Generic Encodings of Constructor Rewriting Systems
Texte intégral
Figure
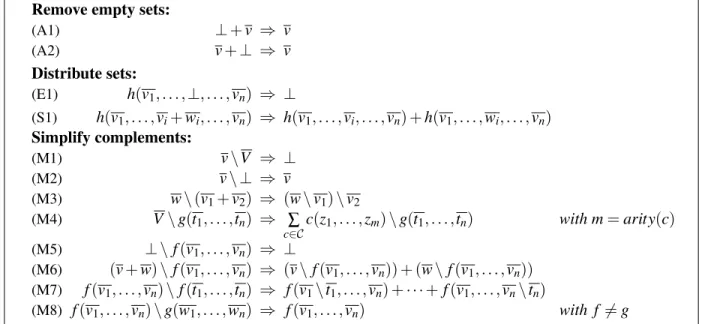


Documents relatifs
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
The letter was from a law firm in New York, and the attorney’s name was Thomas Campbell who was writing a letter on behalf of the artist Mary Ellen Carroll and it was
Detection rate: We showed that the detection of a real movement was easier than discrete and continuous motor imageries but we could discuss about the weakness of the
The Migrant Workers’ Project compliments our general advice service and aims to address the barriers that migrant workers experience in employment and when accessing services..
Time evolution of proteolysis index has been measured and modelled on five different types of pork muscle under different accurate temperature and water activity
NSP antibodies in cattle, pigs or sheep following administration of a double dose 20.. or a
In this regard, taking a look to neurophysiological measures, in particular to the W EEG index, it highlights an increase in the experienced cognitive workload if the
“negative” (and associated colouring) to the cables ; thus for a “negative beamline” set up for negatively charged particles, the “negative cable” is attached to the
