Transformations de graphes pour la modélisation géométrique à base topologique
Texte intégral
Figure
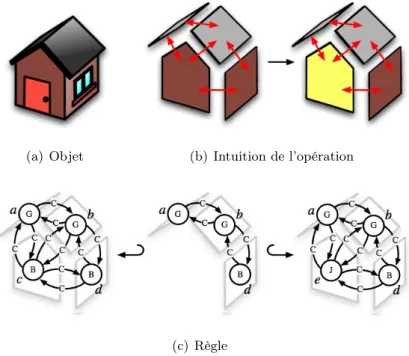
![Figure 1.11 – Simulation de l’appareil de Golgi par transformation de graphes C’est ce que Mathieu Proudret réalise en utilisant les transformation de graphes pour définir les opérations topologiques [Poudret 2008, Poudret 2009]](https://thumb-eu.123doks.com/thumbv2/123doknet/8042532.269619/15.892.189.681.389.593/simulation-appareil-transformation-proudret-utilisant-transformation-opérations-topologiques.webp)

Outline
Documents relatifs
Les strat´ egies de recherche peuvent aussi ˆ etre sp´ e- cifi´ ees d´ eclarativement dans Rules2CP, ainsi que des heuristiques statiques et dynamiques d´ efinies comme des ordres
Ainsi, sur la base d’une analyse préliminaire des usages traditionnels des diagrammes UML en génie logiciel comme en génie éducatif, nous avons retenu l’utilisation des
Puisqu’il n’est pas possible de stocker tous ces photons en mémoire, nous avons donc choisi de fixer une taille maximale N tmp pour chaque tableau temporaire en essayant de
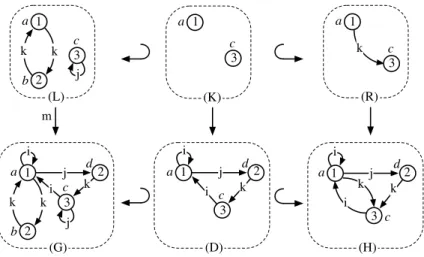
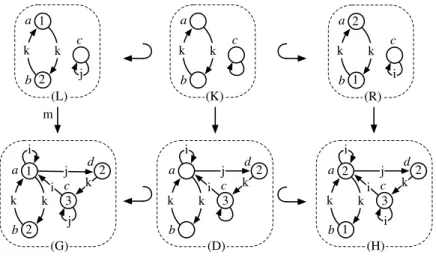
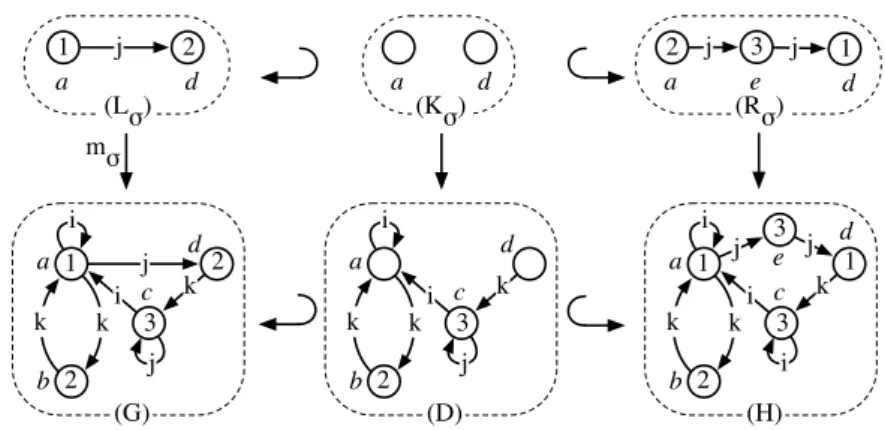
Les différents modèles de l’appareil de Golgi introduits dans la section 5.2 s’inscrivent dans le cadre des (SD) 2. Dans chacun des modèles, la structure est dynamique. Par
De plus, le langage est générique car il permet de définir des opérations géo- métriques pour toute dimension topologique et tout plongement.. Une fois décrites sous forme de
Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2007.. Classification and
La VUE est l’interface. C’est une instance d’une classe graphique. Le CONTROLEUR est une instance d’une classe implémentant les Listeners nécessaires ; on appellera cette
Portée d’une variable : une variable ne peut être utilisée qu’entre la ligne où elle est déclarée et la fin du bloc (ou du fichier) dans lequel elle est déclarée. Variables
