Challenges in web corpus construction for low-resource languages in a post-BootCaT world
Texte intégral
Figure
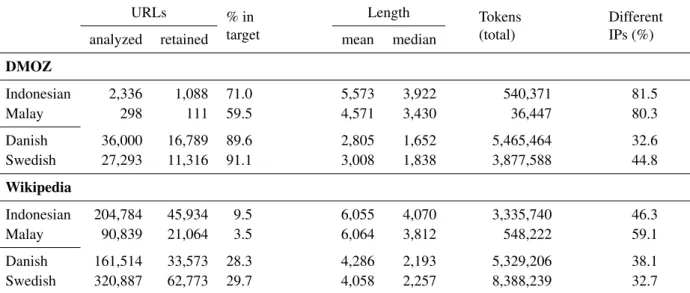

Documents relatifs
We then report on a formal experiment in which we tested the intelligibility of Danish and Swedish materials spoken by three representative male speakers per
platforms, the transfer of financial means is questionable: data given to a platform would have no use value for users, and little, if any, independent exchange value. Their
Continuing, developing and improving our learning visit programme is an important contribution by TNMoC to securing the future for ‘the past’ through the
Results showed that words were better reconstructed than pseudowords, evidencing a lexical benefit for words in degraded speech restoration.. We also observed an
Given the difficulty to determine the fundamental value of artworks, we apply a right-tailed unit root test with forward recursive regressions (SADF test) to
Although we have not explored all the cases (the transmission and coupling of a P and general S wave across a lam- ination with non-normal incidence), we are confident that for
Because the results showed the involvement of the ALK4/5 pathway in the crosstalk between microglia and neurons, the protein profiles throughout the microglia recruitment were
alors que les migrations forcées induisent une augmentation du risque de transmission de la tuberculose (tB), cette étude propose d’étudier les résultats d’un programme de suivi de
