E T M O D É L I S A T I O N S Y S T È M E S P O U R L ’ A I D E L A D É C I S I O N U N I T É E C H E R C H E A S S O C I É E C N U 7 0 2 4 U N I V E R S I T É P A R I S D E À D E R S M R D A U P H I N E P L A C E D U Ma l D E L A T T R E D E T A S S I G N Y F - 7 5 7 7 5 P A R I S C E D E X 1 6 T É L É P H O N E ( 3 3 1 ) ( 0 1 ) 4 4 0 5 4 4 6 6 T É L É C O P I E ( 3 3 1 ) ( 0 1 ) 4 4 0 5 4 0 9 1 E - M A I L r o -c h e @ l a m s a d e . d a u p h i n e . f r W E B w w w . l a m s a d e . d a u p h i n e . f r
Entrepôt de données complexes pour le trafic routier
NOTE N° 39
O. Carles, G. Jomier, M. Manouvrier,
Y. Naïja, G. Scemama (1)
mars 2006
(1) CNRS- LAMSADE, Université Paris-Dauphine, Place du Maréchal De
Lat-tre de Tassigny, 75775 Paris Cedex 16.
routier
O.Carles
*, G.Jomier
**, M.Manouvrier
**, Y.Naïja
**, G.Scemama
**INRETS - Laboratoire GRETIA
2, Avenue du Général Malleret Joinville 94114 Arcueil Cedex
{carles, scemama}@inrets.fr
**Université Paris Dauphine - Laboratoire LAMSADE
Place du Maréchal de Lattre de Tassigny 75775 Paris Cedex 16
{naija, manouvrier, jomier}@lamsade.dauphine.fr
RÉSUMÉ.Après avoir présenté les données spatio-temporelles utilisées dans le domaine du tra-fic routier et les fonctionnalités des applications de ce domaine, les auteurs montrent comment le stockage des données dans un entrepôt de données spatiales ouvre de nouvelles perspec-tives pour l’amélioration du trafic. Ils présentent les premiers travaux sur la structuration de l’entrepôt. Ce travail est réalisé dans le cadre du projet CADDY de l’ ACI (Action Concertée Incitative) "Masse de Données".
ABSTRACT.This paper firstly presents spatio-temporal data and road traffic application function-alities. Then, the authors show how the storage of these data in a spatial datawarehouse offers new opportunities for these applications. Eventually, the first elements of the spatial dataware-house design are described. This work takes place in the CADDY project.
MOTS-CLÉS :Modélisation du trafic routier, séquences spatio-temporelles, entrepôts de données spatiales
1. Introduction
Les exploitants de réseaux de transport ont besoin d’outils d’observation du trafic pour améliorer le fonctionnement de leur réseau. Les recherches de l’INRETS (Ins-titut National de REcherche sur les Transports et leur Sécurité) ont conduit à l’éla-boration de tels outils [SCE 94, SCE 00, SCE 04]. D’une manière générale, ces ou-tils produisent des rapports périodiques, mensuels ou annuels, traduisant des états du trafic. La masse des données relatives au trafic et la diversité de leurs sources sont des obstacles à leur exploitation. Ceci justifie l’intérêt pour les entrepôts de données et singulièrement les entrepôts de données spatiales qui couplent les fonctionnalités d’un Système d’Information Géographique (SIG) à celle d’un entrepôt OLAP
(On-Line Analytic Processing).
Cependant, les travaux sur le domaine émergeant des entrepôts de données spa-tiales [AHM 04, PAP 01, PAP 02, PRA 04, RIV 01, RAO 03] traitent essentiellement d’aspects généraux de ces systèmes indépendamment des applications. Ils abordent en particulier l’indexation, l’agrégation spatiale et les interfaces utilisateurs.
Bien que le domaine du trafic routier pourrait tirer un grand bénéfice de cette ap-proche, à notre connaissance, très peu de travaux [LU 04, SHE 02] ont été menés sur ce domaine. Une des raisons en est peut-être qu’ils nécessiteraient une collaboration de chercheurs spécialistes des transports, de la modélisation mathématique, de la fouille de données et des bases de données. Ainsi, les fonctionnalités des entrepôts de don-nées spatiales pourraient être étendues de manière à couvrir les besoins d’applications dans des domaines dépassant largement le cadre du trafic routier.
Cet article présente une démarche engagée pour mener des travaux dans ce sens dans le cadre du projet CADDY1de l’ACI "Masse de Données". La section 2 introduit
au domaine du trafic routier puis en étudie les données et les applications existantes. La section 3 présente, dans une première partie, les objectifs et les premières démarches suivies pour élaborer un entrepôt de données spatiales destiné au trafic routier. L’éla-boration d’un tel entrepôt nécessite l’approximation et la classification de séquences temporelles : les approches utilisables dans cette perspective sont exposées dans la deuxième partie de cette section.
2. Domaine du trafic routier : données et applications
Dans une optique de compréhension de l’évolution du trafic routier, différents types d’information sont nécessaires tels que [SCH 98] :
– Les valeurs des variables macroscopiques de trafic comme le débit (traffic
vo-lume ou flow rates), la vitesse, le taux d’occupation (road occupancy), la concentration
(ou densité) et le temps de parcours qui sont recueillis à l’aide de capteurs déposés sur les axes routiers.
– La topologie du réseau routier qui décrit la position des capteurs sur le réseau. – Les événements affectant le réseau tels que les pannes de feu de circulation, les travaux, les accidents, etc.
– Les mesures météorologiques et environnementales (neige, verglas, pollution, etc.)
Le trafic routier est modélisé selon différentes approches classées selon un ni-veau de granularité ou nini-veau de détail lié au nombre de véhicules. Les modélisations sub-microscopiques prennent en compte toutes les composantes des véhicules et leurs interactions avec l’environnement. Les modèles microscopiques décrivent le compor-tement de chaque véhicule et conducteur dans un environnement modélisé avec lequel ils interagissent [CAR 01] ; les techniques multi-agents sont fréquemment utilisées dans ce cadre [ESP 95, NII 01, BAL 05]. L’approche mésoscopique décompose le tra-fic en pelotons de véhicules. Enfin, l’approche macroscopique [HEL 95] consiste à modéliser l’écoulement de flux de véhicules dans les sections du réseau de déplace-ment.
Dans la suite de l’article, nous nous intéressons uniquement aux données macro-scopiques et à la topologie du réseau.
2.1. Données temporelles et spatiales du trafic routier
Les modèles macroscopiques assimilent l’écoulement du trafic routier à un flot continu sur chaque section de route et utilisent les équations de la mécanique des fluides. Le trafic est décrit à l’aide de variables macroscopiques temporelles mesurées par des capteurs. La sous-section 2.1.1 présente les variables macroscopiques du tra-fic routier ainsi que les principaux capteurs qui servent à les mesurer. La sous-section 2.1.2 décrit les données spatiales du trafic routier, c’est-à-dire la modélisation du ré-seau routier sur lequel sont positionnés les capteurs.
2.1.1. Données temporelles : les variables macroscopiques du trafic
Le réseau routier est structuré en routes et autoroutes. Chaque axe de circulation est décomposé longitudinalement en sections, encore appelées tronçons. La chaussée est elle-même constituée de voies. Les variables macroscopiques permettent de dé-crire l’état du trafic dans l’espace et dans le temps. Elles sont définies de la manière suivante :
– Le débit (q) traduit le nombre de véhicules qui passent en un point x donné sur le
réseau pendant un intervalle de tempsδt. Il s’exprime en véhicules par unité de temps,
généralement des heures ou des minutes.
– La concentration (k) ou densité de trafic traduit la répartition des véhicules le
long des axes du réseau. Elle est définie à l’instant t sur un tronçon routier donné
par le rapport entre le nombre de véhicules présents à cet instant sur ce tronçon et la longueur du tronçon. La concentration s’exprime en véhicules par kilomètre.
– Le taux d’occupation (τ ) est une variable largement utilisée dans le domaine de
la gestion et de la régulation du trafic car il peut être mesuré à faible coût [COH 93]. Il est égal au rapport entre le temps de passage d’un véhicule sur le capteur et l’intervalle de temps de la mesure. Il est proportionnel à la concentration. Le taux d’occupation est une grandeur sans dimension (pourcentage).
– La vitesse moyenne est définie de deux manières. La vitesse moyenne dans le temps en un pointx d’un axe de circulation est la moyenne arithmétique des vitesses
instantanées des véhicules passant enx pendant un intervalle de temps δt. La vitesse
moyenne d’espace [WAR 52] est définie sur un tronçon routier à l’instant t par la
moyenne arithmétique des vitesses des véhicules présents sur le tronçon à cet instant. Les vitesses s’expriment en kilomètres par heure.
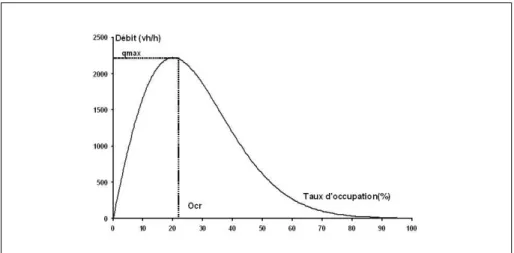
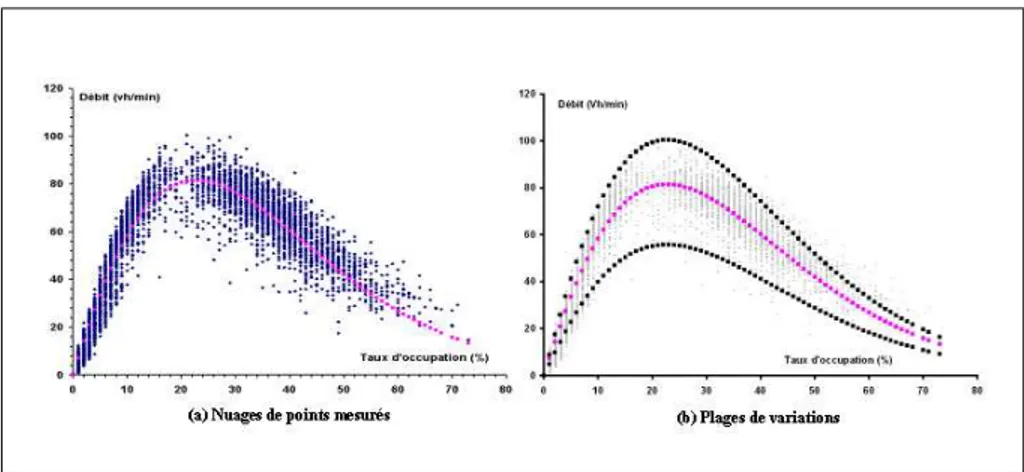
Figure 1. Diagramme fondamental représenté dans le plan (débit, taux d’occupation). On observe à l’aide de mesures effectuées sur le terrain que les valeurs du débit et du taux d’occupation sont relativement dispersées en raison de l’évolution dynamique du trafic (cycle d’hystérésis2). Cependant, des méthodes statistiques de régression per-mettent de trouver une fonction polynomiale, logarithmique ou exponentielle dont la courbe (voir figure 1) passe au plus près du nuage des points mesurés (voir figure 2.(a)). Cette courbe, appelée diagramme fondamental, exprime le débit (q) en
fonc-tion du taux d’occupafonc-tion (τ ). La partie gauche de la courbe jusqu’au point critique Cr de coordonnées (Ocr, qmax) traduit un écoulement fluide du trafic. A partir du point critique Cr, le débit diminue ce qui indique une congestion de plus en plus
importante. La valeurqmaxcorrespond au débit maximal susceptible d’être écoulé, c’est-à-dire à la capacité de l’infrastucture [COH 93] ; au delà de ce seuil, le taux d’occupation augmente alors que le débit diminue et la circulation est dite saturée. Il est à noter que pour un débit donné, la circulation peut être fluide ou saturée. Un débit nul peut notamment signifier que le tronçon est vide ou que le taux d’occupation a
teint sa valeur limite. Les diagrammes fondamentaux exprimant les relations entre les variables de débit, de vitesse et/ou de concentration sont déductibles du diagramme fondamental entre le débit et le taux d’occupation.
Figure 2. Variation du débit en fonction du taux d’occupation.
Pour plus de détails sur les variables macroscopiques du trafic routier et sur leurs relations, le lecteur est invité à consulter [COH 93, LIE 02].
Les capteurs de mesure des variables du trafic routier sont reliés à des détecteurs, eux-mêmes faisant partie d’une station de mesure. La station de mesure est équipée d’un moyen d’acquisition en lien avec les détecteurs, d’un moyen de stockage et d’un moyen de transmission permettant de restituer les mesures effectuées. Nous nous in-téressons ici à l’élément externe qu’est le capteur et présentons les principaux types utilisés pour mesurer les états du trafic.
– Les boucles électromagnétiques, encore appelées inductives, représentent le type de capteur le plus souvent utilisé. Chaque boucle électromagnétique est enfouie dans la chaussée sous une voie donnée. La boucle est activée en présence d’un véhicule, désactivée dans le cas contraire. Ce type de capteur permet donc de mesurer direc-tement le taux d’occupation. Par déduction, on obtient le débit et le temps inter-véhiculaire très utilisé pour les applications liées à la sécurité. La concentration est obtenue en divisant le taux d’occupation par la longueur moyenne "électrique3". Pour
estimer les vitesses ou connaître le sens de passage des véhicules, il faut installer deux boucles successives (boucle double) sous la voie.
– Les capteurs pneumatiques sont constitués d’un câble de caoutchouc relié à un manomètre. Le câble est tendu en travers de la voie ou de la chaussée sur laquelle on veut effectuer la mesure. L’augmentation de pression due au passage de chaque essieu est détectée par le manomètre et il est ainsi possible de compter les véhicules. En considérant deux essieux par véhicule, on obtient le nombre de véhicules pour une
période donnée et donc finalement le débit. Ces capteurs sont plus fragiles que les boucles électromagnétiques. Il est à noter que l’installation de deux capteurs pneuma-tiques distants de 1 à 2 mètres permet également de mesurer les vitesses.
– Les caméras vidéo couplées à un système de traitement d’images peuvent éga-lement être utilisées. Elles permettent d’obtenir des informations complémentaires comme la longueur des files d’attente par exemple. Il s’agit d’un capteur spatial, à la différence des boucles éléctromagnétiques et des capteurs pneumatiques.
– D’autres types de capteurs existent tels que les détecteurs à ultrasons, les cap-teurs à micro-ondes ou radars à effet Doppler à faisceaux directifs, les magnétomètres et les capteurs optiques (photodiode, phototransistor ou barrière laser).
Pour plus d’information sur les types de capteurs, le lecteur peut se reporter à [Cer01]. En raison des coûts liés à l’installation et à la maintenance des capteurs, ceux-ci n’assurent qu’une couverture partielle du territoire. Sur le réseau routier national, les capteurs sont utilisés par l’Etat pour effectuer la surveillance permanente et établir des statistiques (connaître le volume de trafic sur certains tronçons de routes nationales). En moyenne, on compte une boucle éléctromagnétique tous les 40 kilomètres. Sur les autoroutes concédées4, des boucles sont placées à des fins d’exploitation un peu
en amont et en aval des échangeurs soit environ tous les 20 kilomètres en moyenne. En milieu urbain, les capteurs sont situés essentiellement sur les grands axes et aux abords des intersections, notamment pour permettre la régulation du trafic. Sur le pé-riphérique parisien, en chaussée intérieure et extérieure, on trouve une boucle simple tous les 500 mètres et une boucle double tous les 2500 mètres. Au total, en Ile-de-France, en milieux urbain et périurbain confondus, on trouve environ 5000 boucles électromagnétiques dont 4000 sur le réseau du Système d’Information pour un Ré-seau Intelligible aux USagers (SIRIUS) du Service Interdépartemental de la Sécurité et de l’Exploitation de la Route (SISER). Le système SYTADIN [Syt] repose enR
particulier sur SIRIUS.
Outre le nombre de capteurs mis en place, leur positionnement peut avoir une influence importante sur la mesure des variables du trafic. Aux abords des carrefours notamment, la position des capteurs est très liée au système de régulation mis en place. Enfin, les capteurs ne sont pas fiables à 100%. Par exemple, en 1990, l’imprécision sur les mesures issues des capteurs pneumatiques pouvait dépasser 20% en période de saturation [COH 93]. Pour les boucles électromagnétiques, l’erreur sur les mesures de débit est généralement comprise entre 3% et 5%. Cependant, l’erreur peut atteindre 20% dans certains cas particuliers. De plus, le taux de panne des boucles électroma-gnétiques est de l’ordre de 10% à 20% en moyenne et quand les exploitants n’assurent pas une maintenance régulière, elle peut atteindre 50% (source [Cer01]).
4. La concession est le système permettant à l’Etat de confier pour un temps donné à une société
d’autoroutes la construction et l’entretien d’une autoroute. La société rembourse ses créances de construction grâce au péage acquitté par chaque utilisateur.
Les variables macroscopiques représentent des données temporelles agrégées se-lon les besoins du terrain de quelques secondes à quelques minutes voire heures. Ces données temporelles sont associées à des informations spatiales sur le réseau routier (données topologiques décrivant les routes du réseau routier).
La sous-section suivante décrit comment le réseau routier est modélisé. 2.1.2. Données spatiales : modélisation du réseau routier
La modélisation d’un réseau routier consiste à construire une abstraction des ments de l’infrastructure et de l’environnement. Il s’agit donc de modéliser les élé-ments comme les routes, leurs intersections, la signalisation horizontale et verticale, le terrain, les conditions météorologiques, etc. Il existe différents types de modéli-sations [CAR 01] : graphes des routes et de leurs intersections, modèles analytiques ou géométriques filaires représentant les axes de circulation, modèles géométriques en deux ou trois dimensions, modélisation symbolique, modèles de SIG (Systèmes d’Information Géographique), etc. Cette sous-section présente uniquement l’utilisa-tion des graphes et des SIG.
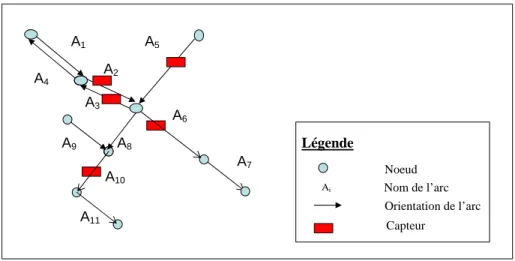
A titre d’exemple, nous décrivons comment le système CLAIRE [SCE 94, SCE 00, SCE 04] modélise les données spatiales. Dans ce système, les données spatiales issues du trafic correspondent à la description des positions des capteurs sur le réseau routier. Ces données sont dites statiques puisque la position des capteurs est rarement mise à jour ; exceptionnellement des mises à jour se font lors de travaux ou lors d’ajout de nouveaux axes routiers ou de nouveaux capteurs sur des axes existants. Le réseau routier est modélisé par un graphe orienté où chaque arc représente une voie de la chaussée sur un tronçon de route. Un axe routier représente un chemin dans le graphe. Chaque capteur est placé sur un arc donné. La figure 3 montre un exemple de cette modélisation. Certains arcs peuvent être dépourvus de capteur, la répartition des cap-teurs sur le réseau étant faite selon les besoins du système. Un axe peut donc être décrit soit par une suite d’arcs, dans le cas où l’on s’intéresse à la description spatiale, soit par une suite de capteurs lorsqu’on s’intéresse aux mesures de trafic obtenues par les capteurs placés sur cet axe. Une représentation similaire est utilisée dans le système prototype SITTI5[DEM 00].
La modélisation est difficilement indépendante des applications. Comme indiqué dans [CAR 03], un graphe peut apparaître avec différents niveaux de granularité. Par exemple, les nœuds du graphe peuvent représenter les villes, et les arcs les axes rou-tiers ; à un niveau de granularité plus fin, les arcs peuvent représenter des voies sur des tronçons de route, et les nœuds les extrémités des tronçons. En étiquetant les som-mets et les arcs du graphe - on parle alors de graphe valué - on peut répondre d’une manière simple aux besoins des algorithmes de recherche de chemin, de visualisation des états des axes des réseaux (ce que permettent par exemple les systèmes SYTADIN [Syt] et CLAIRE) ou encore de simulations de trafic. Cette modélisation se trouve au
5. Serveur d’Information du Trafic sur Toulouse par Internet - prototype développé par le
A1 A2 A5 A4 A8 A10 A9 A7 A3 A11 A6 Noeud Légende Capteur Nom de l’arc Ai Orientation de l’arc
Figure 3. Représentation du réseau routier par un graphe orienté.
coeur des applications du domaine des transports et de leur intégration, sujet sur lequel l’INRETS mène des travaux de recherche et développement [CAR 02].
Les Systèmes d’Information Géographique (SIG) manipulent des données ayant un caractère spatial, c’est-à-dire des données représentant des phénomènes survenus sur, au-dessus ou au-dessous de la surface terrestre [SCH 01]. L’extension de ces sys-tèmes au domaine des transports a donné naissance à l’acronyme GIS-T pour
Geo-graphic Information System for Transportation [THI 00]. La topologie est représentée
dans les SIG selon différents modèles appelés modèles spaghetti, réseau ou topolo-gique (le lecteur est invité à consulter [RIG 02] pour une description détaillée de ces modèles). Lorsque le réseau routier est modélisé sous la forme d’un graphe, comme nous l’avons précisé précédemment, le modèle topologique sous-jacent dans un SIG est le modèle dit réseau (network model). Les données spatiales sont représentées dans ce cas en mode vectoriel (ou mode vecteur) [SCH 01]. Le modèle réseau est le plus utilisé dans le domaine du transport [THI 00]. En plus de la description spatiale des données, ce modèle permet d’ajouter d’autres attributs aux données. Dans le prototype SITTI, des attributs tels que les identificateurs, les longueurs et le sens des voies sont stockés dans la base géographique pour caractériser les tronçons de route. En outre, ce système utilise le mode dit raster (ou tessellation - représentation sous la forme d’une grille de cellules) pour les données relatives au fond de carte. Les SIG sont uti-lisés dans le domaine des transports pour leur capacité à gérer les données spatiales, à les interroger et à les visualiser. Ils sont généralement couplés à des systèmes d’in-formation de transport (TIS - Transportation Ind’in-formation System) [THI 00], les SIG n’offrant pas toujours toutes les fonctionnalités nécessaires au domaine du transport [RAL 00]. Dans [MIL 01], par exemple, les auteurs couplent un SIG avec leur outil de gestion de trafic, afin de pouvoir visualiser les congestions et aider les utilisateurs
à déterminer leur itinéraire. Le système CLAIRE utilise également un SIG dans ses implémentations actuelles.
Le lecteur est invité à consulter [GOO 00, THI 00] pour plus de détails sur l’asso-ciation des SIG au domaine du transport.
2.2. Fonctionnalités des applications du domaine du trafic routier
On distingue trois fonctionnalités dans les applications du domaine du trafic rou-tier [BIE 91] : le recueil des données, l’analyse et l’interprétation de ces données, et la décision et le contrôle qui en résultent. Ces trois fonctionnalités sont présentées ci-dessous en illustrant plus particulièrement les deux dernières au travers de l’appli-cation CLAIRE.
2.2.1. Recueil des données
Comme évoqué précédemment, la couverture en terme de capteurs est rarement totale sur le réseau et les mesures peuvent comporter des erreurs ou être indisponibles dans le cas de panne de capteur. Le recueil des données brutes fournit par conséquent une vision des états des axes de circulation du réseau global partielle et empreinte d’erreurs. C’est la raison pour laquelle des méthodes de qualification (=identification) des données aberrantes et de reconstitution des données manquantes sont développées. La qualification des données aberrantes comprend la détection des pannes franches, facilement détectables par des tests de plausibilité simples ainsi que des méthodes plus élaborées. Une première méthode consiste à se référer au diagramme fondamental et à autoriser une marge d’erreur sur le débit pour un taux d’occupation mesuré. Hors de la plage d’erreur, les mesures sont considérées invalides. Une deuxième méthode proposée dans [HAJ 97] consiste à calculer deux courbes définissant une enveloppe autour de la courbe du diagramme fondamental (voir figure 2.(b)). Toute mesure si-tuée hors de l’enveloppe est déclarée invalide. Le diagramme fondamental peut parfois être utilisé pour remplacer les données aberrantes.
La reconstitution des données manquantes peut se faire selon différentes approches. L’approche automatique utilise le filtre de Kalman [KAL 60]. L’approche statistique est basée sur la notion de dépendance entre les capteurs proches dans l’espace. Cette méthode calcule le coefficient de corrélation linéaire de Bravais-Pearson [HAJ 97]. Les mesures non fournies par un capteur en panne sont estimées à l’aide des mesures fournies par les capteurs voisins. Notons que les capteurs dits voisins sont sélectionnés grâce à un découpage spatial qui évite de calculer le coefficient de corrélation linéaire avec des capteurs éloignés. La dimension temporelle est utilisée pour la recherche du capteur remplaçant. [HAJ 00] propose un autre algorithme de reconstitution basé sur la résolution des équations mathématiques d’un modèle d’écoulement macroscopique et dynamique du trafic. La résolution est accomplie en utilisant une discrétisation spatio-temporelle.
La fonction de recueil des données peut aussi avoir une fonction de génération de données dérivées des données mesurées. Il s’agit par exemple de données concernant la demande de déplacement : répartition du flux à une intersection, répartition entre différentes origines et destinations.
2.2.2. Analyse et interprétation des données
La fonction d’interprétation et d’analyse des données détermine les états du trafic dans le réseau et permet leur suivi (monitoring). Cette fonction nécessite la conser-vation de données recueillies. Elle permet de construire une interprétation compré-hensible de l’état du réseau ou de certains de ses éléments par l’utilisation d’états symboliques. Ainsi, l’état symbolique d’un axe de circulation peut être exprimé par "fluide" ou "saturé".
Le logiciel CLAIRE [SCE 94, SCE 00, SCE 04] permet de suivre l’évolution d’un nombre quelconque d’indicateurs concernant un réseau donné. CLAIRE définit un ré-seau à partir d’ensembles d’entités de même nature : des graphes, des nœuds, des arcs, des véhicules, des personnels navigants ou des passagers. Un ensemble d’indicateurs est attaché à chaque entité. Par exemple, les indicateurs débit, taux d’occupation et vitesse peuvent être attachés à une entité arc. Un indicateur peut être associé à trois variables contenant respectivement la valeur théorique, la valeur réelle et la valeur pré-vue de l’indicateur. Chacune de ces variables est issue d’une mesure en temps réel ou est calculée à partir d’autres variables de l’indicateur ou encore d’autres indicateurs. Chaque indicateur est également associé à une quatrième variable dite supervisée pou-vant prendre des états symboliques prédéfinis. Cette valeur peut être fonction de l’écart calculé entre la valeur réelle et la valeur théorique ou bien être fonction d’un seuil de tolérance. Les variables supervisées permettent de déterminer les congestions.
2.2.3. Décision et contrôle
La fonctionnalité de décision et de contrôle propose à l’opérateur des actions de contrôle et peut dans certains cas lancer l’exécution de la commande associée. Un système expert d’aide à la décision peut implémenter ce niveau fonctionnel.
Le système CLAIRE agit en temps réel et en temps différé.
En temps réel, le but des actions de contrôle est d’adapter le service de transport public. Les actions concernent d’une part les nœuds du réseau, comme la synchroni-sation des feux de circulation, et d’autre part les conducteurs ou les véhicules, comme la mise en service d’un autobus ou le remplacement d’un agent. Pour chaque événe-ment de perturbation, l’opérateur ou le système CLAIRE peut décider d’une action de commande.
En temps différé, CLAIRE aide les opérateurs à déterminer les causes de conges-tion et les acconges-tions à mener. Des points noirs sont identifiés en utilisant une méthode de classification de perturbations et d’événements. L’observatoire se fonde sur le raison-nement à base de cas pour classifier et identifier les perturbations ou les évéraison-nements
récurrents. Il permet de résumer une période d’exploitation selon les besoins des plani-ficateurs, des contrôleurs, des décideurs, des opérateurs et des autorités organisatrices. A l’heure actuelle, les données utilisées par le système CLAIRE sont structurées et stockées dans des fichiers ou des bases de données adaptés aux fonctionnalités indi-quées précédemment. La suite de cet article montre que le stockage des données dans un entrepôt ouvre de nouvelles perspectives.
2.3. Entrepôts de données pour le trafic routier
Immon [INM 92] définit un entrepôt de données (datawarehouse) comme une col-lection de données organisées par sujet, temporelles et persistantes. Cette colcol-lection est destinée à être utilisée dans le processus d’aide à la décision. Les utilisateurs in-terrogent les données à des fins d’analyse en se basant sur des données historisées, agrégées ou résumées [DOU 01]. Ces données peuvent provenir de différentes sources et sont regroupées dans une base unique conçue pour des analystes et des décideurs. La visualisation des données des entrepôts se fait généralement via un cube
multi-dimensionnel. Un tel cube est défini par un ensemble de cellules qui contiennent des mesures, comme le débit, dépendant de dimensions, comme l’emplacement du
cap-teur, la date et l’instant de saisie de la donnée. Par agrégation, on peut construire d’autres cubes. Par exemple, en agrégeant sur la dimension date et sur la dimension horaire, on peut obtenir un cube faisant apparaître pour chaque capteur le débit moyen par heure pour les lundis de 2004 entre 12h et 14h.
Cet exemple introduit aux entrepôts de données spatiales. Ce domaine de recherche très récent a donné lieu à des approches de visualisation des résultats des requêtes [RIV 01], d’indexation [RAO 03, PAP 02] et d’agrégation spatiale [PAP 01, PRA 04]. A notre connaissance, l’utilisation d’entrepôts de données spatiales pour le trafic rou-tier n’a été faite que dans [LU 04, SHE 02] où un entrepôt de données est établi à des fins de stockage et de visualisation. Les mécanismes de visualisation se basent sur l’utilisation de couleurs permettant de différencier les cas de congestion de trafic des cas de fluidité. La variation de la couleur est fonction de l’état du trafic, ce qui facilite la compréhension des données du trafic par l’utilisateur. La visualisation relève de la fonction de suivi du trafic routier. Cependant, elle ne concerne pas les fonctionnalités de décision et de contrôle.
La section suivante présente comment un entrepôt de données spatiales pourrait prendre en compte ces fonctionnalités.
3. Vers un entrepôt de données complexes pour le trafic routier
Cette section présente les objectifs et la démarche suivie dans le cadre du projet CADDY pour le domaine du trafic routier et dresse un état de l’art des approches propres à la problématique du projet.
3.1. Le projet CADDY
Le projet Contrôle de l’Acquisition de Données temporelles massives, stockage
et modèles DYnamiques6, CADDY, a démarré en juillet 2003. Ce projet
multidiscipli-naire fait intervenir des aspects de modélisation mathématiques, de statistiques, d’ana-lyse de données et de bases de données. Il a pour axe de recherche principal l’étude de méthodes d’acquisition, de représentation et de recherche des séquences temporelles (time series) interdépendantes. Notre objectif est de proposer une méthodologie géné-rale permettant d’améliorer le fonctionnement des systèmes complexes manipulant ce type de données. Nous avons mené nos travaux dans le cadre des systèmes de trafic routier en collaboration avec l’INRETS. Ceci a motivé notre intérêt pour un entrepôt de données spatiales.
3.1.1. Objectifs
Les mesures des variables macroscopiques du trafic associées à une représentation du réseau routier sont couramment utilisées par les applications du domaine du trafic routier. L’utilisation des bases de données classiques offre des facilités de stockage et permet d’interroger les données brutes et de répondre à des requêtes du type "Quelles sont les valeurs de débit d’un capteurc à une date d pour toutes les heures ?", Quel
est le taux d’occupation moyen d’un capteurc à une date d entre l’heure h et l’heure h + i ?" ou "Quels sont les capteurs ayant eu, à une date d, un débit moyen inférieur à m entre 16h et 18h".
Les mécanismes d’agrégation, comme des calculs de moyenne ou de taux, pro-posés dans les entrepôts de données OLAP (On-Line Analytic Processing) sont bien adaptés à des applications classiques de gestion, basées sur l’exploitation de l’histo-rique des données. Ils permettent, grâce au stockage de données agrégées, de répondre rapidement à des requêtes de la forme "Pour chaque capteur, quel est le débit moyen pour les lundis de 2004 entre 12h et 14h ?". Lorsque des états symboliques sont cal-culés à partir des données brutes et de seuils fixés par les experts du domaine du trafic routier, l’entrepôt peut stocker ces états symboliques et permettre ainsi de répondre à des requêtes telles que "Quels sont les états symboliques (ex. fluide ou saturé) du trafic sur un ensemble de capteurs pour les jeudis du premier semestre 2004 entre les heures 17h et 20h ?".
Dans le projet CADDY, nous proposons d’étendre les mécanismes des entrepôts de données en utilisant des techniques de résumé plus fines à partir desquelles il est pos-sible d’extraire de l’information et de l’interroger à différents niveaux hiérarchiques. Dans CADDY, les données sont regroupées sur des critères temporels (ex. sur les jours ouvrés), spatiaux (ex. en agrégeant les arcs modélisant la rue de Rivoli) ou spatio-temporels. Un résumé, est associé à chaque regroupement. Il correspond à une repré-sentation simplifiée mais fidèle de l’information d’origine (par exemple une courbe de débit type). Les résumés sont calculés à partir des courbes de débit et taux d’occupa-tion ou des états symboliques associés et sont organisés en hiérarchie.
A partir des données d’origine et des résumés, CADDY doit permettre de répondre non seulement à des requêtes de bas niveau, mais aussi et surtout à des requêtes plus complexes utilisant l’information des résumés. Ces requêtes complexes peuvent être par exemple "Etant donné un événement (ex. match de rugby) devant avoir lieu à un endroite (ex. le stade Charletty à Paris), à une date d et une heure h quel est l’état
prévu du trafic dans la zonez aux heures h − i ou h + j ?", "L’état actuel (en temps
réel) du trafic dans une zonez est-il habituel ?", "La rue de Rivoli est-elle bouchée le
dimanche entre 14h et 16h ?", "La situation observée sur le trafic correspond t’elle à des situations analogues du passé ?" ou "Y a t’il des simultanéités de congestion sur des zones non connexes ?".
Alors que les requêtes de bas niveau consistent à identifier des états de trafic ou à prédire de futurs états en réalisant des statistiques sur ces états identifiés, les autres types de requêtes nécessitent, quant à eux, l’extraction de connaissances à par-tir des données stockées dans l’entrepôt. Les données de base de l’entrepôt, que nous présentons dans la sous-section 3.1.2, doivent être organisées de telle sorte qu’elles puissent permettre de répondre à tous les types de requêtes cités précédemment. La sous-section 3.1.3 présente la démarche suivie.
3.1.2. Données
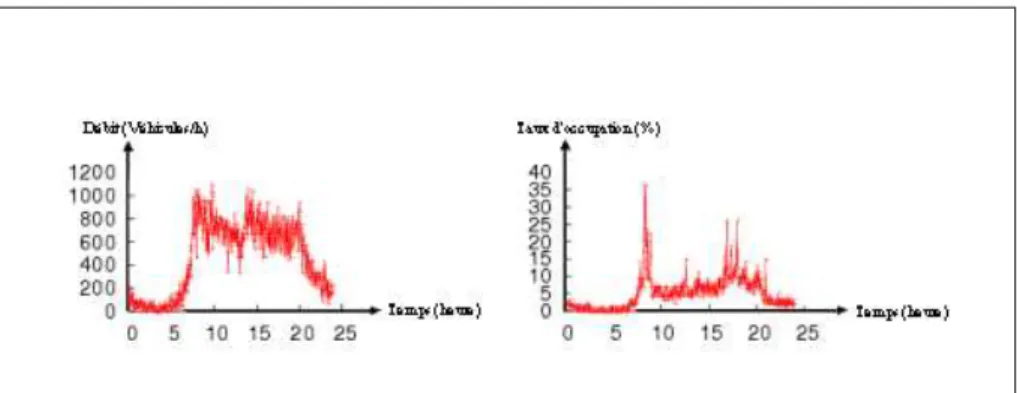
Figure 4. Exemples de séquences journalières de débit et de taux d’occupation. Les données mises à notre disposition sont extraites de celles utilisées dans le sys-tème CLAIRE : le graphe routier décrivant la répartition des capteurs sur le réseau routier d’une ville française et, pour chaque capteur, les mesures des variables macro-scopiques de débit et de taux d’occupation.
Les mesures de débit et de taux d’occupation constituent des séquences tempo-relles (time series). La figure 4 en présente un exemple pour chacune des deux va-riables. Les valeurs de ces séquences sont enregistrées toutes les 3 minutes par plus que 400 capteurs. Elles forment un ensemble d’environ 400 000 valeurs élémentaires par jour (480 valeurs de débit et 480 valeurs de taux d’occupation par capteur). En outre, ces variables sont interdépendantes puisqu’elles sont reliées par un diagramme
fondamental (voir section 2.1.1 - figure 1). Elles correspondent donc complètement aux types de données de la problématique du projet CADDY.
Une main courante d’annotations est disponible en complément des mesures pré-cédentes. Elle reflète des événements, positionnés dans l’espace et dans le temps, ayant pu affecter le trafic : incidents sur la voie publique, pannes de feux de signalisation, chute de neige, etc.
D’autres séquences temporelles pertinentes pourraient être ultérieurement ajoutées dans l’entrepôt, par exemple des données propres au transport public ou des données météorologiques.
3.1.3. Démarche
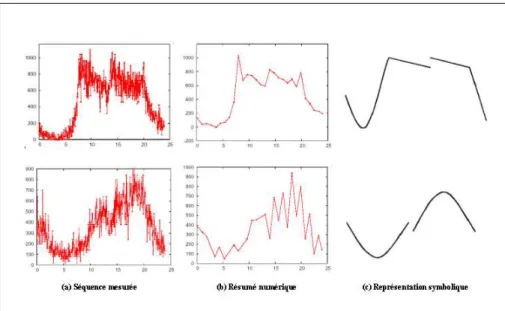
Figure 5. Exemple de résumés de séquences temporelles de débit.
Pour répondre aux objectifs à partir des données dont on dispose, les séquences journalières de débit et de taux d’occupation, associées au graphe routier, doivent être représentées de telle sorte qu’elles puissent être stockées, manipulées et interrogées au sein d’un entrepôt de données. Il y a en effet un niveau d’abstraction important entre les objectifs à atteindre et les données dont on dispose.
Les séquences temporelles contiennent chacune 480 valeurs. Stockées telles quelles dans une base de données, elles offrent un potentiel faible d’interrogation. De plus, le temps d’exécution des requête sur de telles séquences est proportionnel à leur taille. Une première étape pour la constitution d’un entrepôts de données spatio-temporelles consiste donc à les résumer.
Une séquence peut être résumée numériquement ou représentée de manière sym-bolique. Le choix du type de résumé est fortement lié au type de requête auquel le système doit pouvoir répondre. La figure 5.(b) présente un exemple de résumés nu-mériques de séquences journalières de débit : les séquence résumées ne contiennent qu’une trentaine de valeurs par rapport aux 480 valeurs des séquences mesurées. Les mêmes séquences sont représentées par des descripteurs symboliques sur la figure 5.(c). Les descripteurs smboliques peuvent faciliter l’expression des requêtes utilisa-teur.
L’évolution des valeurs des séquences temporelles issues du trafic routier est forte-ment corrélée avec l’activité humaine. Par exemple, sur les séquences temporelles de la figure 4 concernant le débit et le taux d’occupation d’un jour de semaine ordinaire, on peut remarquer que le débit augmente pendant les heures de pointe (entre 8h et 10h et entre 17h et 20h) et que, de manière corrélée, les pics du taux d’occupation sont vi-sibles pendant ces mêmes tranches horaires. Pendant les heures de pointe, la présence d’une congestion sur certains axes routiers représente donc une situation habituelle pouvant être considérée comme typique. En revanche, pendant les heures où le trafic devrait être fluide, la détection d’une congestion permet d’alerter le système sur la pré-sence d’une situation "atypique". Ceci amène à la définition de classes de séquences représentant des profils types de circulation. Dans le contexte du trafic routier, le fait que les séquences sont issues de capteurs placés sur des axes routiers ajoute un carac-tère spatial à leur caractére temporel. Ces séquences peuvent donc être regroupées en classes sur des critères temporels et/ou des critères spatiaux. Par exemple, le fait que les séquences des lundis se ressemblent entre elles mais diffèrent des séquences du di-manche, qui elles-mêmes se ressemblent entre elles, peut amener à créer deux classes, une pour les lundis et une pour les dimanches. De même, le fait que les séquences temporelles générées, à une heure donnée et à une date donnée, par des capteurs suc-cessifs sur un axe se ressemblent peut amener à regrouper ces séquences dans une même classe.
Nous nous sommes focalisés dans un premier temps sur la classification des sé-quences, en ne considérant que leur caractère temporel. Le but est d’étudier comment se répartissent les séquences et de voir si des classes créées sur le critère temporel per-mettent de déduire des informations sur le critère spatial. L’objectif à terme du projet CADDY est de proposer aux utilisateurs un outil d’aide à la décision permettant d’ana-lyser les données à un niveau spatio-temporel : partir du comportement temporel au niveau capteur (séquence temporelle brute ou résumée d’un capteur) pour arriver à un comportement global d’un système de trafic (séquences spatio-temporelles brutes ou résumées).
La sous-section suivante présente plusieurs approches d’approximations des sé-quences temporelles et de classification qui pourraient être utilisées dans le projet CADDY.
3.2. Etat de l’art des approches d’approximation et de classification de séquences
temporelles
3.2.1. Approximation numérique
Les méthodes numériques d’approximation de séquences temporelles permettent de représenter une séquence den valeurs par un vecteur de k valeurs (k n). Il existe
plusieurs méthodes d’approximation de séquences temporelles [AGR 93, CHA 99, CHA 02, FAL 04, FAL 94, HOT 33, KEO 01, KEO 00, KEO 98, KEO 99, PEA 01, RAF 99, WU 00, YI 00, HOT 33]. Ces méthodes peuvent être divisées en deux ca-tégories selon le type de traitement effectué : (1) les fonctions qui représentent les séquences par des segments, et (2) les méthodes de transformation qui modifient l’es-pace initial de définition des séquences.
Dans la première catégorie, les méthodes PAA (Piecewise Aggregate
Approxima-tion) [KEO 00, YI 00], APCA (Adaptive Piecewise Constant ApproximaApproxima-tion) [CHA 02]
utilisent des fonctions d’ordre 0, constantes par morceaux. La méthode PLA
(Piece-wise Linear Approximation) [KEO 98, KEO 99, KEO 01] utilise, quant à elle, des
fonctions d’ordre 1. On peut bien sûr passer à des ordres supérieurs en utilisant des fonctions de Béziers ou splines [BAR 03].
La méthode PAA consiste à représenter une séquence temporelle den valeurs par
une fonction en escalier dek segments de même longueur, k étant fixé au départ. La
valeur de la fonction pour chaque segment est la moyenne desn/k valeurs successives
de la séquence d’origine correspondant au segment.
La méthode APCA est une extension de la méthode PAA où les segments peuvent ne pas avoir la même longueur. La méthode PLA utilise, quant à elle, des fonctions affines pour chaque segment. Dans ces deux méthodes, les longueurs de segment pou-vant être différentes, le problème consiste à déterminer le point de coupure entre chaque paire de segments. Différents algorithmes ont été proposés pour répondre à ce problème. Dans [HUG 03, KEO 01], ils sont répartis en quatre catégories allant de la plus rapide à celle qui permet de trouver la solution optimale. L’algorithme agrégatif construit les segments d’approximation de chaque séquence en considérant les valeurs de la séquence dans l’ordre de leur saisie. L’algorithme descendant et l’algorithme as-cendant sont récursifs. Le premier part de la séquence pour déterminer les segments d’approximation : à chaque étape, la segmentation de la séquence est calculée en di-visant en deux l’un des segments obtenu à l’étape précédente. Au départ du deuxième algorithme, les segments d’approximation sont construits à partir des paires de valeurs successives de la séquence puis, à chaque étape, l’algorithme fusionne deux segments obtenus à l’étape précédente. L’algorithme optimal permet d’obtenir une représenta-tion de la séquence enk segments en recherchant l’optimum global. Cet algorithme se
base sur le fait qu’une segmentation optimale enp segments (p ≤ k) est construite à
partir d’un premier segment et du résultat d’une segmentation optimale enp − 1
seg-ments. La condition d’arrêt de ces algorithmes est fixée par un nombre de segments ou un seuil d’erreur.
Les méthodes de transformation permettent de décomposer les séquences tempo-relles dans un espace de fonctions connues a priori, comme pour la Transformée de Fourier Discrète (DF Discrete Fourier Transform) et la Transformée en Ondelettes Discrètes (DWT Discrete Wavelet Transform) ou dans un espace de fonctions adapta-tives comme pour la méthode d’Analyse en Composantes Principales (ACP).
La Transformée de Fourier Discrète, utilisée dans [AGR 93, FAL 94, RAF 99], permet de décomposer une séquence temporelle den valeurs en une suite de
fonc-tions sinusoïdales. La séquences est représentée dans un espace de fréquences. Les amplitudes associées à ces fonctions, appelées coefficients de Fourier, sont utilisées pour décrire la séquence temporelle. Seulsk coefficients sont conservés, k étant
infé-rieur àn, soit les premiers, soit de préférence ceux qui correspondent aux fréquences
les plus représentatives.
Contrairement à laDF T , la Transformée en Ondelettes Discrète permet une
repré-sentation multirésolution d’une séquence temporelle dans un espace temps/fréquence. Les séquences ne sont plus décomposées en fonctions sinusoïdales mais en ondelettes. Chaque ondelette décrit la variation de la séquence en terme de fréquence, sur un in-tervalle de temps limité, d’où la transformation dans l’espace temps/fréquence.
Il existe plusieurs bases d’ondelettes. Dans [CHA 99], les ondelettes de HARR sont utilisées. Etant donnée une séquence den valeurs, le principe de cette méthode
consiste à de calculer à chaque niveau de résolution (1) les moyennes des paires de valeurs successives du niveau précédent et (2) les différences entre chaque valeur et la moyenne associée. Lesn coefficients d’ondelettes correspondent à la moyenne de
toutes les valeurs de la séquence obtenue au dernier niveau et à l’ensemble des dif-férences de chaque niveau de résolution. En choisissant le niveau de résolution, une séquence àn valeurs est seulement représentée par k coefficients parmi les n
coeffi-cients représentant la séquence.
L’analyse en composantes principales [PEA 01, HOT 33] est une méthode d’ana-lyse de données multidimensionnelles permettant de représenter un nuage dem points
àn dimensions dans un espace à k dimensions par projection des données sur k axes
bien choisis. Cesk axes maximisent l’inertie du nuage projeté, c’est-à-dire la moyenne
pondérée des carrés des distances entre les points projetés et leur centre de gravité. L’ACP permet ainsi de représenter chaque point multidimensionnel park coordonnées
appelées composantes principales. Ces composantes sont classées selon leur pouvoir explicatif (maximisation de la variance). Généralement, seules les deux ou trois pre-mières composantes principales sont utilisées afin de permettre une représentation lisible des points à projeter.
3.2.2. Représentation symbolique
La représentation symbolique permet de décrire une séquence temporelle par un ensemble de symboles discrets. La plupart des approches, dont [PAR 00], utilise la méthode de discrétisation Equal-length categorisation pour représenter symbolique-ment les séquences. Cette méthode consiste à diviser les domaines de valeurs de la
sé-quence en intervalles de même longueur et à associer un symbole à chaque intervalle. Ainsi, chaque valeur de la séquence est associée au symbole de l’intervalle auquel elle appartient. Cette méthode a été étendue en prenant des intervalles ayant des longueurs différentes et en associant un symbole, non plus à chaque valeur de la séquence, mais à la différence de deux valeurs successives [AND 97]. D’autres approches associent quant à elles des symboles aux segments d’approximation de la séquence obtenus par la méthode PAA [LIN 03] ou par la méthode APCA [HUG 03].
3.2.3. Classification automatique
Les méthodes de classification automatique permettent de partitionner un ensemble de vecteurs multidimensionnels en se basant sur un critère de proximité [HAL 01, JAI 99]. Ces méthodes, lorsqu’elles sont appliquées aux séquences temporelles, se répartissent en trois catégories. Les méthodes basées sur le partitionnement telles que K-means [DID 71, MCQ 67], PAM [KAU 90], CLARA [KAU 90] et CLARANS [NG 94] permettent d’obtenirk groupes de vecteurs, k étant généralement fixé par
l’utilisateur. Les méthodes hiérarchiques permettent de construire différents niveaux de partitions (de 1 à n-1 niveaux) en partant de n vecteurs en entrée. Parmi ces
méthodes, on peut citer les méthodes hiérarchiques par agrégation et par division [KAU 90], BIRCH [ZHA 96] et CURE [GUH 98]. Les méthodes basées sur la densité produisent des groupes de vecteurs dont la densité est suffisamment importante. L’im-portance de la densité se mesure à l’aide de seuils à fixer par l’utilisateur. DBSCAN [EST 96] est un exemple de ce type de méthodes.
Plusieurs solutions ont été proposées pour représenter les groupes ou partitions [JAI 99] :
– Un centre : un groupe peut être représenté par le centre de gravité des vecteurs du groupe. Le centre est donc un vecteur qui n’appartient pas nécessairement au groupe. La méthode K-means [DID 71, MCQ 67] utilise ce type de représentant.
– Un médoïde : le médoïde d’un groupe appartient obligatoirement à ce groupe et correspond au vecteur qui minimise les distances entre lui et les autres vecteurs du groupe. Les méthodes PAM [KAU 90], CLARA [KAU 90] et CLARANS [NG 94] utilisent un médoïde.
– Un ensemble de vecteurs : ces vecteurs délimitent la frontière du groupe. Le nombre de vecteurs dépend d’un seuil de contrôle. La méthode CURE [GUH 98] est basée sur ce principe.
Les groupes obtenus par les méthodes de classification automatique peuvent être étiquetés par des noms de classes et utilisés pour faire une classification supervisée.
4. Etat d’avancement et conclusion
Jusqu’à présent, nous avons étendu l’algorithme agrégatif appliqué à la méthode d’approximation PLA pour obtenir une représentation numérique synthétique des sé-quences temporelles. Nous travaillons à l’application des mécanismes de
représen-tation symbolique de [HUG 03] et testons une nouvelle méthode d’approximation spatio-temporelle. En terme de classification, nous avons appliqué l’approche K-means afin d’obtenir une première analyse des données. Le résultat de cette analyse nous a permis de définir des classes de comportement temporel par capteur. Cette analyse doit être étendue à la dimension spatiale. L’extension des méthodes d’approximation et de classification que nous envisageons ainsi que le résultat de leur application sur les données du trafic routier feront l’objet d’un autre article.
Au delà de ces premières réalisations, le but du projet est clair mais de nombreux aspects restent à aborder avant la construction d’un prototype intégrant l’ensemble des propositions nouvelles.
Remerciements
Les auteurs tiennent à remercier Simon Cohen, Habib Haj-Salem, Mehdi Danech-Pajouh de l’INRETS-GRETIA et Bernard Hugueney du LAMSADE pour leur parti-cipation à la documentation et à la relecture de l’article ainsi que tous les membres du projet CADDY.
Cadre de rédaction de l’article : le projet Contrôle de l’Acquisition de Données
temporelles massives, stockage et modèles DYnamiques, CADDY, est financé dans
le cadre de l’ACI (Action Concertée Incitative) "Masse de données" 2003. Il est co-ordonné par Florian De Vuyst de l’Ecole Centrale Paris (Laboratoire MAS) et réunit Georges Hébrail de l’ENS Télécom-Paris, Geneviève Jomier, Bernard Hugueney, Maude Manouvrier, Yosr Naïja et Laurent Steffan de l’Université Paris-Dauphine (LAM-SADE). CADDY s’appuie sur une collaboration avec Gérard Scemama et Olivier Carles de l’INRETS qui ont suggéré l’étude du trafic routier.
5. Bibliographie
[AGR 93] AGRAWALR., FALOUTSOS C., SWAMI A., « Efficient Similarity Search in Se-quence Databases », Int. Conf. on Foundations of Data Organization and Algorithms,
Chicago, Illinois, USA, Oct. 1993, p. 69–84.
[AHM 04] AHMEDT., MIQUELM., LAURINIR., « Continuous data warehouse : concepts, challenges and potentials », Proc. of the 12th International Conference on Geoinformatics, 2004, p. 157–164.
[AND 97] ANDRÉ-JÖNSSONH., BADALD.-Z., « Using Signature Files for Querying Time-Series Data », Proc. of the 1st European Symposium on Principles of Data Mining and Knowledge Discovery, Springer-Verlag, 1997, p. 211–220.
[BAL 05] BALBOF., PINSONS., « Dynamic modeling of a disturbance in a multi-agent sys-tem for traffic regulation », Decision Support Syssys-tems, vol. à paraître, 2005.
[BAR 03] BAR-JOSEPHZ., GERBERG., GIFFORDD., JAAKKOLA T., SIMONI., « Conti-nuous Representations of Time Series Gene Expression Data », Journal of Computational
Biology, vol. 10, no
[BIE 91] BIELLIM., « Artificial intelligence techniques for urban traffic control »,
Transpor-tation Research Part A, vol. 25A, no
5, 1991, p. 319–325.
[CAR 01] CARLESO., « Système de Génération Automatique de Bases de Données pour la Simulation de Situations de Conduite Fondée sur l’Interaction de ses Différents Acteurs », Thèse de doctorat, Université Paul Sabatier, Toulouse, Juillet 2001.
[CAR 02] CARLES O., « Modèle conceptuel de données générique pour la représentation des réseaux intermodaux », rapport, Dec. 2002, INRETS-GRETIA (France), Rapport de Convention DTT.
[CAR 03] CARLESO., SCEMAMAG., TENDJAOUIM., « Concepts génériques pour la super-vision des réseaux multimodaux », Génie Logiciel, vol. 65, 2003.
[Cer01] Les capteurs vidéo du trafic, No
111, Collection Technologies et Systèmes d’Infor-mation du CERTU, 2001, ISSN 0247-1159.
[CHA 99] CHANK.-P., FUA.-C., « Efficient Time Series Matching by Wavelets », Proc. of
the 15th Int. Conf. on Data Engineering (ICDE), Sydney, Australia, 1999, p. 126–133.
[CHA 02] CHAKRABARTIK., KEOGHE., MEHROTRAS., PAZZANIM., « Locally adaptive dimensionality reduction for indexing large time series databases », ACM Transactions on
Database Systems (TODS), vol. 27, no
2, 2002, p. 188–228.
[COH 93] COHENS., Ingénierie du trafic routier. Eléments de théorie du trafic et
applica-tions., Presses de l’Ecole Nationale des Ponts et Chaussées (ENPC) Paris, 1993.
[DEM 00] DEMMOUH., J.M. P., SCHETTINIF., « Serveur d’Information du Trafic routier sur Toulouse par Internet », rapport no
00048, 2000, LAAS-CNRS (Laboratoire d’Analyse et d’Architecture des Systèmes - France).
[DID 71] DIDAYE., « Une nouvelle méthode en classification automatique et reconnaissance des formes : la méthode des nuées dynamiques », Revue de Statistique Appliquée, vol. XIX, no
2, 1971, p. 19-33.
[DOU 01] DOUCETA., GANÇARSKIS., « Bases de données et Internet, Modèles, Langages
et Système », chapitre Entrepôts de données et bases de données multidimensionnelles,
Hermes- Lavoisier - Sous la direction de A. Doucet et G. Jomier, 2001.
[ESP 95] ESPIÉS., « Multi-actor Parallel Architecture for Traffic Simulation », Proc. of the
2nd Workshop Congress on Intelligent TRansport Systems, vol. IV, Yokohama, Nov. 1995.
[EST 96] ESTERM., KRIEGELH.-P., SANDERJ., XUX., « A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise », Proc. of 2nd Int. Conf. on
Knowledge Discovery and Data Mining (KDD), Portland, Oregon, Aug. 1996, p. 226–231.
[FAL 94] FALOUTSOSC., RANGANATHANM., MANOLOPOULOSY., « Fast Subsequence Matching in Time-Series Databases », Proc. of the 1994 ACM SIGMOD Int. Conf. on Management of Data, Mineapolis, USA, 1994, p. 419–429.
[FAL 04] FALOUTSOSC., « Indexing and Mining Streams. », Proc. of the ACM SIGMOD Int. Conf. on Management of Data, 2004, page 969, Tutorial.
[GOO 00] GOODCHILD M. F., « GIS and Transportation : Status and Challenges. », GeoInformatica, vol. 4, no
2, 2000, p. 127-139, http ://www.ncgia.ucsb.edu/vital/research/pubs/9904hkg1.pdf.
[GUH 98] GUHAS., RASTOGIR., SHIMK., « CURE : An Efficient Clustering Algorithm for Large Databases », Proc. of ACM SIGMOD Int. Conf. on Management of Data, Seatle,
[HAJ 97] HAJSALEMH., ELLOUMIN., « Descriptions des algorithmes de reconstitution des données manquantes », rapport no
3096, June 1997, Rapport de convention INRETS/SIER. [HAJ 00] HAJSALEMH., « PROPAGE : un nouvel algorithme de reconstitution des données
manquantes - description, résultats et spécifications », rapport no
F0027, Nov. 2000, Rap-port de convention INRETS/SIER.
[HAL 01] HALKIDI M., BATISTAKIS Y., VAZIRGIANNIS M., « On Clustering Validation Techniques », Journal of Intelligent Information Systems, vol. 17, no
2-3, 2001, p. 107– 145.
[HEL 95] HELBINGD., « Theoretical foundation of macroscopic traffic models », Physica A :
Statistical and Theoretical Physics, vol. 219, no
3-4, 1995, p. 375–390.
[HOT 33] HOTTELINGH., « Analysis of complex statistical variables into principal compo-nents », Journal of Educational Psychology, vol. 24, 1933, p. 417-441.
[HUG 03] HUGUENEY B., « Représentations symboliques de longues séries temporelles », Thèse de doctorat, Université Paris 6, Jan. 2003.
[INM 92] INMONW.-H., Building the data warehouse, QED Publishing Group, 1992. [JAI 99] JAINA.-K., MURTYM., FLYNNP.-J., « Data Clustering : A Review », ACM
Com-puting Surveys, vol. 31, no
3, 1999, p. 264–323.
[KAL 60] KALMANR., « A new approach to linear filtering and prediction problems »,
Tran-sactions of the ASME–Journal of Basic Engineering, vol. 82, 1960, p. 35–45.
[KAU 90] KAUFMANL., ROUSSEEUWP., Finding Groups in Data : An Introduction to
Clus-ter Analysis, John Wiley and Sons, 1990.
[KEO 98] KEOGHE., PAZZANIM., « An enhanced representation of time series which allows fast and accurate classification clustering and relevance feedback », 4th Int. Conf. on Knowledge Discovery and Data Mining, New York, Aug 1998, p. 239–243.
[KEO 99] KEOGHE., PAZZANIM., « An Indexing Scheme for Fast Similarity Search in Large Time Series Databases », 11th Int. Conf. on Scientific and Statistical Database Management
(SSDBM), Cleveland, OH, USA, 1999, p. 56–67.
[KEO 00] KEOGHE., CHAKRABARTIK., PAZZANIM., MEHROTRAS., « Dimensionality Reduction for Fast Similarity Search in Large Time Series Databases », Knowledge and
Information Systems, vol. 3, no
3, 2000, p. 263–286.
[KEO 01] KEOGHE., CHUS., HARTD., PAZZANIM., « An Online Algorithm for Segmen-ting Time Series », Proc. of the IEEE Int. Conf. on Data Mining (ICDM), San Jose, USA, 2001, p. 289–296.
[LIE 02] LIEUH., « Traffic Flow Theory : A state of the art report - Revised Monograph on Traffic Flow Theory », Transportation Research Board, Washington (article en ligne sur http ://www.tfhrc.gov/its/tft/tft.htm), 2002.
[LIN 03] LIN J., KEOGHE., LONARDI S., CHIUB., « A symbolic representation of time series, with implications for streaming algorithms », Proc. of the 8th ACM SIGMOD
work-shop on Research issues in data mining and knowledge discovery, San Diego, California,
2003, ACM Press, p. 2–11.
[LU 04] LUC., SRIPADAL., SHEKHARS., LIUR., « Transportation Data Visualization and Mining for Emergency Management », International Journal of Critical Infrastructures
(Inderscience), vol. à paraitre, 2004, http
[MCQ 67] MCQUEENJ., « Some methods for classification and analysis of multivariate ob-servations », Proc. of 5th Berkeley Symp. on Math. Statistics and Probability, Berkeley,
CA : University of California Press, 1967, p. 281– 298.
[MIL 01] MILLERH., SHAWS., Geographic Information Systems for Transportation :
Prin-ciples and Applications, New York : Oxford University Press, 2001.
[NG 94] NGR.-T., HAN J., « Efficient and Effective Clustering Methods for Spatial Data Mining », 20th Int. Conf. on Very Large DataBases (VLDB), Santiago, Chile, Sept. 1994, p. 144-155.
[NII 01] NIITTYMÄKIJ., PURSULAM., « The 11th Mini-EURO conference : Artificial intelli-gence on transportation systems and science », European Journal of Operational Research, vol. 113, no
2, 2001, p. 229–231.
[PAP 01] PAPADIAS D., KALNIS P., ZHANG J., TAO Y., « Efficient OLAP Opera-tions in Spatial Data Warehouses », Proc. of the Int. Symposium in Spa-tial and Temporal Databases (SSTD’01), Redondo Beach, CA, 2001, p. 443–459, www.comp.nus.edu.sg/∼kalnis/sstd01.pdf.
[PAP 02] PAPADIASD., TAOY., KALNISP., ZHANG J., « Indexing Spatio-Temporal Data Warehouses », Proc. of the IEEE International Conference on Data Engineering (IC-DE’02), San Jose, 2002, p. 166–175, www.comp.nus.edu.sg/∼kalnis/icde02.pdf.
[PAR 00] PARK S., CHUW.-W., YOONJ., HSU C., « Efficient Searches for Similar Sub-sequences of Different Lengths in Sequence Databases », 16th IEEE Int. Conf. on Data
Engineering (ICDE’00), San Diego, CA, USA, Feb. 2000, p. 23–32.
[PEA 01] PEARSONK., « On lines and planes of closest fit to systems of points in space »,
Philosophical Magazine, vol. 2, no
11, 1901, p. 559-572.
[PRA 04] PRASHERS., ZHOUX., « Multiresolution Amalgamation : Dynamic Spatial Data Cube Generation », Fifteenth Australasian Database Conference, Dunedin, New Zealand, 2004.
[RAF 99] RAFIEID., « On Similarity-Based Queries for Time Series Data », 15th Int. Conf.
on Data Engineering (ICDE), Sydney, Australia, Mar. 1999.
[RAL 00] RALSTONB., « GIS and ITS Traffic Assignment : Issues in Dynamic User-Optimal Assignments », GeoInformatica, vol. 4, no
2, 2000, p. 231–243.
[RAO 03] RAOF., ZHANGL., YUX., LIY., CHENY., « Spatial hierarchy and OLAP-favored search in spatial data warehouse », Proc. of the 6th ACM international workshop on Data
warehousing and OLAP, New Orleans, Louisiana, USA, 2003, p. 48–55.
[RIG 02] RIGAUXP., SCHOLLM., VOISARDA., Spatial Databases With Application to GIS, Morgan Kaufmann Pub., 2002.
[RIV 01] RIVEST S., BÉDARD Y., MARCHAND P., « Towards better support for spatial decision-making : defining the characteristics of spatial on-line analytical processing (SO-LAP) », Geomatica, the journal of the Canadian Institute of Geomatics, vol. 55, 2001, p. 539–555.
[SCE 94] SCEMAMAG., « Artificial Intelligence Applications to Traffic Engineering », chapitre CLAIRE : a contextfree AIbased supervisor for traffic control, VNU Science Press -M. Bielli, G. Ambrosino and -M. Boero (Eds), 1994, ISBN 90-6764-171-5.
[SCE 00] SCEMAMAG., BLAQUIÈREA., OLIVEROP., « CLAIRE++ Observatory : a new tool to know and assess congestion on road networks », 7th World Congress on Intelligent
[SCE 04] SCEMAMAG., CARLESO., « Claire-SITI, Public road Transport Network Mana-gement Control : a Unified Approach », Proc. of 12th IEE Int. Conf. on Road Transport
Information & Control (RTIC’04), London (UK), April 2004.
[SCH 98] SCHETTINIF., « Fusion de données pour la surveillance du trafic et de l’informa-tion », Thèse de Doctorat - spécialité automatique et informatique industrielle, Ecole Na-tionale Supérieure de l’Aéronautique et de l’Espace, Juin 1998.
[SCH 01] SCHOLLM., « Bases de données et internet - Modèles, langages et système », cha-pitre Bases de données géographiques, p. 181–212, Hermes- Lavoisier - Sous la direction de A. Doucet et G. Jomier, 2001.
[SHE 02] SHEKHARS., LUC., LIUR., ZHANGP., « CubeView : A System for Traffic Data Visualization », Proc. of the Fifth IEEE International Conference on Intelligent
Transpor-tation Systems, 2002, http ://europa.nvc.cs.vt.edu/∼ctlu/Publication/its02.pdf.
[Syt] « SYTADIN (SYnoptique de TrAfic De l’Ile de fraNce) - Direction Régionale de l’Equi-pement - Ile-de-France », http ://www.sytadin.tm.fr/.
[THI 00] THILL J., « Geographic information systems for transportation in perspective »,
Transportation Research Part C : Emerging Technologies, vol. 8, no
1-6, 2000, p. 3–12. [WAR 52] WARDROPJ., « Some theorical aspects of road traffic research », Proc. of
Institu-tion of Civil Engineers, II(1), 1952, p. 325–378.
[WU 00] WUY.-L., AGRAWALD., ELABBADIA., « A Comparison of DFT and DWT based Similarity Search in Time-Series Databases », Proc. of the 9th Int. Conf. on Information
and knowledge management, McLean, Virginia, USA, 2000, p. 488–495.
[YI 00] YIB., FALOUTSOSC., « Fast Time Sequence Indexing for Arbitrary Lp Norms »,
26th Int. Conf. on Very Large Data Bases (VLDB), Cairo, Egypt, 2000, p. 10–14.
[ZHA 96] ZHANGT., RAMAKRISHNANR., LIVNYM., « BIRCH : An Efficient Data Cluste-ring Method for Very Large Databases », Proc. of ACM SIGMOD Int. Conf. on