Rouletabille at SemEval-2019 Task 4: Neural Network Baseline for Identification of Hyperpartisan Publishers
5
0
0
Texte intégral
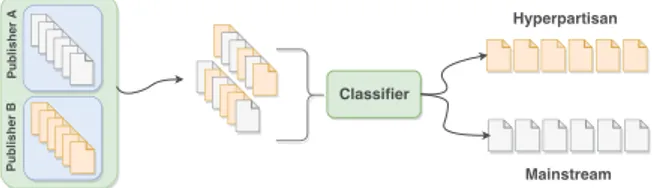
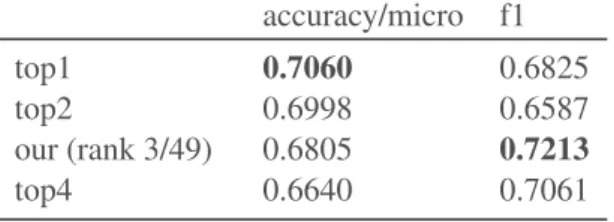
Figure
Documents relatifs
