A first-order primal-dual algorithm for convex problems with applications to imaging
Texte intégral
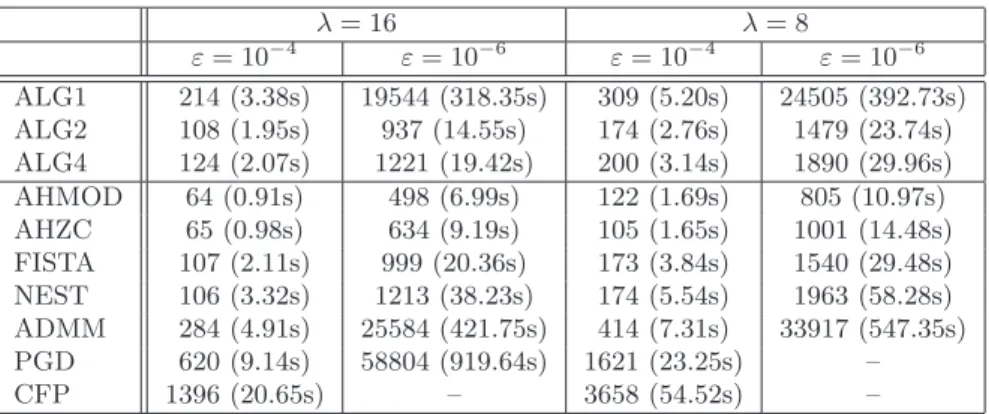
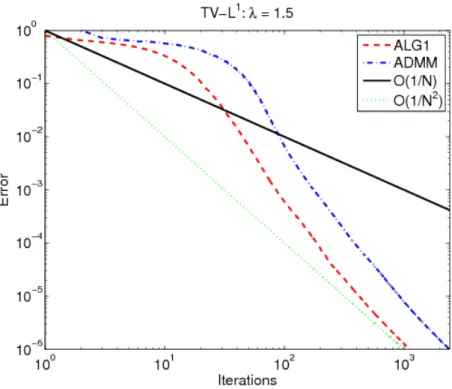
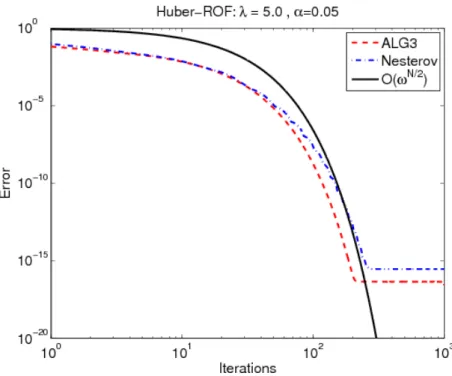
Figure







Documents relatifs
In Section 2, we start by recalling briefly some notions on HJ equations, and we present the maximization problem following [12] as well as related duality results in
A few questions remain open for the future: A very practical one is whether one can use the idea of nested algorithms to (heuristically) speed up the con- vergence of real life
klimeschiella were received at Riverside from the ARS-USDA Biological Control of Weeds Laboratory, Albany, Calif., on 14 April 1977.. These specimens were collected from a culture
This paper presents for the first time a relatively generic framework for multiple reflection filtering with (i ) a noise prior, (ii ) sparsity constraints on signal frame
« La sécurité alimentaire existe lorsque tous les êtres humains ont, à tout moment, un accès phy- sique et économique à une nourriture suffisante, saine et nutritive leur
3D Coulomb friction, contact problems, dual Lagrange multipliers, inexact primal- dual active set strategy, semismooth Newton methods, nonlinear multigrid method.. Solving
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
r´ eduit le couplage d’un facteur 10), on n’observe plus nettement sur la Fig. IV.13 .a, une diminution d’intensit´ e pour une fr´ equence de modulation proche de f m.
