[PDF] Apprendre à créer des algorithmes pour programmer en Python | Formation informatique
Texte intégral
Figure
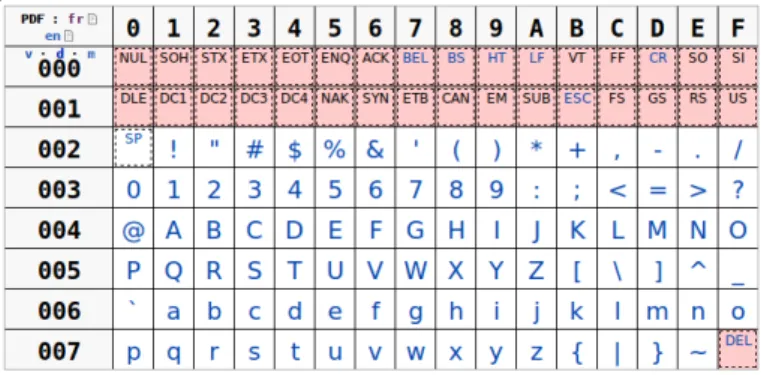

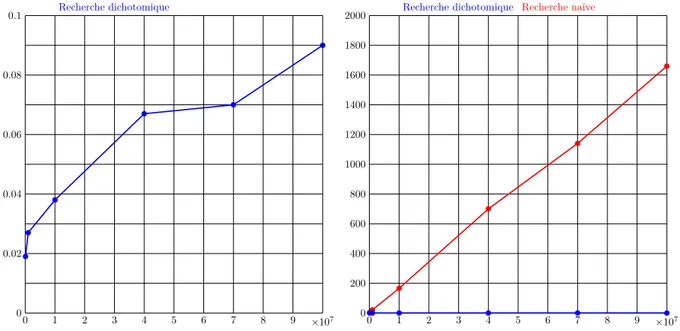

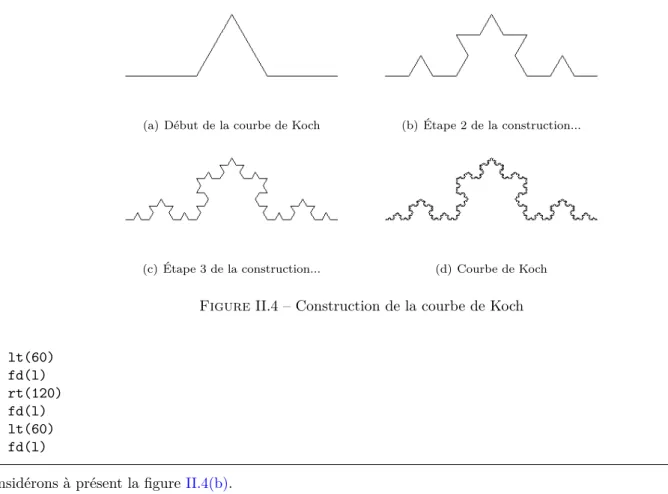


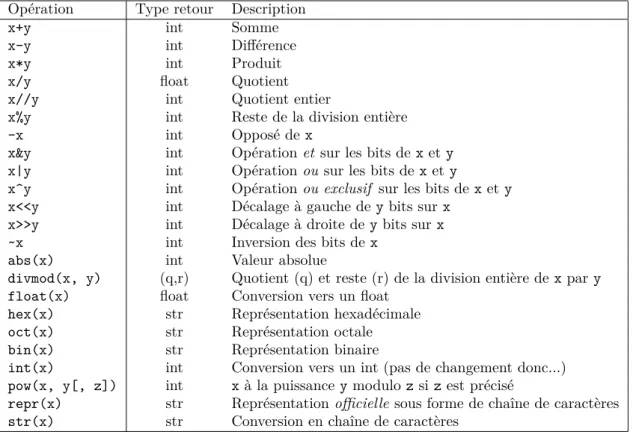


Documents relatifs
In this paper, we propose a framework for adaptive Hit or Miss Transform, where the HMT is defined for gray level images using the notion of adaptive structuring elements.. We present
Face à cela, certains préfèrent couper la vidéo, au risque de s’aliéner une partie du public, ou modifier son angle de manière à le resserrer sur leur seul visage,
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
We further propose a coding scheme for an extended setup with two sensors, two dedicated relays, and a single common final receiver, and analyze the type-II error exponents given
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Uma das demandas tecnológicas da espécie é a falta de definição de um padrão de bebida, o que tem levado a inverdades sobre o uso do café conilon, como a de que “o conilon tem
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
la caserne? Des objets circulent à l'intérieur des collecteurs et trahissent ceux qui pensaient les faire disparaître à tout jamais. Deux éléments cependant semblent
