Optimising integrated inventory policy for perishable items in a multi-stage supply chain
Texte intégral
Figure

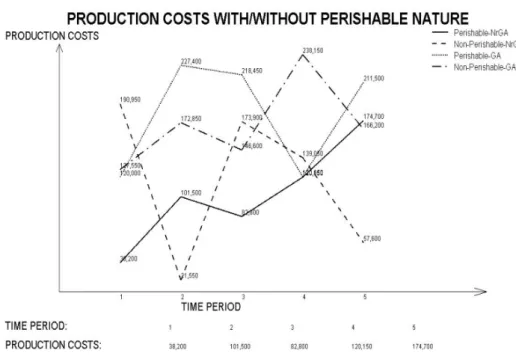
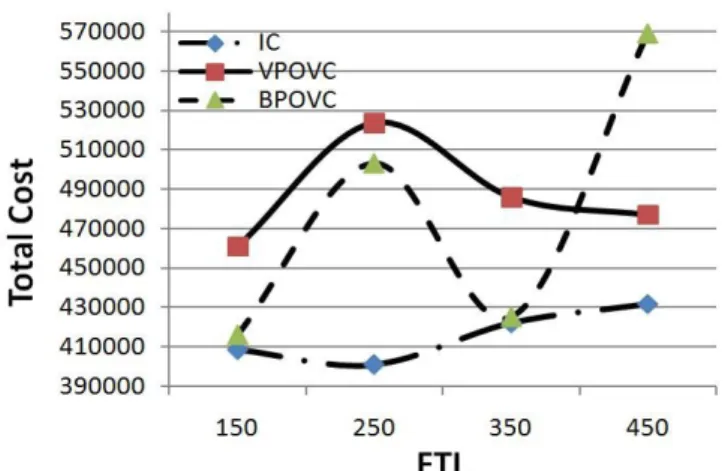

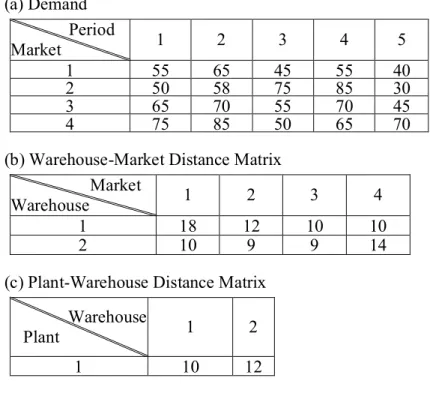
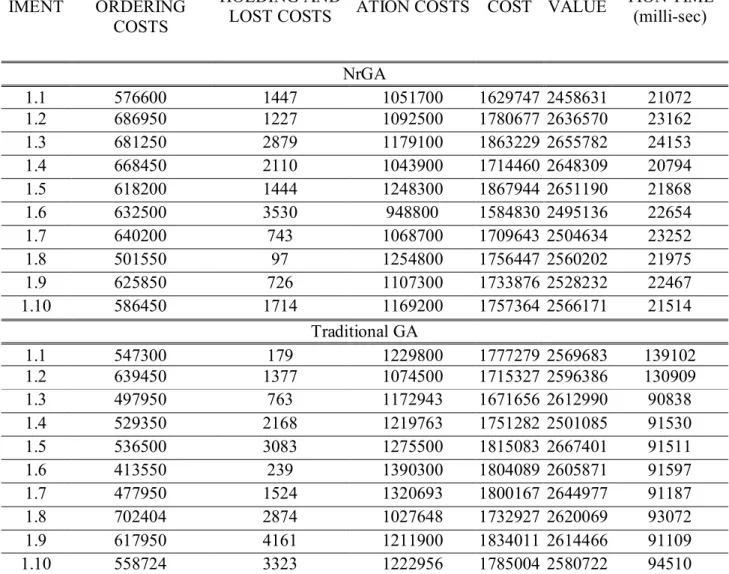
Documents relatifs
In this paper, we focus on a multi objective formalization of a supply chain (SC) in agro-alimentary sector taking into account many particular constraints like
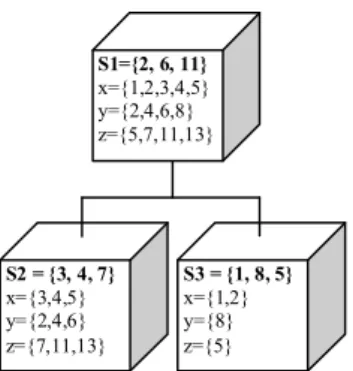
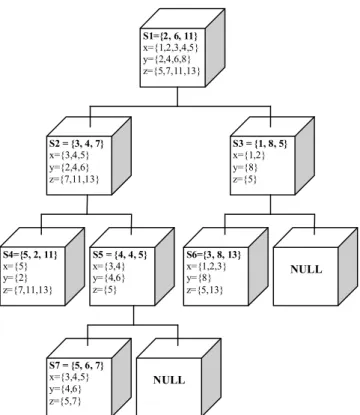
In this specific scenario, only the agents at the first and the second level of the tree decide to organize a supply chain and, therefore, they use the proposed decision network
Méthodologie de déploiement du supply chain management, Modélisation et pilotage des processus, Evaluation de la performance, Gestion industrielle collaborative. Trois
This system must also coordinate decision-making activities with the other SSCs in the supply chain in order to optimize the product flow and to achieve the overall objectives.. At
Morimont, L, Bouvy, C, Dogne, J-M & Douxfils, J 2019, 'Validation of an original ETP-based APC resistance assay for the evaluation of prothrombotic states', ISTH 2019 : The
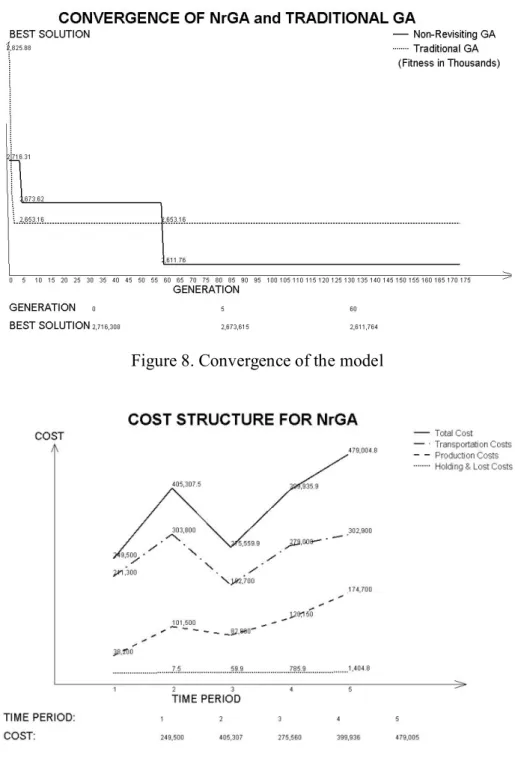
The good agreement of the modelled results with the observed data supports the hypothesis of two remanence ac- quisition processes to be involved in the loess sediments of the cen-
Contracts with NEVC/ customers Rules of game with partners Internal constraints: - Level of stock - Management policies - Capacity … Fixed Purchases Real purchasing Proposed
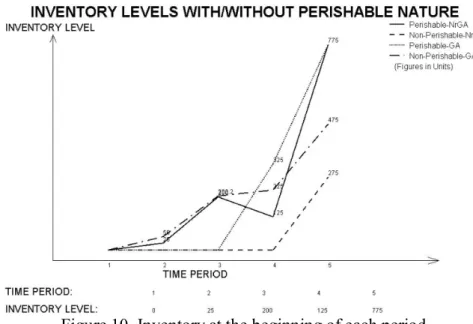
The contributions which have value for the literature of perishable inventory control, are the in-depth understandings of the quality deterioration of perishable items [4; 5].
