Knowledge Continuous Integration Process (K-CIP)
Texte intégral
Figure

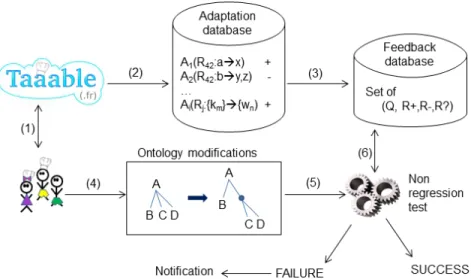

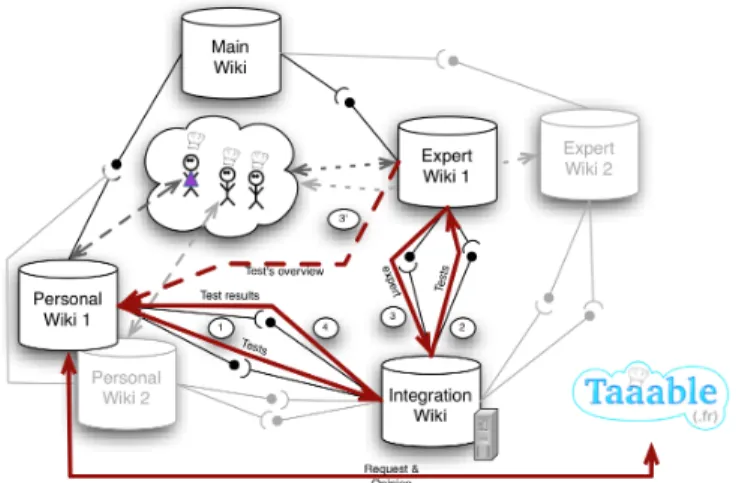
Documents relatifs
The paper “Continuous Integration, Delivery, and Deployment: A Systematic Review on Approaches, Tools, Challenges, and Practices” does a great job in explaining tools, approaches,
Some gaps in the research topic investigated can be pointed out: (i) the lack of systematic approaches for guiding integration at the process layer; (ii) task ontologies
To make sense of the intricate relationships between tasks, data and algorithms at different stages of the data mining process, our meta-miner relies on extensive background
A central task in the Semantic Web effort is the annotation of data and documents with appropriate semantic information (i.e. knowledge markup or ontology population) derived from
Moreover, the practical aspects of propositional knowledge in the intersubjective sense have been discussed by Brandom [2], who adopted Lewis’ idea of score- keeping referring
Thus, in this event design support application we can see clearly the need for effective integration of different ontologies, and how what ontologies are needed and how they should
Having in mind that IT technologies change every 5 years, during his professional career he may face such changes 8 times. Simple calculation allows to conclude, that
Other taxonomies or standards such as JACHO patient safety event taxonomy [9], National coordinating council for medication error reporting and prevention (NCC MERP)’s taxonomy
