Contributions aux méthodes de Monte Carlo et leur application au filtrage statistique
Texte intégral
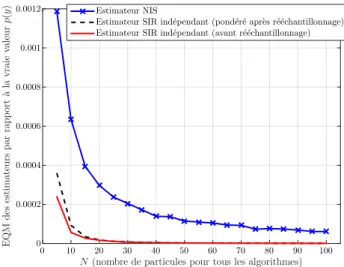
Figure



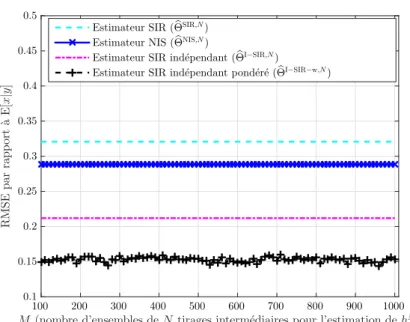
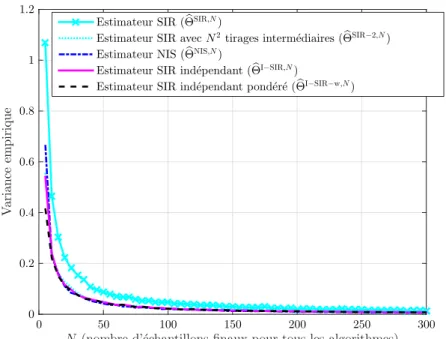
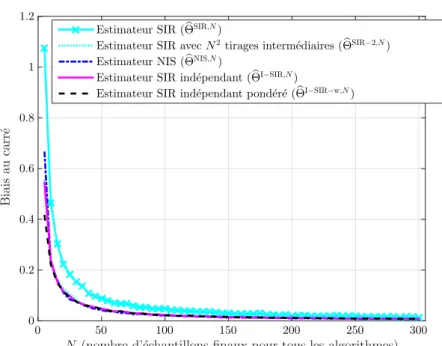
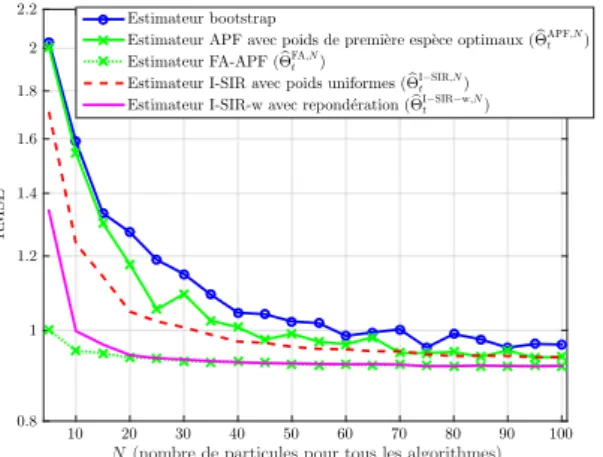
![Figure 3.3 – Modèle statique linéaire et gaussien - σ x 2 = 10, σ y 2 = 3 - les estimateurs bayésiens de E[x|y] basés sur le mécanisme de rééchantillonnage indépendant donnent de meilleures per-formances que ceux basés sur les mécanismes traditionnels NIS](https://thumb-eu.123doks.com/thumbv2/123doknet/11413680.288457/79.892.215.670.381.735/estimateurs-bayésiens-mécanisme-rééchantillonnage-indépendant-meilleures-mécanismes-traditionnels.webp)

Documents relatifs
On se rappelle que pour identier la loi d'une variable aléatoire, il sut de savoir calculer les espérances de fonctions de cette variables aléatoires (pour toute fonction dans
La m´ ethode de Monte-Carlo permet le calcul de valeurs approch´ ees d’int´ egrales multiples dont le calcul purement alg´ ebrique est impossible ou tr` es difficile.. Le fondement
Je propose que la probabilité de gain à la roulette soit notée pgain ; que le facteur de gain en cas de succès (càd. le ratio entre le montant récupéré et le montant misé) soit
En pratique , comme pour le mouvement brownien, on supposera que l’erreur de simulation est bien plus faible que l’erreur de Monte-Carlo, et on fera donc comme si la simulation
De même, la fonction arc-cosinus, notée arccos — qui s’obtient sous M ATLAB par la commande « acos » —, est la fonction de [−1, 1] dans [0, π] dé- finie comme la
Écrire une fonction publications qui ne prend aucun argument, simule le processus de soumission des propositions de romans, et renvoie une matrice de taille B × 2, où B est le
En pratique , comme pour le mouvement brownien, on supposera que l’erreur de simulation est bien plus faible que l’erreur de Monte-Carlo, et on fera donc comme si la simulation
Cela consiste à payer un montant C (convenu à l’avance entre vendeur et acheteur), pour qu’à une date fixée T (ici dans six mois), vous puissiez exercer votre droit d’acheter ou
