Characteristics of human voice processing
Texte intégral
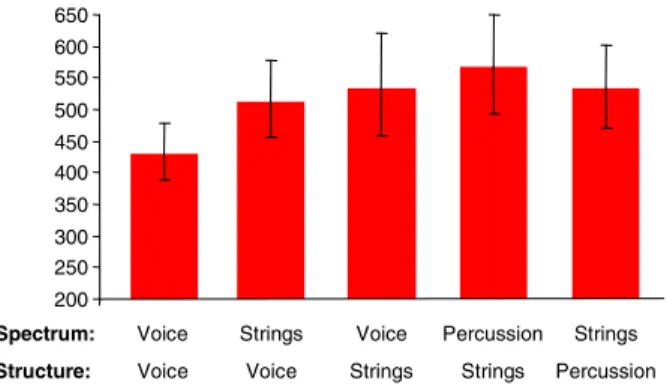
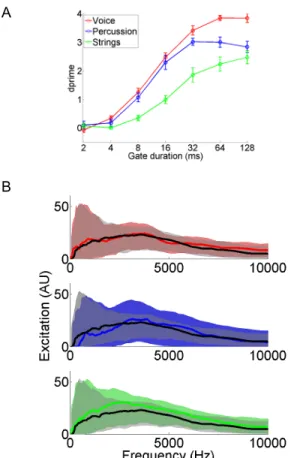
Figure

Documents relatifs
The passé composé consists of two parts, the present tense of an auxiliary, or helping verb (either avoir or être ), and a past participle.. In most instances the auxiliary verb used
Complete each sentence with the subject pronoun (je, tu, il, elle, on, nous, vous, ils, elles) and corresponding form of aller that you
Annex 4 List of members, observers and secretariat of the working group on Clinical Research Methodology for Acupuncture, Aomori, Japan,. 1-4 June 1994
This is an integrated initiative of four United Nations agencies (United Nations Children’s Fund, United Nations Educational, Scientific and Cultural Organization, United
WHO Regional Director of the Western Pacific Region working Group on Herbal Medicines, 8 December 1997..
Short-answer exercise Suggested field experience for assessment of practical skills.. Guidelines: senses and development of a plan of
Many nudges that are aimed at everyone, and motivated by community benefits, are very much in line with an idea of solidarity as an underlying principle of health care.. At the
the Ethical Grid is a device to help health professionals to make highly
