Real-Time Identification of Parallel Texts from Bilingual Newsfeed
Texte intégral
Figure
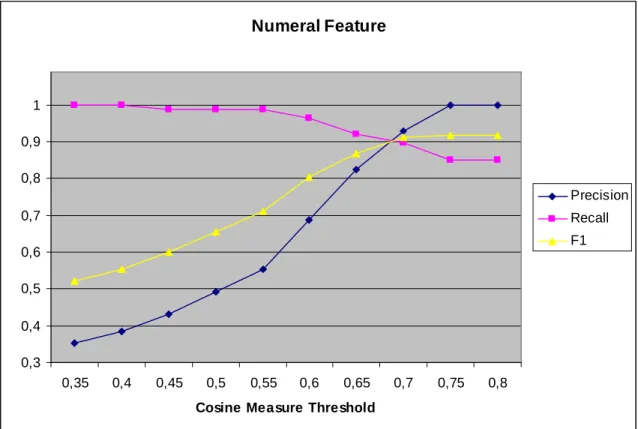
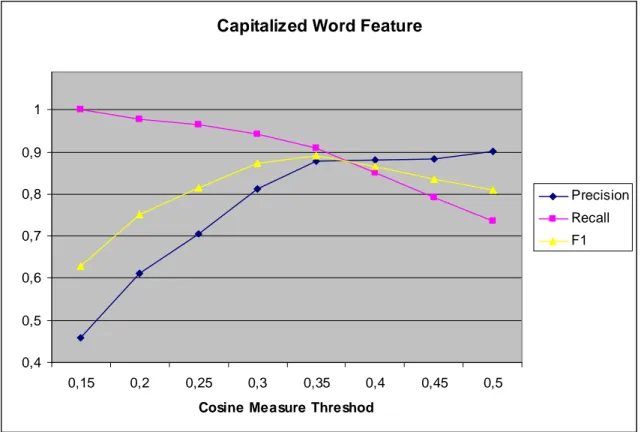
Documents relatifs
When symmetric cryptographic mechanisms are used in a protocol, the presumption is that automated key management is generally but not always needed.. If manual keying is
The purpose of this document is to make clear that whenever a PE address occurs in an MCAST-VPN route (whether in the NLRI or in an attribute), the IP address family of
Therefore, it is sufficient to consider texts of only two kinds: (type I) those that contain no titling statements, and (type II) those that contain only individual titling
Any 1-connected projective plane like manifold of dimension 4 is homeomor- phic to the complex projective plane by Freedman’s homeomorphism classification of simply connected
Prove that the gamma distribution is actually a continuous probability distributions that is it is non-negative over x > 0 and its integral over R + is equal to 1.. Exercise 8
the one developed in [2, 3, 1] uses R -filtrations to interpret the arithmetic volume function as the integral of certain level function on the geometric Okounkov body of the
(b) The previous question shows that it is enough to consider the case k, l 6 n/2, for otherwise we can replace the representations by isomorphic ones so that these inequalities
The forwat in this section uses a machine line heading with a listing of manuals for each operating system version and the appropriate product set members
