AutoFE : efficient and robust automated feature engineering
Texte intégral
Figure

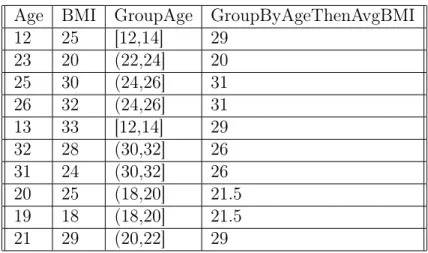
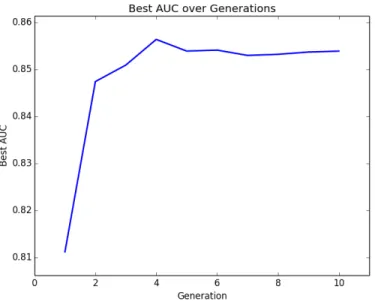
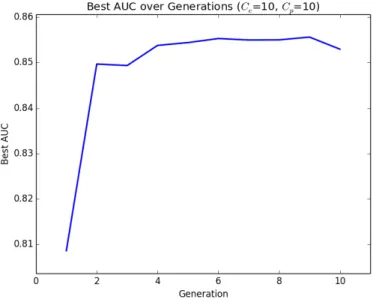
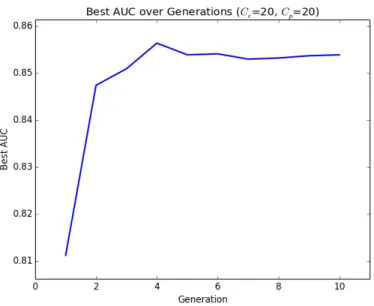
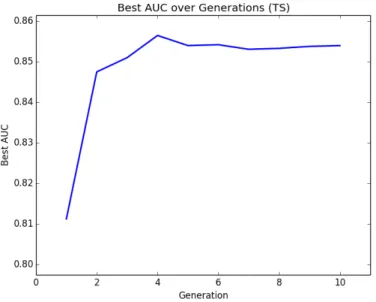
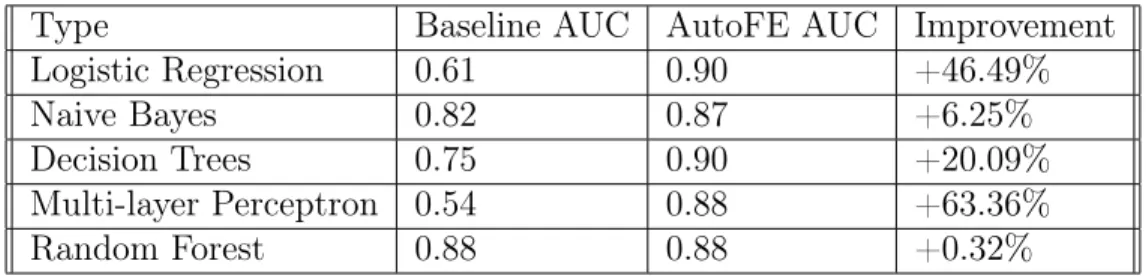
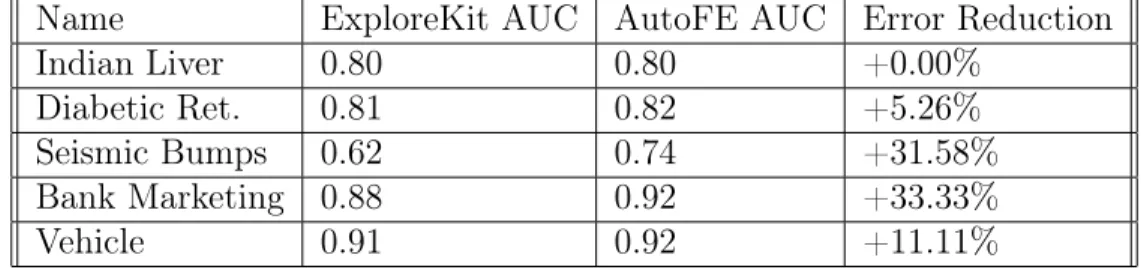

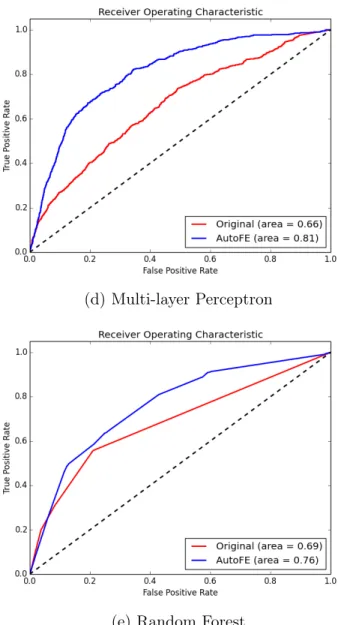
Documents relatifs
We stop at a scale relevant to the phenomena that we want, or that we can, study, and make a provisional sharing, between what does not move too much, we build
En utilisant une structure de données hiérarchique, un KD-Tree, pour faire une partition des sous-volumes non-vides des données volumiques initiales (en fait une hiérarchie de
Conventional Machine Learning based on Feature Engineering for Detecting Pneumonia from Chest X-raysF. F Ebiele, T Ansah-Narh, S
In this paper we design models to account for the decrease in calcification and photosynthesis rates observed after an increase of pCO2 in Emiliania huxleyi chemostat cultures..
Abstract. Traditionally, requirements engineering has been stakeholder driven. With the advent of digital technologies, unprecedented amounts of data are con- tinuously
For each user we perform the following steps: training a machine learning ranking model; use the trained model to rank all movies; and, finally, perform feature value analysis
Using our tooling support, a user can breath knowledge into the FM synthesis procedure in order to obtain an FM that is both accurate (w.r.t. the set of configurations),
In IBD, machine learning has been used to classify IBD paediatric patients using endoscopic and histological data 15 , to distinguish UC colonic samples from control and
