Assessing steady-state, multivariate experimental data using Gaussian Processes: the GPExp open-source library
Texte intégral
Figure
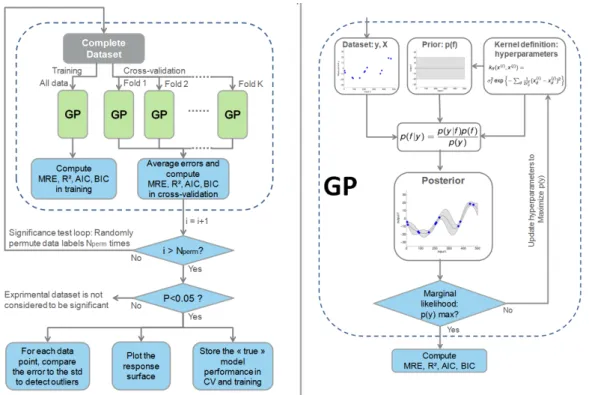
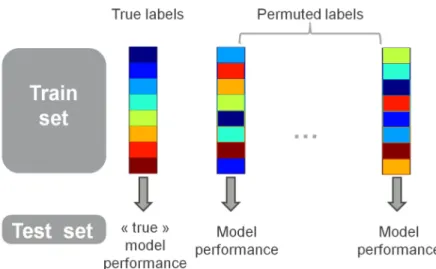
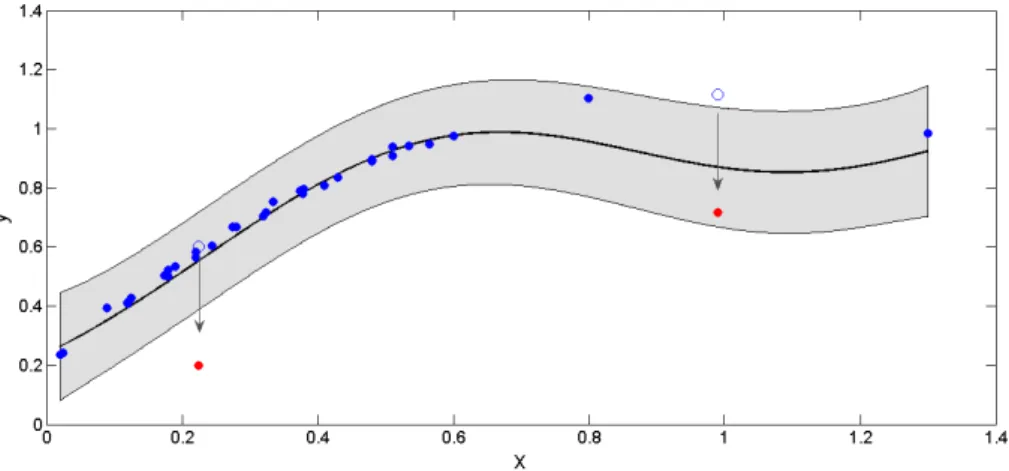
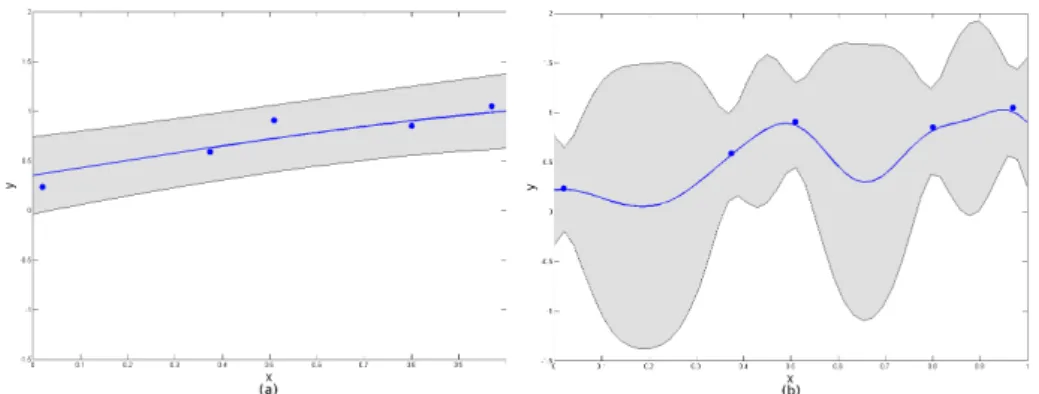

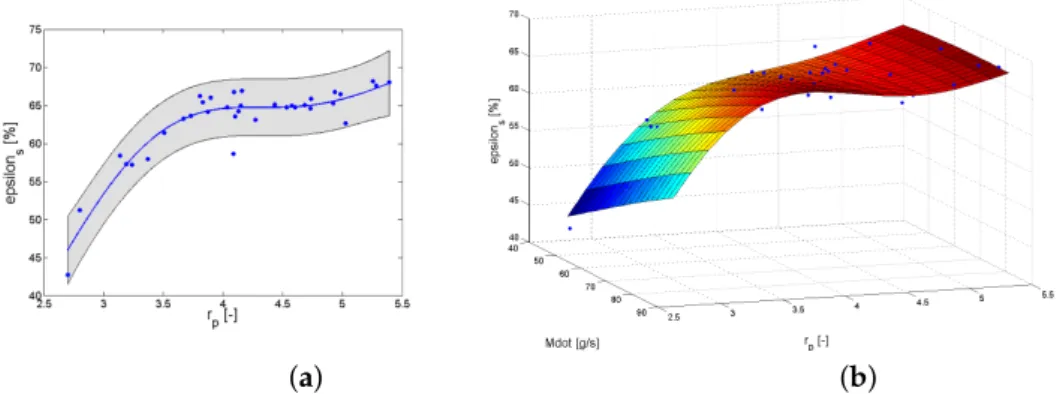
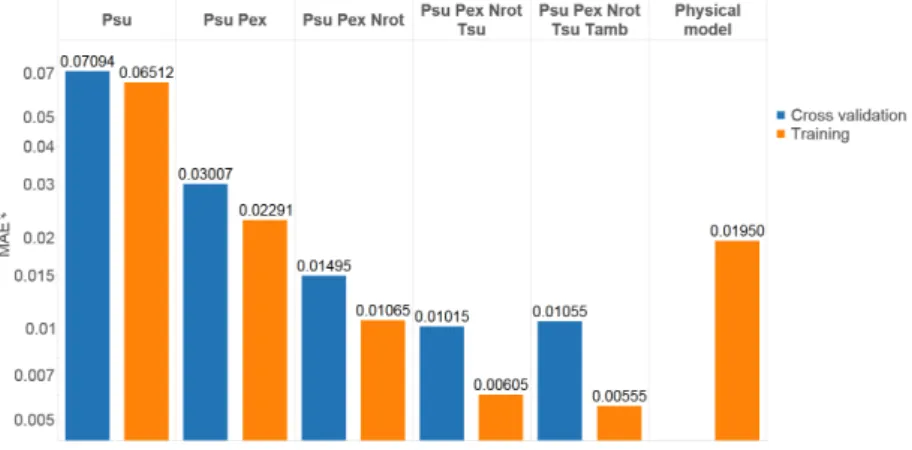
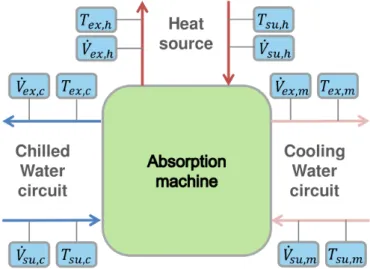
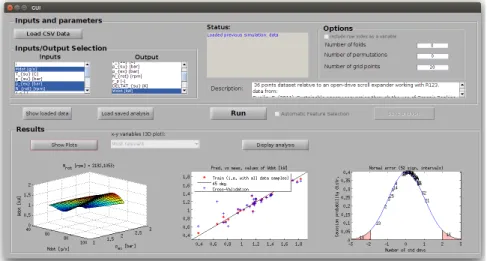
Documents relatifs
AMPA amplitude ratios (right) were statistically indistinguishable following either optogenetic (Optog., left bar; individual cells depicted as gray points) or extracellular
Among these, only 74 cases reported concomitant treatment with antipsychotics (aripiprazole, olanzapine, quetiapine, risperidone and/or ziprasidone) which are known to cause
The signals in this Newsletter are based on information derived from reports of suspected adverse drug reactions available in the WHO global database of individual case safety
The main contribution of this paper is the extension of the proportional-integral observer design procedure used in the linear theory to the nonlinear systems modelled by a
I It can be chosen such that the components with variance λ α greater than the mean variance (by variable) are kept. In normalized PCA, the mean variance is 1. This is the Kaiser
Now, let G be a connected graph consisting of two or more vertices, and let v be some vertex of G. For any simplicial graph G and any simplicial clique K 6 G, the line graph of
Finally, we demonstrate the potential of the present model by showing how it allows us to study a semi-Markov modulated infinite server queues where the customers (claims) arrival
Abstract. Processes need to be captured in a structured way in order to analyze them by using computer-assisted methods. This circumstance be- comes more important as the
