Flexible time series models for subjective distribution estimation with monetary policy in view
Texte intégral
Figure

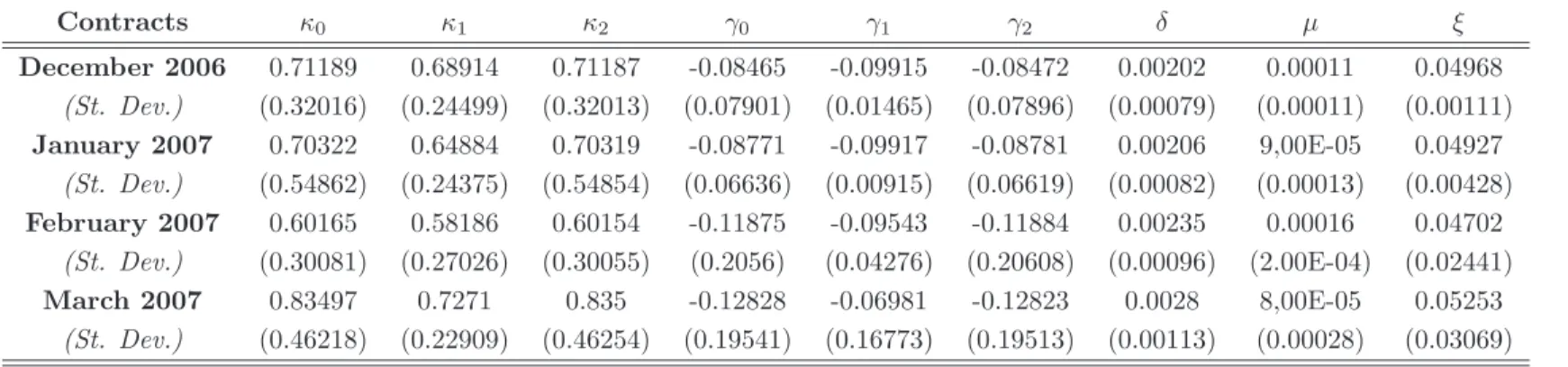
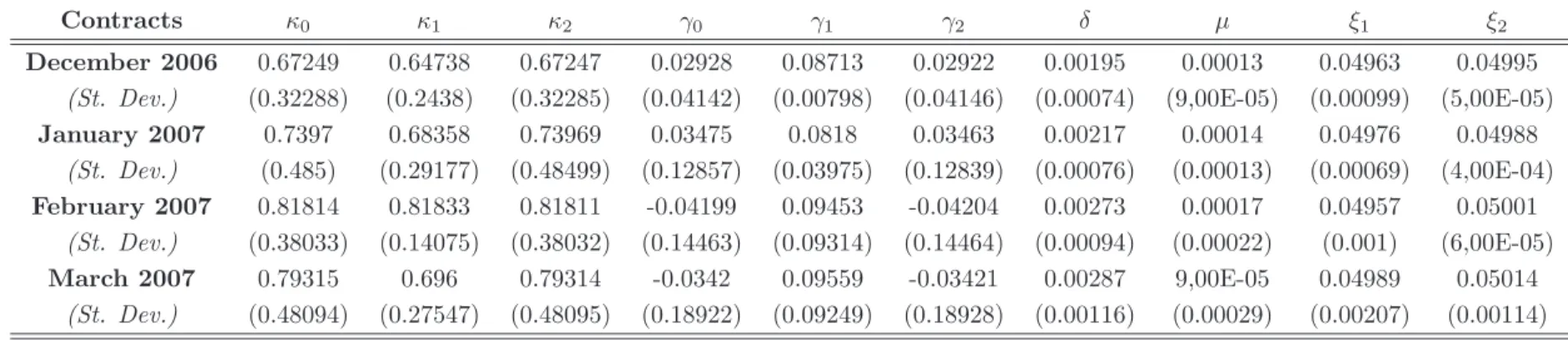

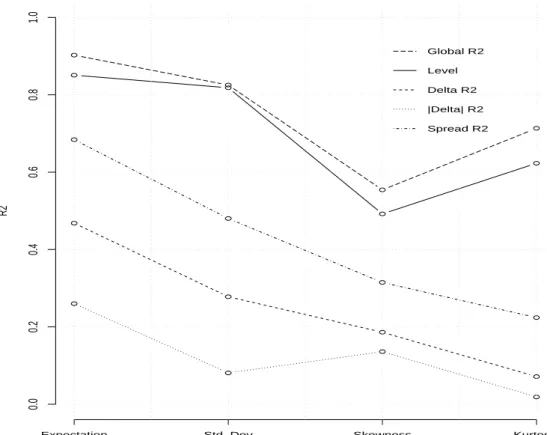
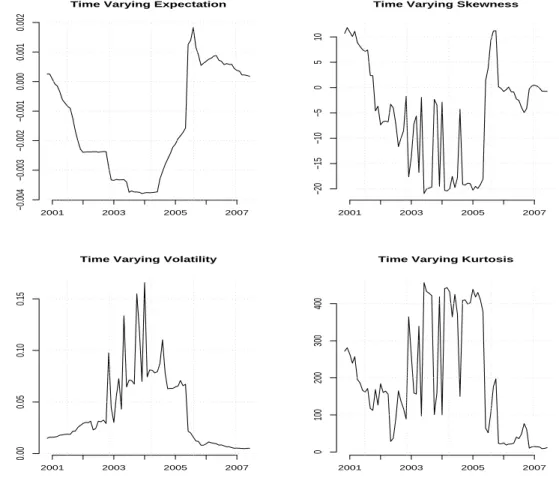
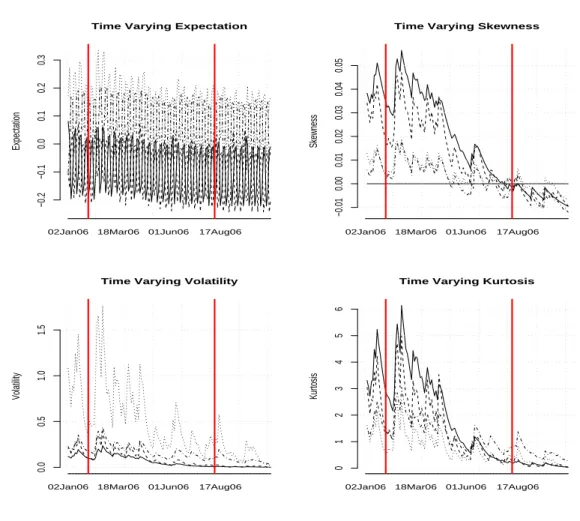
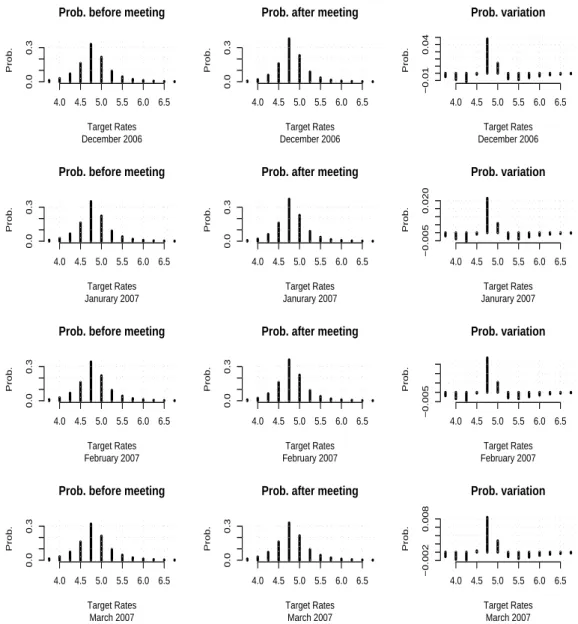
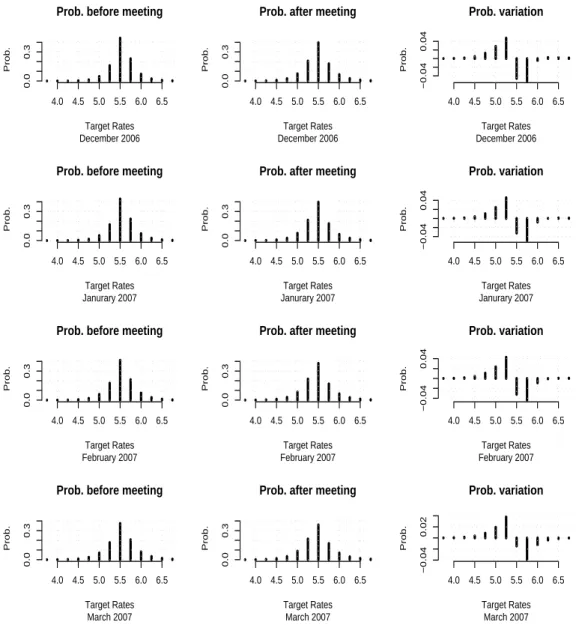
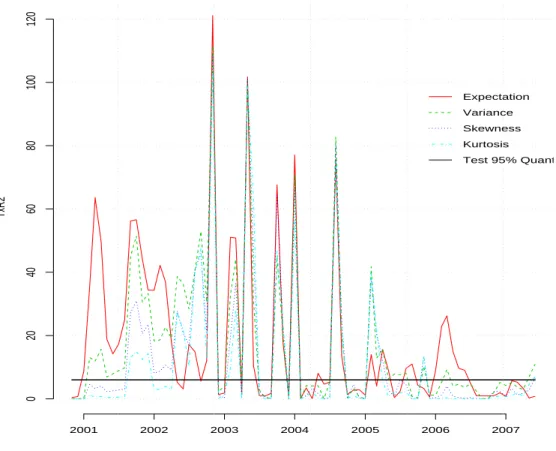
Documents relatifs
The importance of the exchange rate to monetary policy is reflected in large academic and policy-related literatures on the topic. We contribute to this literature by addressing
In a regression model with univariate censored responses, a new estimator of the joint distribution function of the covariates and response is proposed, under the assumption that
104 Niggli/Gfeller, in: Basler Kommentar Strafrecht I (Anm.. direkten Schluss zu, ob sich eine juristische Person oder ein sonstiger Verband auch tatsächlich „strafbar“ machen kann
The empirical tractability of the model was shown by simultaneously estimating the coefficient of relative risk aversion and the subjective time discount rate, using a sample of
2) Local CRB: In [23 ], we calculate the appropriate CRBs, denoted by crb , for local-model parameters (8) of short- time signals whose amplitudes and frequencies are modeled as
The theories concluding with the end of a Central Bank and the imposition of market law to money (free banking, Hayek) are not established. Moreover, the rational expectations,
[2]R.R Hall, Sets of multiples, Cambridge Tracts in Mathematics 118, Cambridge University Press, Cambridge
If the intention of the central bank is to maximize actual output growth, then it has to be credibly committed to a strict inflation targeting rule, and to take the MOGIR
