updates to them could provide valuable insights into a model’s training, as well as potentially useful
criticism for the lenses themselves. Dynamic lenses are out of the scope of this thesis.
We introduce two new techniques for the Parameter Lensing of computational language models - embedding similarity lensing and word confusion lensing - and demonstrate their usage experimentally. In our experiments, we explore ways to capture human perspectives on writing style by collecting author similarity judgments. Then, desiring finer control over language modeling, we shift focus to words, and attempt to construct lenses that promote clarity in writing, or that prevent language models from learning gender biases that are implicit in their training corpora.
In the next chapter, we will survey the ways in which humans differ with regards to their use of language. We will identify these variations, or “linguistic lenses”, in comprehension and in production. Finally we will observe that these variations manifest in NLP training corpora and evaluation data.
Chapter 2
Linguistic Lenses - Motivation
Our work on Linguistic Lensing is directly motivated by the empirically observed ab-sence of human consensus with regard to language use. In this chapter, we justify this claim by showing that humans differ vastly in comprehension and speaking depending on many different factors, including geography and the time period.
2.1
Lenses in Human Language Consumption
2.1.1
Comprehension
Different readers reading the same text actually come away from it with different in-terpretations and understandings. Reader-Response Criticism, pioneered by literary critic Norman Holland, holds that reading is a process of recreating text. In this school of literary theory, the lines between readers and authors are blurred. And the relationship between production and consumption of literature is non-dual, i.e. inti-mately connected and interdependent.1
Holland would attribute the differences between the reading experiences of differ-ent individuals to their varied expectations, defenses, fantasies and transformations [19, p. 184].
1Non-duality is derived from Advaita Vedanta and is the original inspiration for lensing itself, in
A Riddle
An ambiguous sentence is defined as one that has multiple readings, such that there exists a world in which its readings have different truth values. But what seems the obvious reading to one reader may go unnoticed by another reader, and even a trained linguist may fail to see all possible readings of a sentence.
In each case, lenses are at play. Consider the following example of syntactoseman-tic ambiguity:
1. The surgeon glances at her hand.
Sentence (1) has two possible readings:
1A. The surgeon is female and glances at her own hand.
1B. The surgeon glances at the hand of another, female, entity in the discourse. However, only the second reading is available to the reader with a lexicon 𝐿, such that:
𝐿(𝑆𝑢𝑟𝑔𝑒𝑜𝑛) = 𝜆𝑥 : 𝑀 𝑎𝑙𝑒(𝑥) ∧ 𝑥 is a surgeon.2
This reader is interpreting the sentence through a gender-biased linguistic lens. The real-world prevalence of this lens is the basis for the famous “surgeon” riddle:
‘Ann and her father are both seriously injured in a highway collision. An ambulance took Ann to one hospital; her father to another. When Ann is wheeled into the operating room, the shocked surgeon says, “I cannot operate on this girl. She’s my daughter.” Who is the surgeon?’[32]
Wapman et al. [2] reported that when presented with this riddle, only ∼ 15% of
respondents guessed that the surgeon is female. The actual responses covered a range of creative answers, with respondents more than three times as likely to guess that the parents were gay.
2For those unfamiliar with lambda notation, this statement can be read as follows. For the reader
An Election
Are gender-biased linguistic lenses - which affect the pronoun choices of different speakers - merely the expression of societal gender imbalances? One perspective is that since approximately 80% of surgeons (in 2015) are male [39], the linguistic preference for male pronouns in this context is just a probabilities game.
Malsburg et al. conducted a large-scale experiment during the U.S. Presidential election in 2016. They measured speaker comprehension and production preferences for gender pronouns in sentences about the next president, at various points in time leading up to the election. While the subjects’ priors on whether the next presi-dent would be female increased until the election, this world knowledge was only reflected in production, where it manifested as an increase in gender-ambiguous pro-nouns (“they/their”) at the expense of male propro-nouns (“he/his”), but no increase in female pronoun (“she/her”) production. In comprehension, Malsburg et al. reported that the population’s prior on the gender of the next president had no effect on the data, concluding that comprehension reading times instead reflect long-term gender stereotypes [38].
Therefore, we observe distinct linguistic lenses at play in speaker production, depending on speaker’s political forecasts. Even for the same speaker, we see that they use a different lens for production and comprehension.
2.1.2
Quality Judgments
If the very meaning of text is subjective - dependent on the linguistic lenses of the comprehender - we wonder if there could at least be consensus about whether a text constitutes good writing.
No. Humans love to disagree about books and authors.
What makes a good book? Human readers may focus on different stylistic ele-ments, and regularly produce conflicting judgments about their favorite authors. The Internet is full of debates on the topic, and we will list but a few examples. Critics regularly disagree with each other - see [14] and the response [10]. Even when the
crit-Figure 2-1: Critics vs Audience Average Score
Illustration of the difference between the lens of a professional critic and that of the average reader [27].
ics agree, there are often systematic differences between their professional reviews (on Book Marks) and the prevalent opinions of the masses (on Goodreads), as discussed in [27] and depicted in Figure 2-1.
This variety of opinions makes the task of learning author embeddings an attrac-tive candidate for lensing. Should a machine learning model learn author embeddings that reflect the perspective of a professional literary critic - and which critic at that - or the perspective of the regular reader? Professional critic and Slate Book Review columnist Laura Miller bears witness to the value of both perspectives.
“the internet has made it simply impossible for me to kid myself that there’s a widely shared agreement on what constitutes good writing or a good book.” [30]
In an effort to see books through a different lens, Laura Miller makes a special point to read the Amazon and Goodreads reviews left by readers unfamiliar with the world of literary criticism. Roughly translating between lenses, she asserts that books lauded by reader reviews for their “flow” are likely labeled “cliché” and unoriginal by critics.
Where beautiful sentences and unique descriptions are met with appreciation by the literary critic, their complexity might make them undesirable to the regular reader. As C.S. Lewis mordantly observes:
“it offers him what he doesn’t want, and offers it only on the condition of his giving to the words a kind and degree of attention which he does not intend to give. It is like trying to sell him something he has no use for at a price he does not wish to pay.” [26]
Our claim is that neither the perspective of the literary critic, nor the perspective of the common reader, is “correct”. However, depending on the application, one, or both may be useful.
2.2
Lenses in Human Language Production
2.2.1
Lenses in Writing
Writing employs language for the most creative of actions, in which the speaker can give themselves the most degrees of freedom. Writing style encompasses a writer’s tendencies in diction, sentence structure, rhythm, tone, and more. Therefore, rather than address writing as a whole, it is worthwhile to consider stylistic variation in each of these tools.
For instance, in the issue of sentence structure, some authors might prefer using sentence fragments and short sentences. Many authors do this for easy consump-tion by the reader, but some others delight in longer and more complex sentences. Ernest Hemingway is known for his long chains of conjunctions, which pull the reader along but don’t increase the logical complexity of the sentence. When writing fiction, Norman Mailer crafts huge and complex sentences that somehow retain the reader. William Faulkner is also known for this preference, in his novels, but his writing style shifts when he writes speeches.
In the use of diction, authors vary wildly. In extreme cases, it is possible to identify an author because they use a single word (or pair of words) that nobody else uses. Often, vocabulary choices are intentional, and the same author will shift from using high diction to low diction, or from using a large vocabulary set to a limited one, depending on the audience (children stories or technical) or the characters they’re giving voice to. On the other end of the spectrum, there are subtle preferences for certain words over other. Some are subconscious; James Pennebaker writes that it is possible to discern things about a writer just by counting the pronouns they use. Others are conscious preferences; in the pursuit of clarity, Wordsworth restricted himself to the use of simple words. Contrastingly, modern academics seeking to conform in style to previous works in the field, succumb ever deeper to “obscurantism”, the idea of employing impenetrably complex diction and syntax.
Science fiction writer Shariann Lewitt says she disproportionately favors “indigo” and “celadon” in her writing not because she likes the colors but because she likes how
they sound. Shariann’s preference for these words has nothing to do with diction. It’s about rhythm. Their syllabic structure is pleasing to her, but other authors may sub-consciously favor different patterns. These patterns may also be sub-consciously employed to influence the pace of the writing, to enforce a strict meter, or to communicate tone. A writer’s voice is a function of her attitude towards the audience and towards the material. Word choice and syntax are the tools that communicate this attitude, and they can vary wildly from person to person and genre to genre.
While many of the lenses that we describe here are harmless, they are nevertheless quite interesting. If we wanted to capture an author’s style, solely in terms of diction, then we’d like to define Wordsworth as being very far from modern academics, and misclassifying him into that cluster as a large mistake. Meanwhile, misclassifying one modern academic for another might not be as important. We’d like to show that we can define “lenses” that capture these crucial ideas.
2.2.2
Lenses in Speech
Similar variations are also observed in speech. As seen in the now popular Figure 2-2, even within a country, like the United States, there are lexicon differences linked to geographic location. Based on where you grew up, you might call something a “water fountain”, that others refer to as a “bubbler”. The accumulation of small variations like this one give rise to the unique speech patterns that distinguish different dialects and individuals.
2.2.3
Implicit Lenses in Text Corpora
When no bias is explicitly introduced to a statistical language model, the “unbiased” language model still propagates the biases of its training corpus. Like other machine learning models, language models reflect the structure of the data they are trained on. If datasets are the superposition of the lenses of their individual contributors, then text corpora are no exception, and their implicit linguistic lenses are fair game (for better or worse) for machine learning algorithms.
Figure 2-2: Speaker Word Production Variation by Location Source: [22]
For example, it is well documented [5] that word embeddings capture linguistic gender bias. Word analogy tasks that appropriately predict 𝑘𝑖𝑛𝑔 − 𝑚𝑎𝑛 + 𝑤𝑜𝑚𝑎𝑛 ≈ 𝑞𝑢𝑒𝑒𝑛 also capture gender stereotypes like 𝑑𝑜𝑐𝑡𝑜𝑟 − 𝑚𝑎𝑛 + 𝑤𝑜𝑚𝑎𝑛 ≈ 𝑛𝑢𝑟𝑠𝑒, because such stereotypes are likely to appear in large training corpora [5, 21, 37, 41]. And, when language models learn embeddings that associate adjectives like honorable with man and adjectives like submissive with woman, the trained embeddings have serious consequences when they are used in search rankings, product recommenda-tions, ad targeting, or translation [13].
2.2.4
Implicit Lenses in Evaluation Data
When language models are evaluated on held-out test and validation data, the evalu-ation data may contain the same or different implicit linguistic lenses as the training corpus. While this isn’t necessarily a problem, it’s also not always appropriate, de-pending on the application. For example, if the evaluation metric is perplexity and the evaluation corpus is a (held-out) randomized subset of the training data, then it likely shares the same biases. By using this evaluation metric, you are accepting that all linguistic lenses of the training corpus are desirable learning objectives. If instead the evaluation corpus is a separate carefully selected text corpus, then evaluation can reward desirable linguistic biases and penalize the propagation of undesirable biases. More concerning still are the lenses present in widely popular evaluation datasets like the popular WordSim353 [12]. WordSim353 contains human judgments on word pair similarities and word analogies. Touted as “intrinsic” measures of word embed-ding quality, these datasets are frequently used to evaluate word embedembed-dings trained on a variety of training corpora. However, a careful look this evaluation data reveals the political linguistic lens of its creators and/or the surveyed individuals.
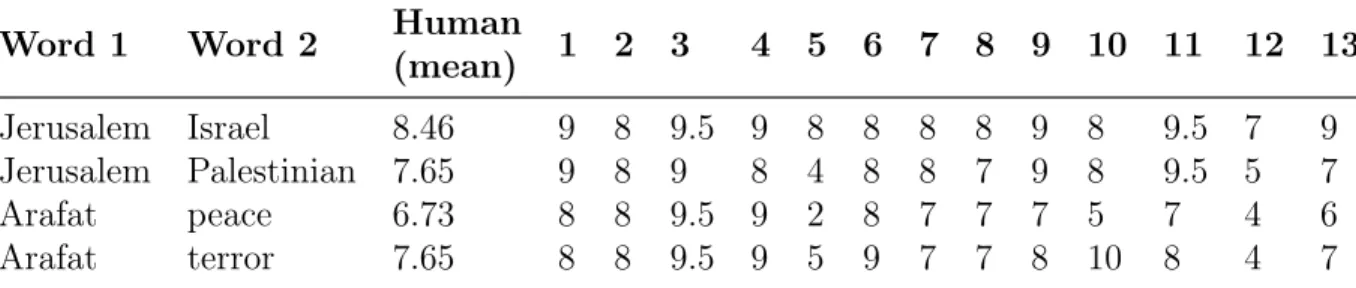
As seen in Table 2.1, WordSim353 word similarity judgments reveal political lin-guistic bias. This table contains 4 rows selected from the raw survey data collected by Finkelstein et al. [12]. Human-assigned scores are out of 10, with 10 indicating max-imum similarity. The similarity values used in evaluation are the averaged responses of 13 human respondents. Observe that the unaggregated responses: one subset of
Word 1 Word 2 Human (mean) 1 2 3 4 5 6 7 8 9 10 11 12 13 Jerusalem Israel 8.46 9 8 9.5 9 8 8 8 8 9 8 9.5 7 9 Jerusalem Palestinian 7.65 9 8 9 8 4 8 8 7 9 8 9.5 5 7 Arafat peace 6.73 8 8 9.5 9 2 8 7 7 7 5 7 4 6 Arafat terror 7.65 8 8 9.5 9 5 9 7 7 8 10 8 4 7
Table 2.1: WordSim353 Word Similarity Judgments
respondents find Jerusalem equidistant to Israel and Palestinian, while an-other subset finds Jerusalem more closely related to Israel. The demographics of the survey respondents is unknown, but it appears likely that had they been more diverse, there would have been a third subset of respondents who find Jerusalem more closely related to Palestinian.
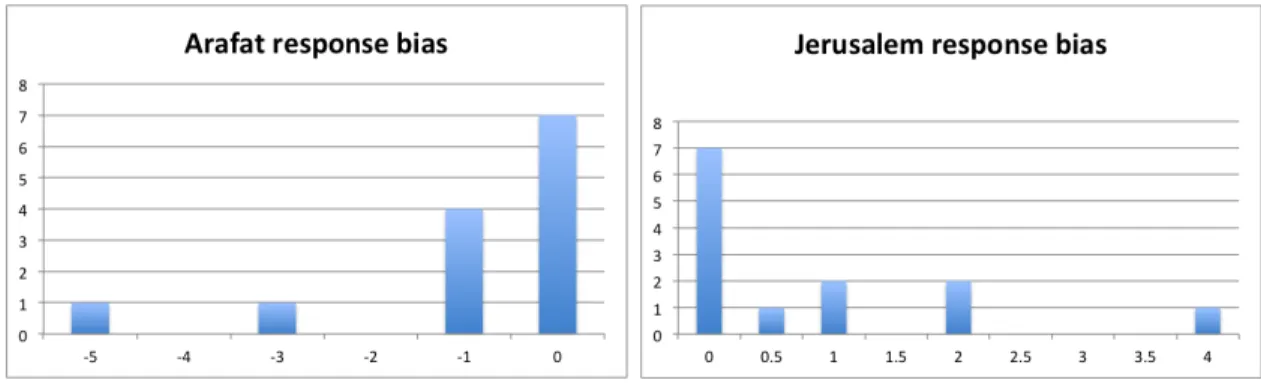
We plot two histograms, in Figure 2-3, to visualize the distributions of respondents’ political bias in the WordSim353 responses. The first histogram plots
𝑠𝑖𝑚𝑖(Arafat, Peace) − 𝑠𝑖𝑚𝑖(Arafat, Terror).
The second histogram plots
𝑠𝑖𝑚𝑖(Jerusalem, Israel) − 𝑠𝑖𝑚𝑖(Jerusalem, Palestinian).
Here, 𝑠𝑖𝑚𝑖(𝑤𝑗, 𝑤𝑘) denotes the similarity judgment (out of 10) provided by
Respon-dent 𝑖 about words 𝑤𝑗 and 𝑤𝑘.
Averaging human-assigned scores obscures the underlying distribution when mul-tiple linguistic lenses are at play.3 Note that the words we’ve highlighted above are
not typically considered to be polysemous - a term referring to words that have mul-tiple senses. However, as Figure 2-3 reveals, their response distributions may still be multimodal. In such cases, we suggest that it should be the ethical responsibility of dataset creators to select and defend the lens(es) they wish to amplify, or to publish multiple acceptable similarity scores corresponding to the distinct linguistic lenses
Figure 2-3: WS-353 Respondent Bias
The first histogram (left) plots 𝑠𝑖𝑚𝑖(Arafat, Peace) − 𝑠𝑖𝑚𝑖(Arafat, Terror).
The second histogram (right) plots
𝑠𝑖𝑚𝑖(Jerusalem, Israel) − 𝑠𝑖𝑚𝑖(Jerusalem, Palestinian).
evidenced by the sample.
Given that the evaluation data for language modeling tasks is imbued with political bias, it should come as no surprise that many language models that are considered “good” or “state of the art” will share that political bias.
The “best” language models are - by definition - partisan and sexist.
This is the case for the popular Word2Vec 200d embeddings trained on the Google News corpus4. In Figure 2-4, we show that the word vector for Jerusalem is sig-nificantly closer to Israel than it is to Palestine. We do not claim that this single example is sufficient evidence of political bias across the thousands of words represented in the Word2Vec Google News embeddings, although we note that the presence of linguistic stereotypes in these embeddings is well attested5 6. We merely remark that when evaluated against WordSim353, this particular instance of learned bias would have been rewarded, and the increased score on such evaluation metrics would have meant that these particular embeddings were more likely to be published, and subsequently reused in downstream tasks.
4The embeddings are available for visualization on https://projector.tensorflow.org, but the
Google News corpus itself has not been made public.
5Bolukbasi et al. [[5]] quantitatively measured the gender bias of Google News Word2Vec
embed-dings by asking Turkers to evaluate analogies suggested by the embedembed-dings. They concluded that “21% and 32% analogy judgments were stereotypical and nonsensical, respectively”.
6Garg et al. [13] actually use the gender and ethnic stereotypes captured by Google News word
vectors for social commentary. They correlate the bias measured in the embeddings with U.S Census data about shifting attitudes towards women and minorities over the 20th and 21st centuries in the United States.
Figure 2-4: Google News Word2Vec embeddings
The word vector for jerusalem is significantly closer to israel than it is to palestine.7
The bottom line: Linguistic lenses are implicit in text corpora, in extrinsic and intrin-sic evaluation methods. Their presence means that the case for lensing is a case for awareness and intentionality in machine learning, rather than a proposal to introduce additional complexity.
7
This visualization can be reproduced using the online TensorBoard at projector.tensorflow. org. The Google News Word2Vec vectors are pre-loaded by default.
Chapter 3
Linguistic Lenses - Collection
In this chapter, we’ll discuss how we chose our datasets to analyze. From here, we’ll describe the process of how to design a lens, based on the desired goals. Finally, we fully define 7GP, a gender-blind linguistic lens.
3.1
Similarity Lenses and Confusion Lenses
We experiment with representing human perspectives about language in two different classes of structured lens. The first class is a “similarity lens” and the second is a “confusion lens”.
Similarity Lens: An 𝑛 × 𝑛 matrix of human judged similarities between entities. It is symmetric and normalized such that 1 represents complete similarity and −1 represents complete dissimilarity. This format makes it directly comparable to a matrix of cosine similarities that one might compute to describe a set of 𝑛 embeddings learned by some embedding model.
Confusion Lens: An 𝑛 × 𝑛 matrix such that each row represents an entity 𝑖, and its columns represent the entities that a human might mistake 𝑖 for. Every value in the matrix is a probability, and each row adds up to 1, representing a probabil-ity distribution over the possible ways a human could confuse entprobabil-ity 𝑖. This format makes confusion lenses resemble the normalized confusion matrices often used to eval-uate machine learning classification models, and this is appropriate because confusion
lenses and classifiers’ normalized confusion matrices have the same semantics. One is the desired distribution of mistakes, according to a human informant, and one is the actual distribution of mistakes made by a classifier.
For example, let us imagine that we have only three classes, and we want to evaluate a classifier using an unbiased lens. That is, 𝐿 = 𝐼3, the identity matrix.
Then, let the classifier generate a confusion matrix 𝑆. Perplexity is minimized when 𝑆 = 𝐼3, and the classifier is penalized for any nonzero values off the main diagonal.
This is unbiased in that it rewards exact matches only.
Using 𝐼3as a lens (or a target confusion matrix), the following two model-generated
confusion matrices would achieve exactly the same perplexity:
𝑆1 = ⎡ ⎢ ⎢ ⎢ ⎣ 0.5 0.5 0 0.5 0.5 0 0 0 1 ⎤ ⎥ ⎥ ⎥ ⎦ 𝑆2 = ⎡ ⎢ ⎢ ⎢ ⎣ 1 0 0 0 0.5 0.5 0 0.5 0.5 ⎤ ⎥ ⎥ ⎥ ⎦
In other words, the model whose classifier confuses the first and second entities (𝑆1) is as bad as the model whose classifier confuses the second and third entities
(𝑆2). You could imagine a scenario where the first and second entities are similar,
and confusing them is judged to be not terrible by a human informant. In that scenario, it might be appropriate to evaluate using a biased lens like:
𝐿 = ⎡ ⎢ ⎢ ⎢ ⎣ 0.9 0.1 0 0.1 0.9 0 0 0 1 ⎤ ⎥ ⎥ ⎥ ⎦
When this lens is used in evaluation, the model producing 𝑆1 would achieve a
lower perplexity score than 𝑆2, matching the informant’s intuitions.
3.2
Corpus: The Gutenberg Story Dataset
We select the Gutenberg Story Dataset[23] for our experiments because it has the following desirable properties:
Popularity: The authors in this corpus have excellent name recognition. Their works are among the most famous and widely studied texts in English literature. This property of the corpus means that it will be easier to find knowledgeable informants who can provide perspectives on the subject matter. The authors in this dataset range from giants of the English literary tradition, like Jane Austen and Charles Dickens, to Irish playwrights like Oscar Wilde, to American novelists like Zane Grey to British politicians like William Gladstone and Benjamin Disraeli.
Availability: This corpus is available online1 as a free public dataset that any
researcher can use should they wish to replicate our results or perform further exper-iments.
Size: The Gutenberg Story dataset contains 3036 English texts written by 142 authors. The number of authors is sufficiently large, enabling meaningful evaluation of learned author embeddings. The number of texts is also many times larger than the number of authors; the authors are prolific enough that a statistical model may have enough data to learn reasonable author embeddings.
3.3
Lenses for Style
We were interested in capturing human perspectives on writing style as a structured lens. This was challenging because the very idea of a “hard” computational represen-tation for the “soft” and “fluid” notion of writing style seemed oxymoronic.
The exact reasons that we chose the Gutenberg data set (size and popularity) created some problems with finding good lenses. The Gutenberg data set contains a large number and an extensive variety of authors. This makes it quite tricky to find a domain “expert”, who can describe which authors are similar for all the authors in the set.
Thus, we tested a variety of proxies to make our judgments. In this section, we described our process in designing and constructing these lenses.
1
3.3.1
Goodreads Readership Lens
As a proxy for human intuitions about authorial similarity, we scrape Goodreads for collaborative filtering data. We construct a binary similarity lens as follows:
𝑙𝑒𝑛𝑠𝑖,𝑗 = 1 if Goodreads users who like author 𝑖 also like author 𝑗
𝑙𝑒𝑛𝑠𝑖,𝑗 = −1 otherwise
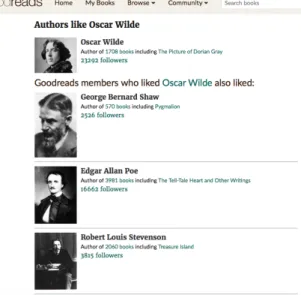
For instance, as seen in Figure 3-1, we can see that readers who liked Oscar Wilde tend to like Edgar Allan Poe. Thus, 𝑙𝑒𝑛𝑠Wilde, Poe = 1.
Figure 3-1: Goodreads “Similar Authors” page for Oscar Wilde2
The hypothesis behind this lens is that common readership is correlated with similar writing style. Having constructed the lens, we return to our informant with visualizations of the lens to test this hypothesis. There are lots of ways to visualize 1422 similarity judgments. We include two visualizations that worked for us - i.e. that
were interpretable by our informant and led to useful feedback. Both visualizations are graph-based, with vertices representing the lensed entities (the 142 authors of the Project Gutenberg corpus), and edges between nodes 𝑖 and 𝑗 when 𝑙𝑒𝑛𝑠𝑖,𝑗 = 1.
2
The first visualization, Figure 3-2, uses force-directed graph drawing. Eventually, these forces cause the authors to arrange themselves in a way that some interesting intuition about the structure of the authors in our dataset. We see that some authors are in extremely dense clusters, and others are far more isolated.
Figure 3-2: Goodreads Readership Lens Visualized as a force directed graph3
The force-directed graph visualization in Figure 3-2 suffers from one major draw-back. Dense clusters result in reduced legibility. To counter that, when we show this kind of visualization to our informant we show them a dynamic in-browser variant with the feature that clicking on a node isolates its neighbors.
The second interpretable visualization is surprising simple. The “circo” algorithm tries to place as many nodes as possible on the perimeter of a circle. The resulting visualization of the Goodreads Readership lens is shown in Figure 3-3, and (when scaled to a legible size), suffers from none of the density issues experienced in the previous visualization (force-directed graph drawing).
3Static visualization in Figure 3-2 created with GraphViz’ fdp algorithm. fdp draws undirected
graphs using a ”spring” model in the spirit of Fruchterman and Reingold (cf. Software-Practice & Experience 21(11), 1991, pp. 1129-1164).
Figure 3-3: Goodreads Readership Lens Circular visualization4
When presented with this circular format, an informant is able to simply zoom in on the perimeter and work their way around the circle without any problems. This visualization enables an efficient (linear time) and useful interpretive process. Figure 3-4 displays one arch of the circle.
Figure 3-4: Goodreads Readership Lens
Zoomed arch of circular visualization shows Lord Byron, P B Shelley, and Lord Tennyson in close proximity.
Unfortunately, when presented with visualizations of the Goodreads Readership Lens, our informant concluded that they could see why the edge-connected authors share readers on Goodreads, but that this lens does not do a good job of capturing any notion of linguistic or stylistic similarity between authors.
Our informant’s analysis meant that we did not use the Goodreads Readership Lens in any of our experiments. And yet, there are two reasons that describing it
here has been valuable. The primary reason is that one of the objectives of this thesis is to shine a light on the methodologies of lensing. The process of lens collection, visualization and criticism is essential to successful lensing. And the decision to reject the lens entirely emphasizes the point that you are not lensing if your lenses do not capture human perspectives. The other reason is that it was while criticizing this lens that our informant made the suggestion that lead us to collecting the Google Scholar Lens.
3.3.2
Google Scholar Lens
As a proxy for human intuitions about authorial similarity, we scrape Google Scholar for search term co-occurrence data. We construct an unnormalized similarity lens as follows:
𝑙𝑒𝑛𝑠𝑖,𝑖 = number of search results for: “author 𝑖”
𝑙𝑒𝑛𝑠𝑖,𝑗 = number of search results for: “author 𝑖” “author 𝑗′′.
Figure 3-5: “Oscar Wilde” and “Jane Austen” co-occur 6,460 times.
That is, we can search for authors like “Oscar Wilde” and “Jane Austen”. As seen in Figure 3-5, we can compute that 𝑙𝑒𝑛𝑠Wilde, Austen = 6, 460. However, this number
doesn’t mean too much, since Wilde and Austen are both famous authors. It’s hard to compare this to a pair of authors who are both much less famous.
To solve this problem, we normalize all the elements of our lens. The two tech-niques for normalization that we used were row normalization and Ochiai normaliza-tion.
Row Normalization:
𝑛𝑜𝑟𝑚𝑎𝑙𝑖𝑧𝑒𝑑_𝑙𝑒𝑛𝑠𝑖,𝑗 :=
𝑙𝑒𝑛𝑠𝑖,𝑗
∑︀
𝑗′𝑙𝑒𝑛𝑠𝑖,𝑗′
Row normalization divides each value by the sum of its row, thereby reducing the sum of each row to 1. This makes it possible to interpret each row 𝑖 as a distribution over the authors that might be mentioned alongside author 𝑖.
Ochiai Normalization: Another normalization technique is Ochiai normaliza-tion.
“Ochiai similarity of the co-occurrence matrix is equal to cosine similarity in the underlying occurrence matrix”[42]
Applying this idea gives us the following formula for normalizing a lens value:
𝑛𝑜𝑟𝑚𝑎𝑙𝑖𝑧𝑒𝑑_𝑙𝑒𝑛𝑠𝑖,𝑗 := 𝑙𝑒𝑛𝑠𝑖,𝑗 ∑︀ 𝑗′𝑙𝑒𝑛𝑠𝑖,𝑗′∑︀ 𝑖′𝑙𝑒𝑛𝑠𝑖′,𝑗 .
When we evaluate the cosine similarity matrix of the author embeddings learned by a model, the matrix can be meaningfully compared with the similarity lens, pro-vided that the similarity lens is Ochiai-normalized.
3.4
Lenses for Word Choice
We have argued that literature is full of implicit linguistic lenses. While some of those lenses are stylistic, others are related to the views held by author or reader. We now consider the problem of designing lenses that might enable a model to adopt particular perspectives on the issue of gender — or race or class, since the three have been connected in feminist literature for decades — as it learns from its training corpora.
It is tricky to construct good lenses, and for the most part we concern ourselves with building the methodology behind the process and defining frameworks for lensing language. We make no claim that the example lenses we create are authoritative or
complete, and we stress that as with every lens, the lenses below are but a few representations of some possible perspectives.
On the issue of lensing words in language, we begin by recognizing linguistic evolution. As human society has been shaped and reshaped over the centuries, so too have our words come to pick up new denotations and connotations.
Consider the word “mistress” as an example of the difficulty that arises from lin-guistic evolution. One feminist writer might suggest that when they write, they prefer the word “partner” to “mistress” or “lover”. But a lens that encourages a language model to learn to use “partner ” instead of “mistress” would have a different effect with Shakespeare than it would with more modern texts. For example, Desdemona is described as Emilia’s “mistress” in Othello, meaning her female master. Shakespeare also uses the word to mean lover, but it isn’t until the next century that the word comes to refer to a long-term illicit lover. Thus, we must understand that adding a lens to a model can have very different effects, based on the origin of the data, and the construction of the lens.
We’ll start by describing a small lens, which attempts to remove gender biases5. This lens, 7GP (7 Gender Pronouns) is described in Table 3.1. This lens asserts that the following pairs of pronouns are interchangeable: he/she, him/her, her/his, himself/herself.
Recall that using no confusion lens is equivalent to using an identity matrix as a lens. The lenses we will experiment with are sparse in the sense that they have a small number of values that differ from the identity matrix. As seen in Table 3.1, 7GPℎ𝑒,𝑠ℎ𝑒 = 7GPℎ𝑒,ℎ𝑒 = 0.5. We can use this to train a model, which learns that
predicting a value of “she” instead of “he” isn’t a mistake at all, and thus attempts to remove gender biases.
We can also model 7GP as a confusion lens, as seen in Table 3.1.
5Note that this lens does not take into account all possible genders and does not reflect the
7GP he she him her his himself herself he .5 .5 0 0 0 0 0 she .5 .5 0 0 0 0 0 him 0 0 .5 .5 0 0 0 her 0 0 .25 .5 .25 0 0 his 0 0 0 .5 .5 0 0 himself 0 0 0 0 0 .5 .5 herself 0 0 0 0 0 .5 .5
Table 3.1: 7 Gender Pronouns: A Gender-blind Confusion Lens
We also construct 7RGP (7 Reversed Gender Pronouns), which goes a step fur-ther than 7GP and assigns all the probability mass to the flipped gender pronouns. 7RGP, in Table 3.2, is a more extreme version of 7GP, and we create it as a demon-stration of how the perspective in 7GP can be given more weight. When we use 7GP in our experiments, we will compare the results obtained with those produced with 7RGP and also with those produced by using no lens (or using an identity matrix).
7RGP he she him her his himself herself
he 0 1 0 0 0 0 0 she 1 0 0 0 0 0 0 him 0 0 0 1 0 0 0 her 0 0 .5 0 .5 0 0 his 0 0 0 1 0 0 0 himself 0 0 0 0 0 0 1 herself 0 0 0 0 0 1 0
3.5
Asymmetric Confusion Lenses
On the surface, confusion and similarity matrices seem very similar. But, the ex-pressiveness of a confusion lens lies in its potential for asymmetry. Each value in the confusion lens has the following semantics — and note that 𝐶𝑖,𝑗 ̸≡ 𝐶𝑗,𝑖 :
𝐶𝑖,𝑗 := acceptability of confusing entity i for entity j — predicting entity
j in place of entity i.
A value of 0 means this confusion is unacceptable and should be discour-aged. A value of 1 indicates that 𝑗 is the only desirable prediction in place of 𝑖.
So an asymmetric confusion lens allows us to assert that, for example,
𝐶(“−′′, “,′′) > 𝐶(“,′′, “−′′).
In other words, that commas can often be used in place of dashes, but using a dash in a comma’s context is liable to land you in trouble.
On writing style and clarity, George Eliot had this to say:
The finest language is mostly made up of simple unimposing words. Mark Twain put it this way:
Don’t use a five-dollar word when a fifty-cent word will do. And Samuel Taylor Coleridge said:
Whatever is translatable in other and simpler words of the same language, without loss of sense or dignity, is bad.
To capture that perspective, we could construct an asymmetric word-confusion lens with the property that 𝐶𝑖,𝑗 > 𝐶𝑗,𝑖 when word 𝑗 is a more complex synonym for
a simpler word 𝑖. For example, when word j is “utilize” and word i is “use”.
It is easier still to construct a lens to captures the writing style perspectives of information theorists and of E. B. White, whose heuristic is simple:
Chapter 4
Comprehension Lensing for Language
Models
In this chapter, we develop a technique for applying lensing to language comprehen-sion. In Chapter 3, we had defined a writing style lens expressed as author similarity judgments. We will now apply this lens to word and author embedding models, and conclude that by using the lens to enforce desired distances between pairs of author embeddings, the model can extend the lens’ perspective to the distances between other pairs of author embeddings.
4.1
Lensing Embeddings
We describe a parameter lensing technique that can be used to apply similarity judg-ments to an embedding model. That technique is Embedding Similarity Lensing . Given 𝑘 learned embeddings, we can compute a similarity matrix, 𝑆, with dimen-sions 𝑘 x 𝑘 by computing the cosine similarity between every pair of embeddings. Let 𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑖𝑒𝑠 denote the function that performs this operation, converting an embed-dings matrix, 𝜃𝐸, to a cosine similarity matrix.
Let 𝑆 denote a 𝑘 × 𝑘 similarity matrix, and let 𝐿 denote an Ochiai-normalized similarity lens (also a 𝑘 × 𝑘 similarity matrix). Then, 𝑆𝑖,𝑗 denotes the model-reported
cosine similarity between entities 𝑖 and 𝑗, and 𝐿𝑖,𝑗 denotes the lens’ cosine similarity
score between entities 𝑖 and 𝑗.
One measure of model-lens disagreement is normalized L1 distance:
𝑑𝑖𝑠𝑎𝑔𝑟𝑒𝑒𝑚𝑒𝑛𝑡(𝑆, 𝐿) := 1 𝑘2
∑︁
𝑖,𝑗
|𝑆𝑖,𝑗− 𝐿𝑖,𝑗|
Let 𝐽𝑢𝑛𝑙𝑒𝑛𝑠𝑒𝑑 denote the objective function of an un-lensed model. Let 𝜃 denote
the model’s parameters, and let 𝜃𝐸 denote a matrix of embeddings learned by the
model. Then, the objective function, 𝐽𝐿of a lensed model with lens 𝐿, can be defined
as follows:
𝐽𝐿:= 𝐽𝑢𝑛𝑙𝑒𝑛𝑠𝑒𝑑(𝜃) + 𝑑𝑖𝑠𝑎𝑔𝑟𝑒𝑒𝑚𝑒𝑛𝑡(𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑖𝑒𝑠(𝜃𝐸), 𝐿)
In practice, we also introduce a hyper-parameter, 𝜆, that controls the weight given to the lens:
𝐽𝐿:= 𝐽𝑢𝑛𝑙𝑒𝑛𝑠𝑒𝑑(𝜃) + 𝜆𝑑𝑖𝑠𝑎𝑔𝑟𝑒𝑒𝑚𝑒𝑛𝑡(𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑖𝑒𝑠(𝜃𝐸), 𝐿)
That is Embedding Similarity Lensing, or informally: similarity lensing.
4.2
Case Study: Paragraph Vector with Author
Em-bedding Similarity Lens
We demonstrate how similarity lenses can be used to apply human perspectives about authors to a model that learns author embeddings.
4.2.1
Un-lensed Author Embedding Models
We define an “author embedding” as a distributed representation of an author’s writ-ing style. We will define that at greater length when we talk about lwrit-inguistic lenswrit-ing,
for indeed the definition of writing style is almost irrelevant to the design of the un-lensed model.
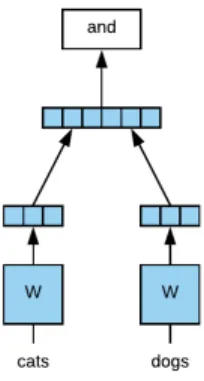
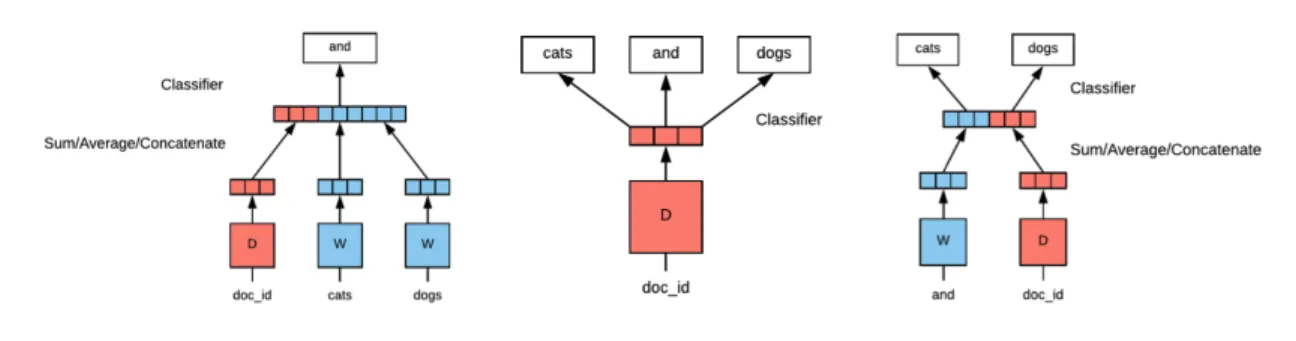
The first model we will use in our experiment is the Paragraph Vector model [25]. We treat each author’s collected work as a single “document” or “paragraph” and learn paragraph-vector embeddings for the authors, while simultaneously learning word embeddings. We will refer to this model as PV-Authors (No Docs), and abbreviate it PV-A.
The second model is a generalization of Paragraph Vector. Where Paragraph Vector learns distributed representations of words and documents using a shallow neural network, our model differs only in that it learns distributed representations of words and documents and authors. We will refer to this model as PV-Authors (with Docs), and abbreviate it PV-AD.
Both models are shown in Figure 4-1.
Figure 4-1: Author Embedding Models
left: PV-Authors (with Docs). right: PV-Authors (No Docs).
Le and Mikolov [25] have shown both summation and concatenation to be effective vector combination methods for paragraph vector models, but summation treats the context as an unordered set of words, whereas concatenation preserves word order information. We trained models for both summation and concatenation, and decided between them with Configuration lensing. We make no claim that concatenation is
the “better” baseline. Rather, our literature informant looked at a visualization of the author embedding space for each model, and determined that summation results in a clustering of authors (approximately) by topic, while concatenation clustered them in a way that more closely agreed with our expert’s stylistic similarity judgments. For this reason, and not to optimize validation set performance, our models are configured to use concatenation.
Table 4.2.1 describes reasonable hyper-parameters, which we will use for our base-line un-lensed PV-A and PV-AD models.
Hyperparameter Value Description
–min-word-freq 120 Words that appear fewer than min-word-freq times in the corpus are replaced with UNK.
–vec-dim 150 Embeddings with vec-dim dimensions are
trained for words, documents, and authors.
–lr 1e-3 Learning Rate
–batch-size 256 Batch Size
–context-words 5 Number of context words before and after the target word. So, when context-words is 5, window size is 10. —num-noise-words 2 The number of noise words sampled from the noise
distribution for negative sampling. Table 4.1: PV-DM Un-Lensed Model Hyperparameters
4.2.2
Method
We select the Google Scholar search term co-occurrence lens described in Section 3.3.2 to lens each baseline model. The lens is normalized with Ochiai normalization so that it resembles a cosine similarity matrix.
Let 𝜃 represent the model parameters, and let 𝑥 represent it’s output. The un-lensed loss function is the Negative Sampling loss function, 𝑆𝐺𝑁 𝑆.
Then the lensed loss function is:
𝐽𝑙𝑒𝑛𝑠(𝜃, 𝑥) := 𝑆𝐺𝑁 𝑆(𝑥) + 𝜆 ||𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑖𝑒𝑠(𝜃𝐴) − 𝑙𝑒𝑛𝑠||1

![Figure 2-2: Speaker Word Production Variation by Location Source: [22]](https://thumb-eu.123doks.com/thumbv2/123doknet/14671403.556930/32.918.152.763.355.770/figure-speaker-word-production-variation-location-source.webp)