Two consistent estimators for the Skew Brownian motion
Texte intégral
Figure


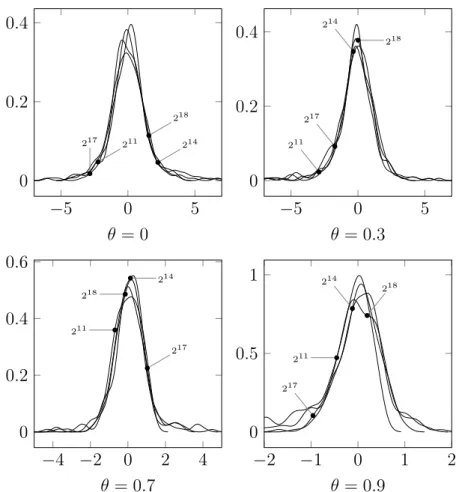
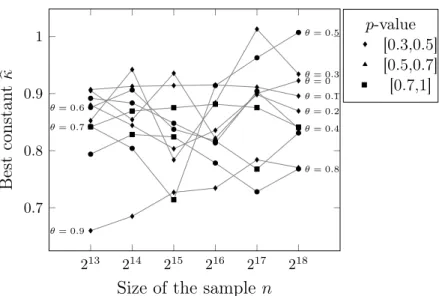
Documents relatifs
Brownian Motion Exercises..
Key words: H¨ older continuity, fractional Brownian motion, Skorohod integrals, Gaussian sobolev spaces, rough path, distributions.. AMS Subject classification (2000): 60G15,
In order to treat the simpler case of a given piecewise constant coefficient ¯ β, we are inspired by a construction for the classical skew Brownian motion with constant parameter
In this section we apply the results from the previous sections to find an expression for the joint distribution of the maximum increase and the maximum decrease of Brownian motion
correlations. The hitting criteria then yield lower bounds on Hausdorff dimension. This refines previous work of Khoshnevisan, Xiao and the second author, that required
- There exists a descending martingale which does not embed in standard Brownian motion (Bt, Ft) by means of standard stopping.. times with respect to
When the Itˆo process is observed without measurement noise, the posterior distribution given the observations x 0WN is.. ; x 0WN /d is the marginal distribution of the data
We obtain a decomposition in distribution of the sub-fractional Brownian motion as a sum of independent fractional Brownian motion and a centered Gaussian pro- cess with
