Who are our clients: consumer segmentation through explorative data mining
Texte intégral
Figure


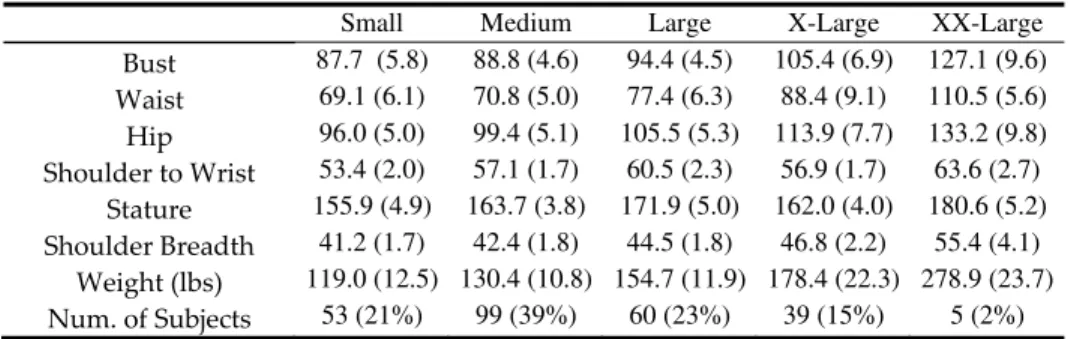
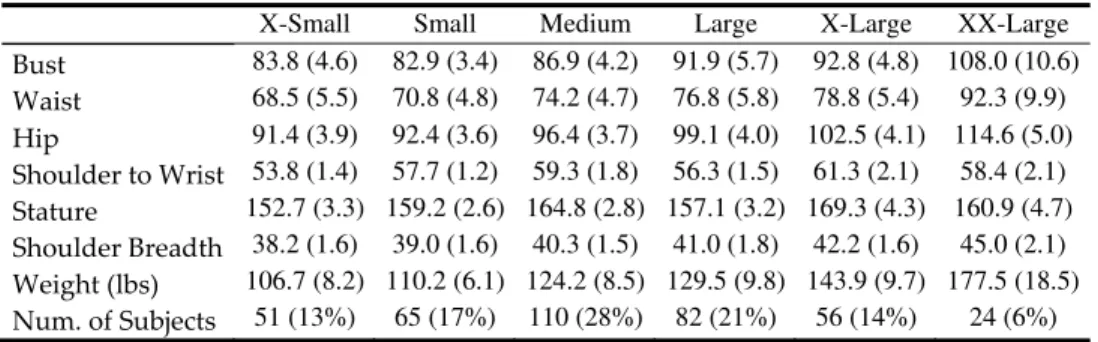
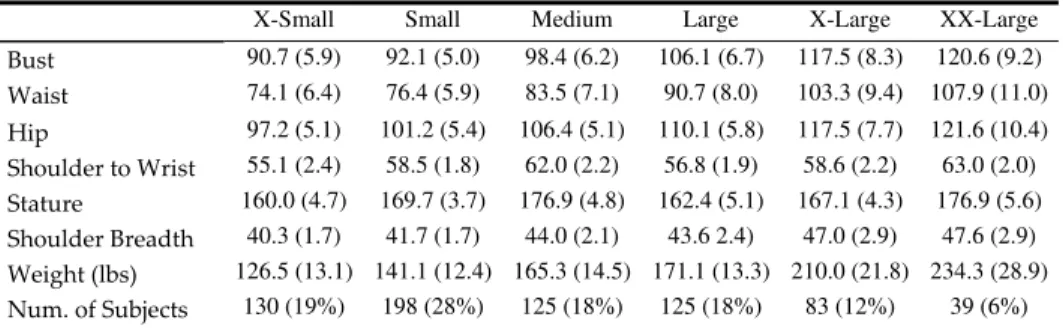
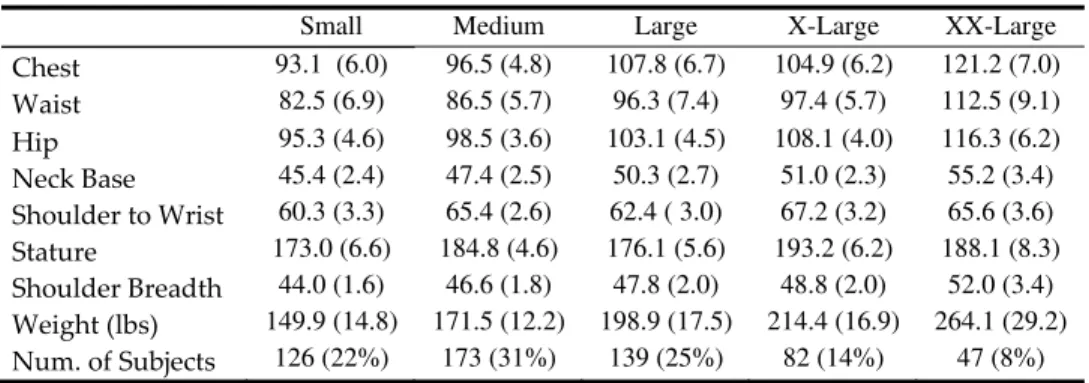
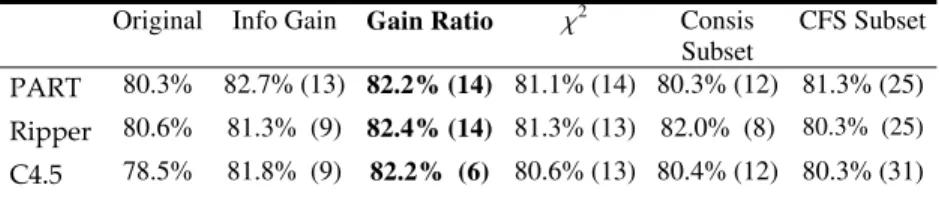
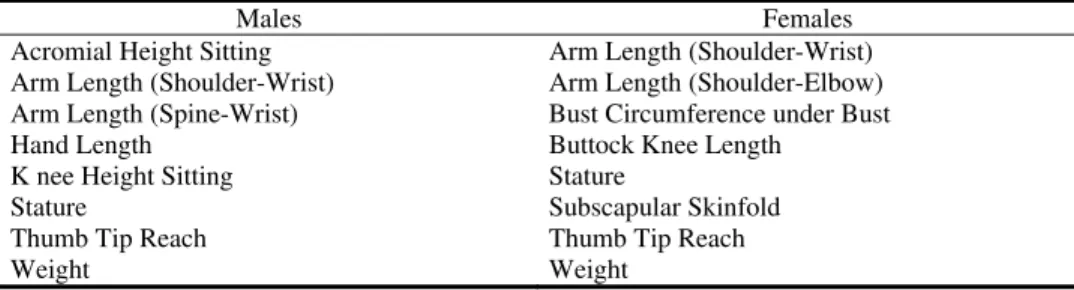

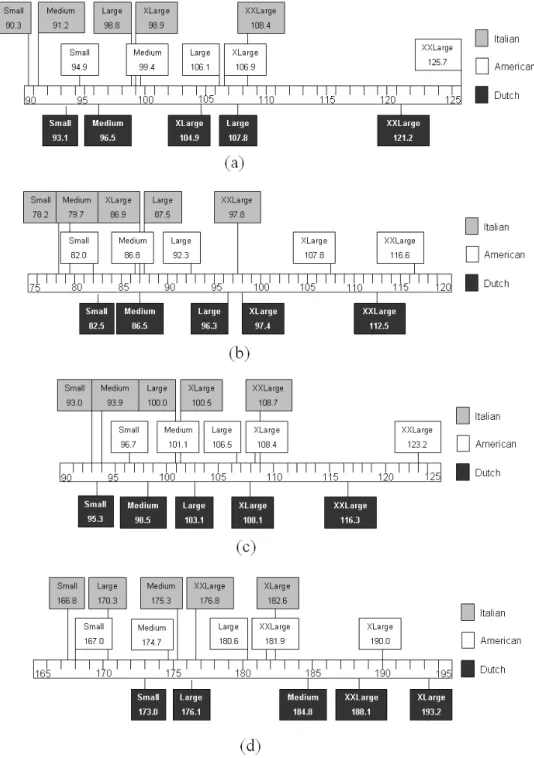
Documents relatifs
By comparing the answers of the randomly drawn citizens with those of the general population on identical questions, we assess the representativity of the CCC, study the evolution
Keywords: Prostitution, sexual tourism, Southeast Asia, local client, foreign customer.. Mots-clés : Prostitution, tourisme sexuel, Asie du Sud-Est, client local,
Thus, the contributions of this paper are twofold: (i) An experimental analysis of the amount of data necessary to successfully achieve supervised learning, and moreover, of
The New Zealand Immigration and Protection Tribunal made a point of saying that the effects of climate change were not the reason for granting residency to the family, but
Measurement: is the process of judging the extent of the learners' abilities to use English. Passive members: are the learners who are to
[39] N. Masmoudi: Ekman layers of rotating fluids: the case of general initial data. Nishida: The initial value problem for the equations of motion of viscous and
We prove that there is a unique solution if the prescribed curve is non-characteristic, and for characteristic initial curves (asymptotic curves for pseudo- spherical surfaces and
• With the ESD on the restricted set of computational cells where the initial data are positive, the relative entropy is well defined and further used to prove that numerical
