Advancing Biomedical Image Retrieval: Development and Analysis of a Test Collection
9
0
0
Texte intégral
Figure


+3
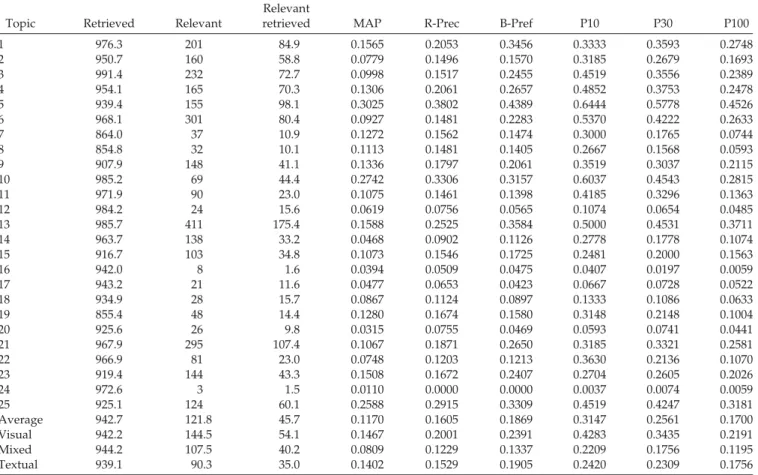
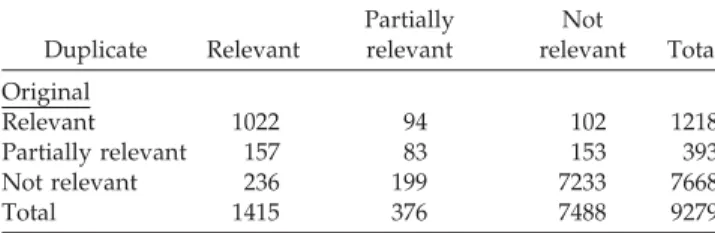
Documents relatifs