Extraction de règles graduelles floues renforcées
Texte intégral
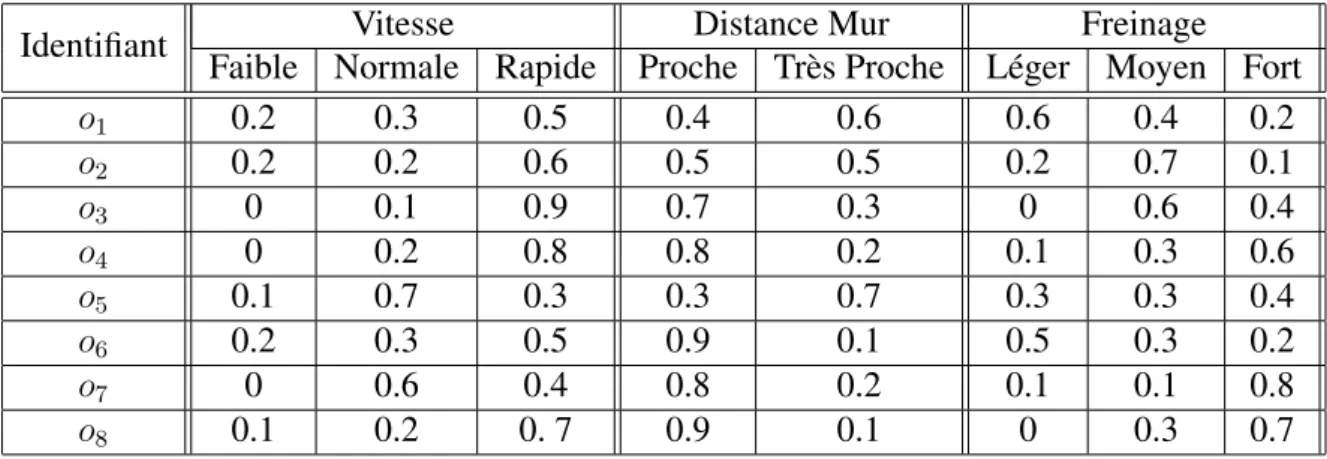
Figure
Documents relatifs
Dans cet article, nous avons comparé trois algorithmes pour caractériser les catégories de DBpédia : Eclat, Translator et ReReMi.. Translator atteint le meilleur rappel, mais les
Dans cet article nous nous sommes intéressés au traitement de l’information incertaine dans le cadre d’une extraction de connaissances à partir de texte.. Le traitement repose sur
Fouille de données biomédi- cales complexes : extraction de règles et de profils génétiques dans le cadre de l’étude du syndrome métabolique. Journées Ouvertes Biologie
Vous connaissez déjà les règles permettant de dériver une somme, et le produit d’une fonction par un réel.. Dans cette leçon, nous poursuivons l’étude de
Dans cet article, nous proposons d’utiliser l’outil de Visual Data Mining FromDady [7] pour rendre efficace l’exploration de l’ensemble des règles d’association extraites
Nous proposons, dans cet article, la description d’une mé- thodologie d’accès et de lecture des règles d’association extraites à partir de textes. Le corpus qui a servi à
Nous proposons, dans cet article, la description d’une méthodologie d’accès et de lecture des règles d’association extraites à partir de textes. Le corpus qui a servi à
— Après avoir rappelé le principe des méthodes de segmentation les plus courantes, nous présentons dans cet article les algorithmes utilisés pour réaliser un programme de
