Exploiter des corpus annotés syntaxiquement pour observer le continuum entre arguments et circonstants
Texte intégral
Figure
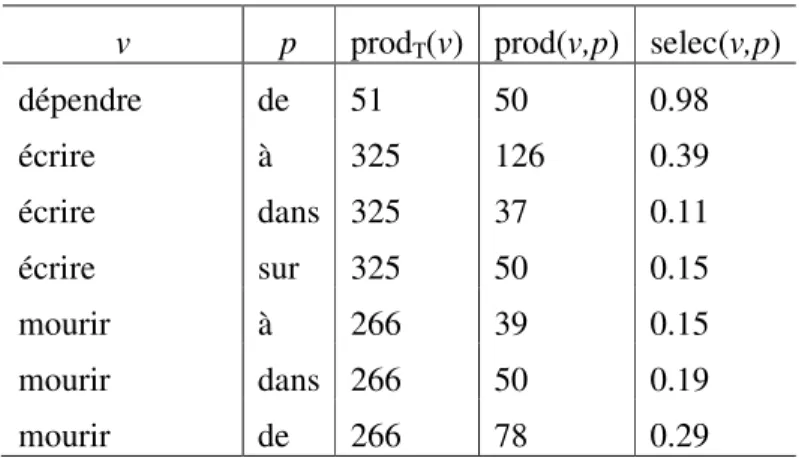



Documents relatifs
Ainsi qu'on l'a déjà exposé au cours de la présente session, la sécheresse est avant tout un phénomène climatique dont les auteurs de plusieurs conférences se sont attachés
En 1992, Suleyman Demirel, alors Premier ministre turc, évoque une théorie de souveraineté absolue sur la gestion de l’eau des deux fleuves, générant ainsi un précédent
Le cas de la France apparaît relativement singulier dans le paysage européen : le niveau des dépenses publiques de retraite est parmi les plus élevés du panel, alors que
Pays avec textes sur la protection des espèces et de la nature qui incluent des dispositions dédiées à certaines EEE
- Le complément d’objet direct (COD) est lié directement au verbe, sans
Le site Internet national de l’inspection des installations classées a été conçu dans l’optique de répondre aux interrogations que peuvent avoir les professionnels de
Le site Internet national de l’inspection des installations classées a été conçu dans l’optique de répondre aux interrogations que peuvent avoir les professionnels de
Or, il faut attendre le XVIIIe, avec Girard, pour que s’esquisse une véritable grammaire des fonctions (cf. Certes chez les grammairiens de Port-Royal et leurs disciples,
