Multi-scale analysis of large distributed computing systems
Texte intégral
Figure
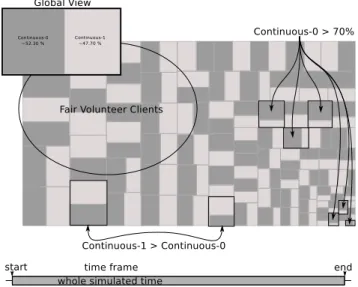
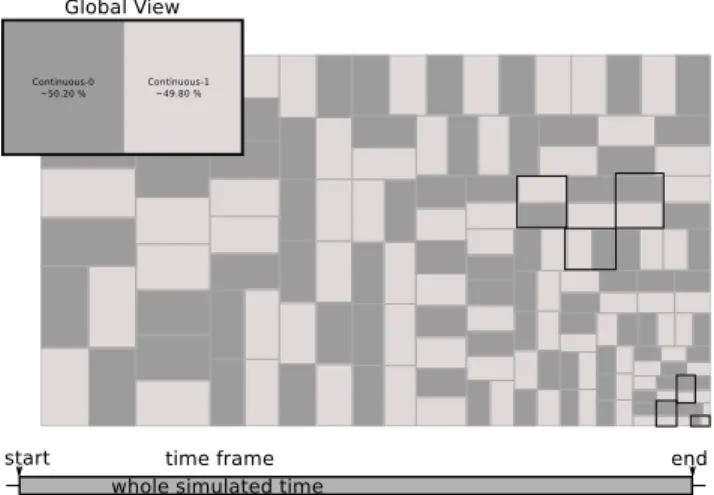


Documents relatifs
Dans le chapitre I, de par l’encadrement de thèse de Samar Kaddouri et du projet collaboratif MA-MIMO, nous avons évoqué l’utilisation des techniques MIMO pour
The performance of a Big Data architecture in the automotive industry relies on keeping up with the growing trend of connected vehicles and maintaining a high quality of service..
Giddy, Nimrod/G: an architecture for a resource management and scheduling system in a global computational grid, in: International Conference on High Performance Computing
3) Joint Communication and Computing Resources: Pro- viding SBSs with cloud-like computing capabilities can trans- form those SBSs from just radio access nodes into the so-
For this reason we perform molecular dynamic simulation using two different codes, LAMMPS, that allows us to perform massively parallels simulations and
The use of an umbrella distributed computing project on BOINC platform allows a high school student and a student to get knowledge in practice with the current technologies
In this paper, we propose several models of shutdown that can be used under actual and future supercomputer constraints, and that takes into account the impact of shutting down
Another grid experiment [7] based on Transmission-Line Matrix (TLM) Modeling code computes highly complex electromagnetic structures with a good scalability and an optimal
