Analyse de changements multiples : une approche probabiliste utilisant les réseaux bayésiens
Texte intégral
Figure
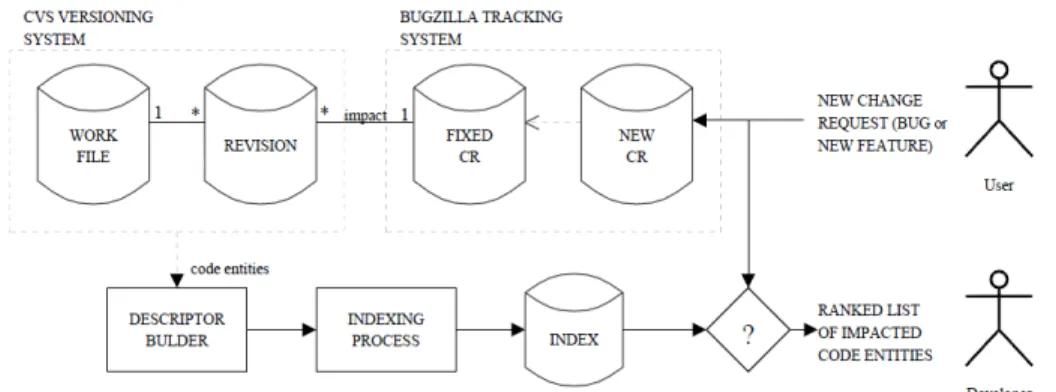


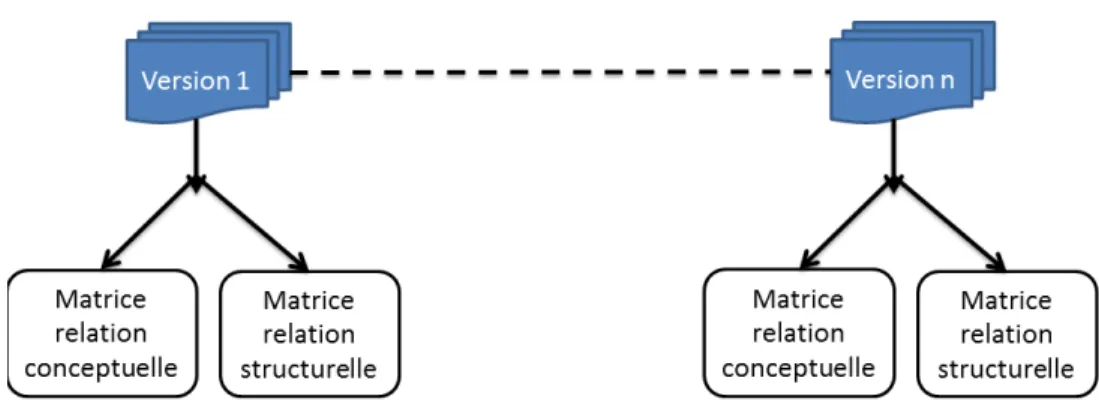

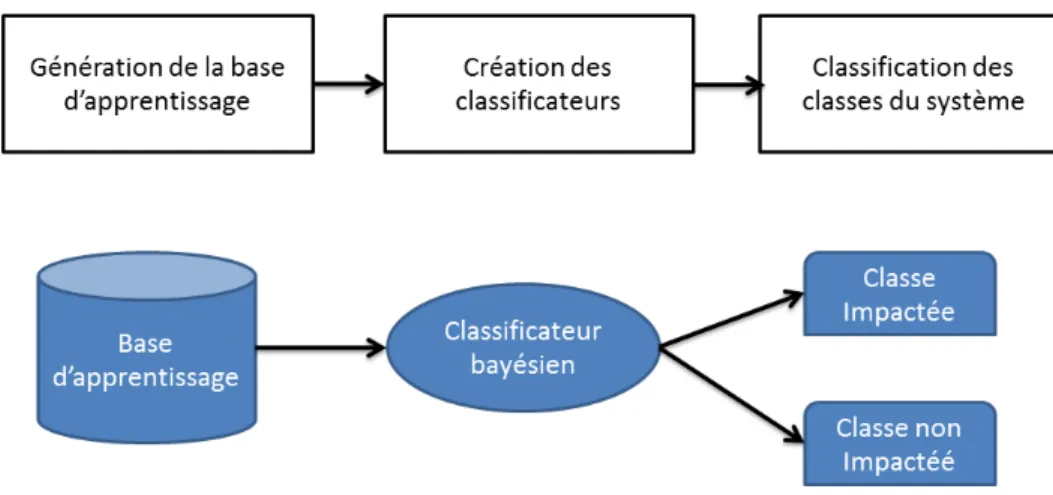


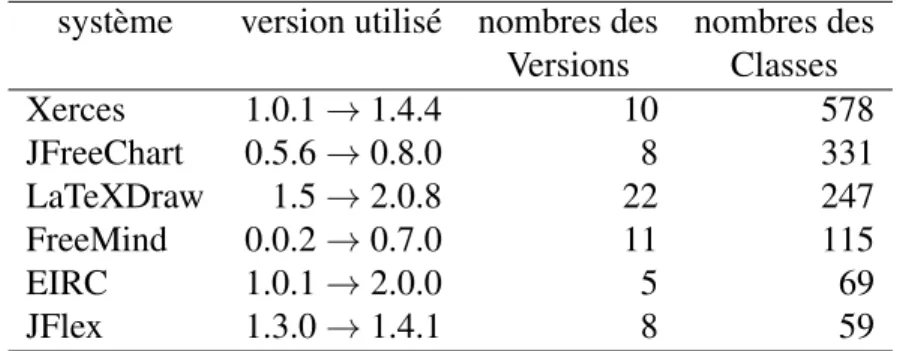
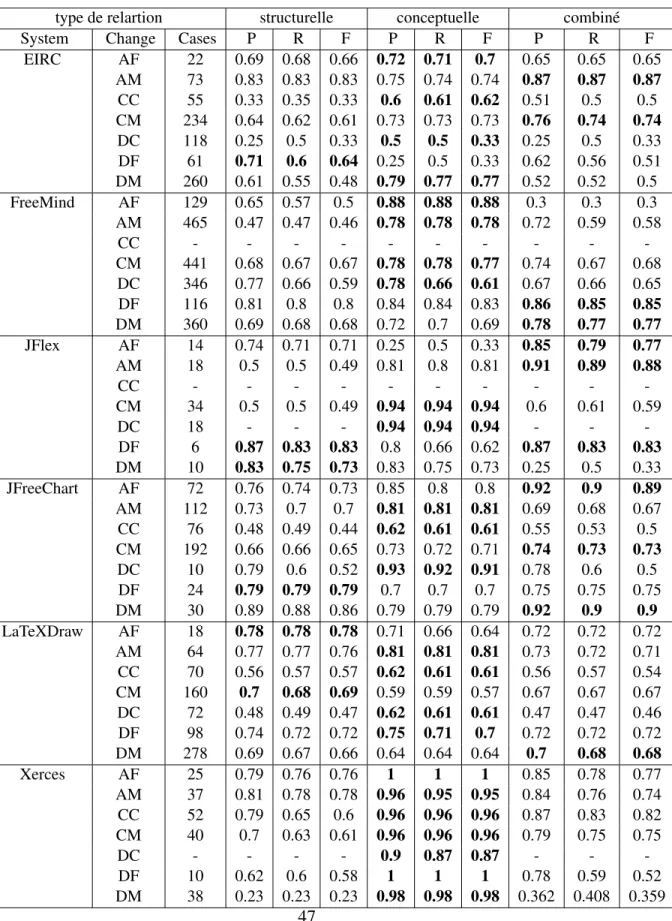
Documents relatifs
Selon les consultants, la construction commence à l’été 2006 avec l’acquisition des terrains, transfert des lignes de services publics (téléphonie, Câblodistribution, etc.)
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of
Fundoscopy revealed the optic discs to be widely normal, but horizontal retinal folds were observed in the papillomac- ular bundle of both eyes, with diffuse macular oedema,
Même si les enseignants de ce module avaient déjà familiarisé les étudiants aux QCU de l’activité Test de Moodle dans le cadre d’enseignements de mathématiques,
special codes h(x) of the words x, we prove here that ω-languages of non-deterministic Petri nets and effective analytic sets have the same topological complexity: the Borel and
En cette situation, Le passage d’une gestion classique du personnel à une gestion dynamique et stratégique des ressources humaines commande la réunion de certaines conditions, les
- After the operation final draining, there was still sodium remaining in the secondary loops in two physical forms : 1/ Sodium films.. The best estimate thickness is 1 mm
