Regularization schemes for transfer learning with convolutional networks
Texte intégral
Figure

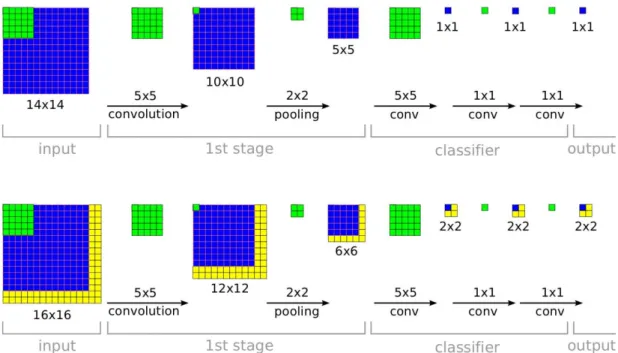
![Figure 2.6: Illustration of the pooling pyramid module proposed by Zhao et al. [2017].](https://thumb-eu.123doks.com/thumbv2/123doknet/14563963.726624/40.892.159.797.175.349/figure-illustration-pooling-pyramid-module-proposed-zhao-et.webp)


Documents relatifs
It addresses both theoretical and practical challenging issues related to the improvement of the training building blocks for both real and complex- valued deep neural
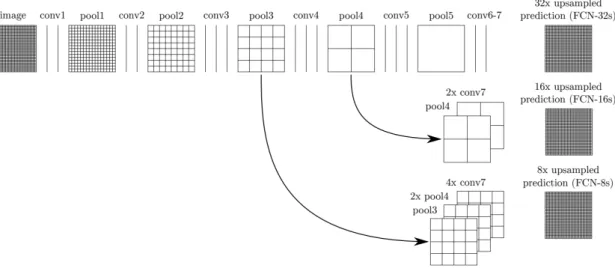
Efficient natural image segmentation can be achieved thanks to deep fully convolutional network (FCN) and transfer learning [1]. In this paper, we propose to rely on this same method
Bilmes, “Acoustic classification using semi-supervised deep neural networks and stochastic entropy- regularization over nearest-neighbor graphs,” in IEEE Interna- tional Conference
performance (10-layer residual-learning networks with the same filter numbers n = 64 and filter size f = 3 over 20 training epochs using Adam optimization and tested with
Our models are learned using the transfer learning trick by exploiting deep ar- chitectures that have been pre-trained on imageNet database, and therefore it requires very
Deep Learning for Metagenomic Data: using 2D Embeddings and Convolutional Neural Networks.. Nguyen Thanh Hai, Yann Chevaleyre, Edi Prifti, Nataliya Sokolovska,
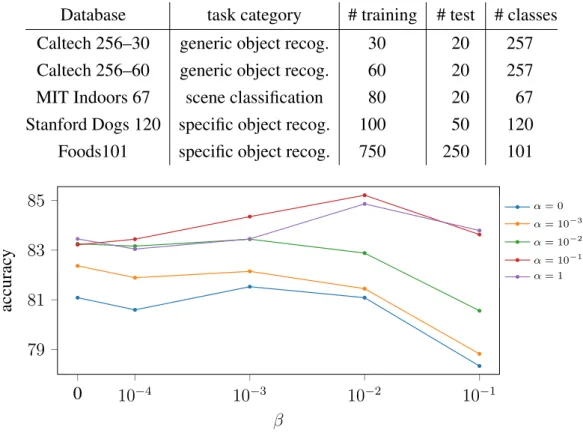
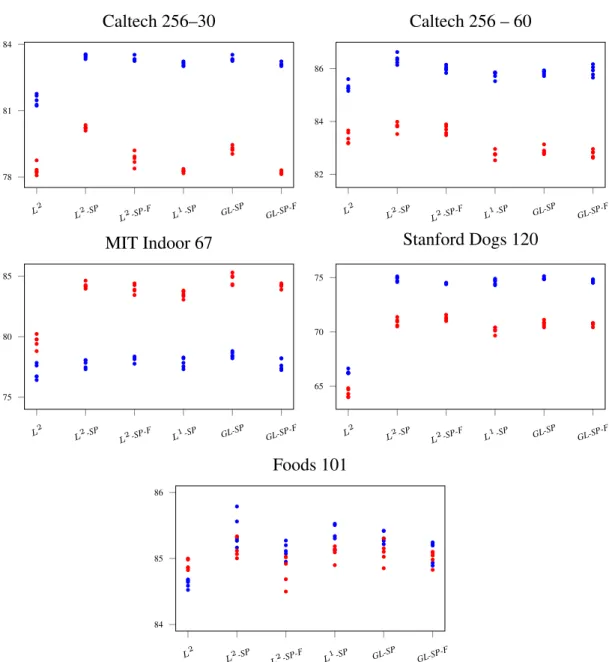
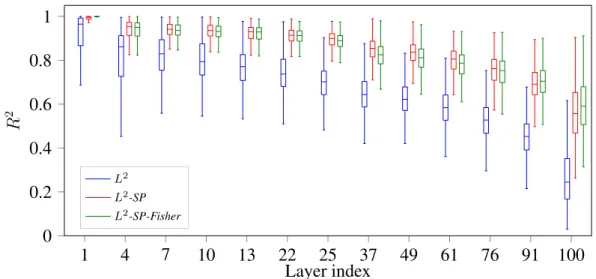
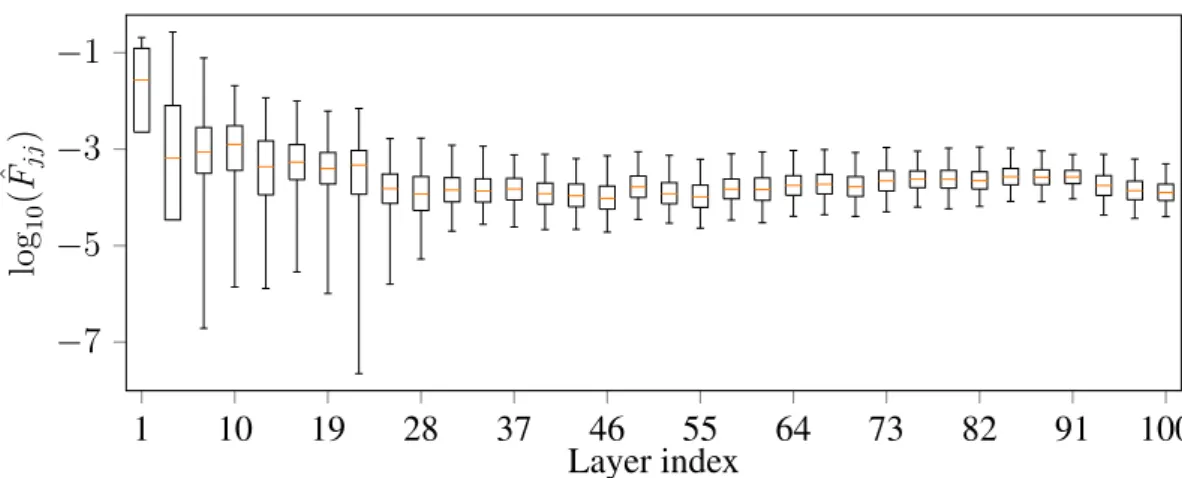
The L 2 parameter regularization, also known as weight decay, is com- monly used in machine learning and especially when training deep neural networks.. This simple
