Beyond brain reading: randomized sparsity and clustering to simultaneously predict and identify
Texte intégral
Figure
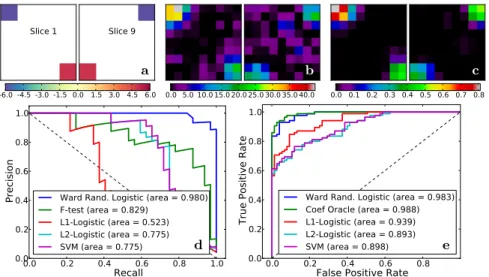
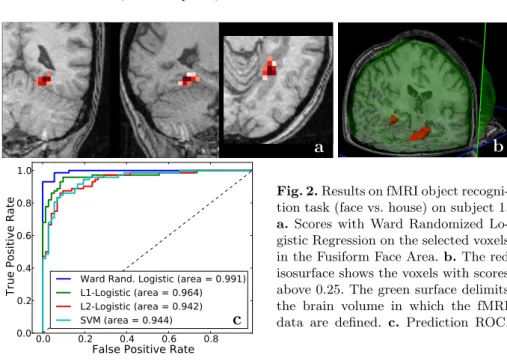
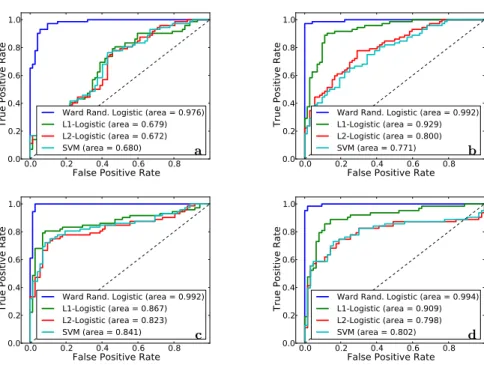
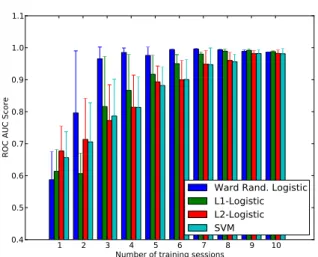
Documents relatifs
To do so, we first shortly review the sensory information used by place cells and then explain how this sensory information can lead to two coding modes, respectively based on
Based on this analysis, we propose a set of pedagogical design principles to guide the development of tools and activities that help learners build data literacy.. We outline
le périmètre du
Their original findings showed that specific executive functions (e.g., flexibility) were more sensitive to high intensity interval training as compared to regular endurance training
bution of citations across frequency bands roughly fol- low their corresponding power distribution in the rest- ing scalp EEG (see Figure 1), with 1,356 papers citing alpha or
x Each anchor node is composed of two sensors ( a bar containing two microphones), installed in such a manner that the bars of the different adjacent anchors are
Using her mind power to zoom in, Maria saw that the object was actually a tennis shoe, and a little more zooming revealed that the shoe was well worn and the laces were tucked under
