Asynchronous processing of Coq documents: from the kernel up to the user interface
Texte intégral
Figure


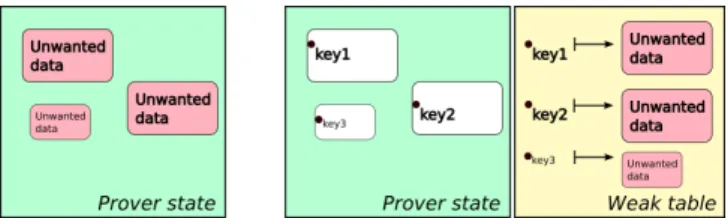
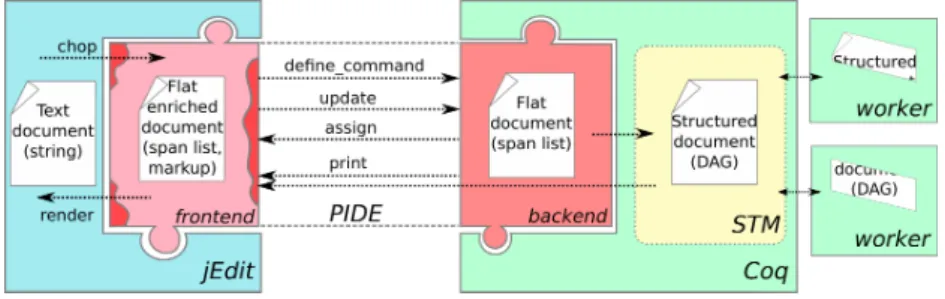
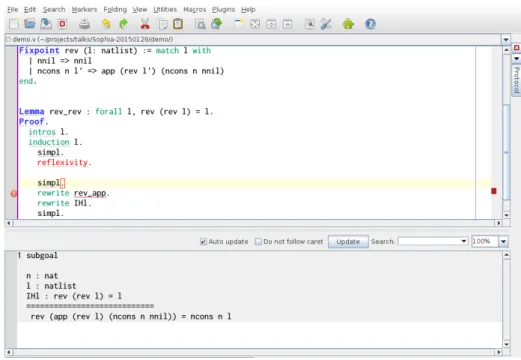

Documents relatifs
In an annotated inductive types, the universe where the inductive type is defined is no longer a simple sort, but what is called an arity, which is a type whose conclusion is a
[...] Where all, some or one of the manuscripts of the Kubjikāmata agree with the source text, that reading should be adopted as original, except where there may be independent
Notes: The All NPL sample is comprised of the 985 hazardous waste sites assigned to the NPL by January 1, 2000 that we placed in a census tract with nonmissing housing price data
observable differences in the latencies to begin a feeding session and no significant weight loss between the three genotypes.. This test suggests that the presence of the
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Lemma 151 ( complete normed vector space of continuous linear maps ), Theorem 180 ( orthogonal projection onto nonempty complete convex ), Lemma 193 ( sum of complete subspace
However, in addition to a “raw” translation from Alloy to Coq, we wanted our tool to provide some support to ease the proof in Coq of the assertions of an Alloy model.. Such a
In fact, the users’ preferences are mostly based on their observation and assessment of the intrinsic and extrinsic cues of a device, while the declared intentions to purchase
