Request Rewriting-Based Web Service Discovery
Texte intégral
Figure
Documents relatifs
All conjunctive queries over ontologies of depth 1 have polynomial-size nonrecursive datalog rewritings; tree- shaped queries have polynomial-size positive existential rewritings;
The main contributions of this paper are: (i) the introduction of the PrefDatalog+/– framework, the first (to our knowledge) combination of ontology languages with preferences as
This happens because, although the dynamic algorithm chooses a better ordering than the static algorithm, the intermediate results (that need to be checked in each iteration
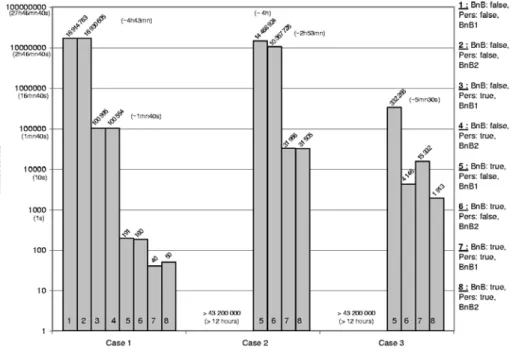
Alternate binders query (Fig. 3) has two optional graph patterns, both which may bind variable d. We call this the alternate binders case. The variable deref- erence expression
The task of data discovery and extraction is to discover new data sources those are unknown in advance for the query processing according to the data inference configuration.. The
Concepts are often defined through other concepts: a concept description for river may be identified using the term “River”, the river’s depth as “RiverDepth”, and one
We show that query answering can be distributed in a network of description logic reasoning systems in order to support scalable reasoning.. Our initial results
– Query optimization and evaluation techniques that focus on cost models to estimate the execution time of a plan, and on searching the space of plans of any shape, i.e., bushy
