Dynamic Active Area Clustering with Inertial Information for Fingerprinting based Indoor Localization Systems
Texte intégral
Figure

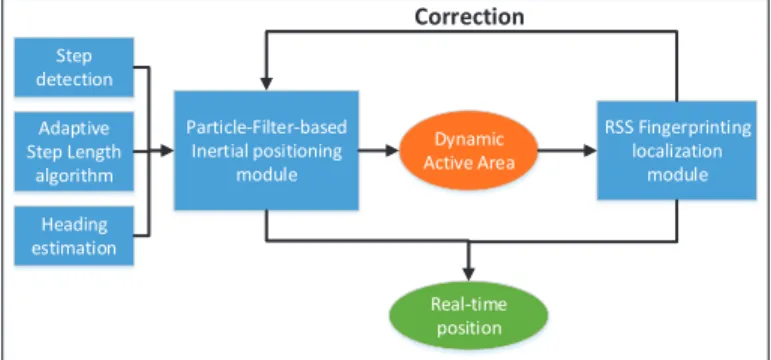
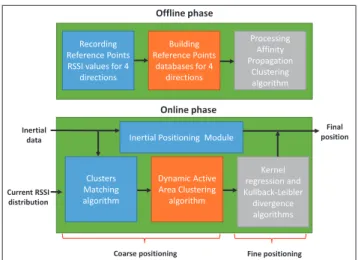

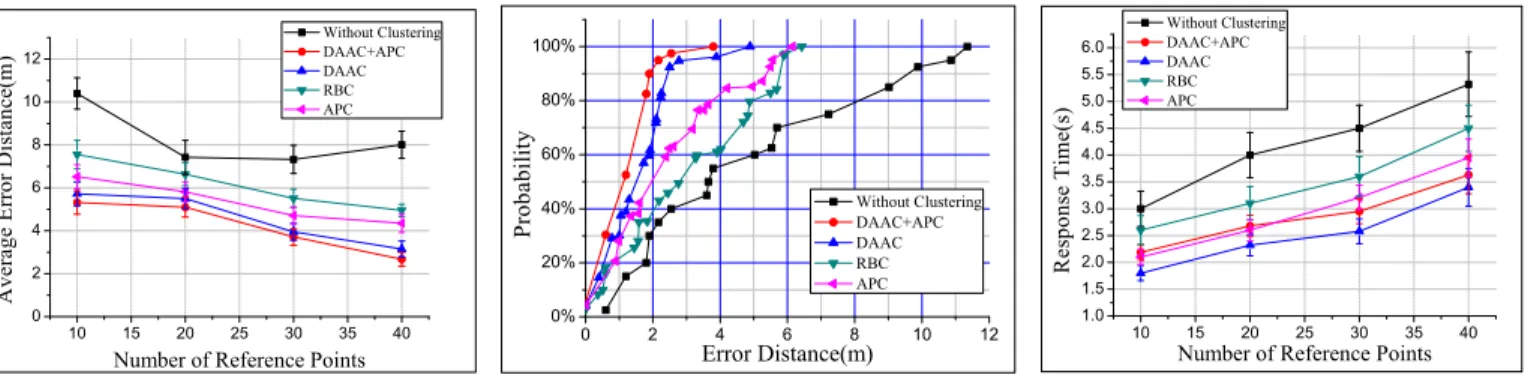
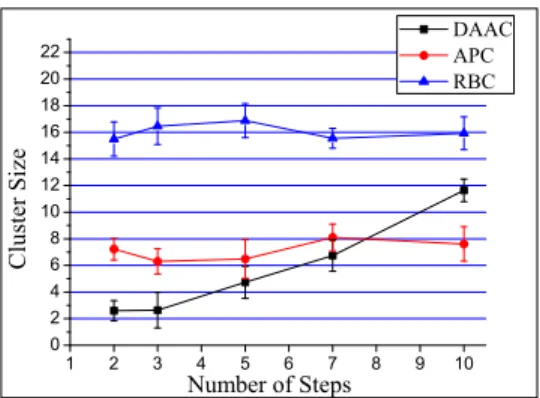
Documents relatifs
When the number of students is large, an optimal static 6-clustering will isolate four groups and split one in two halves in every snapshots ; whereas the optimal dynamic
We first sum- marize related work, and then we give a brief domain-independent overview of compression- based clustering: the ideal distance metric based on Kolmogorov complexity
In the online phase, when getting a RSSI measurement with an unknown location at an unknown floor, we use a complete parallel network to determine the floor and then to estimate
The method converts environmental ultrasounds into spectrograms and builds a non- linear regression model based on the spectrograms using a convolutional neural network to
In this paper, a proposal which couples a dynamic clustering method with an on-line trend extraction algorithm that works incrementally on the incoming data is presented.. The
between samples (to cluster) or between samples and clusters so that samples/clusters are gathered according to increasing distance order. Besides, in the perspective of
Abstract – This paper presents a new Time-frequency interleaving in a Multi-code Multicarrier CDMA MCMC-CDMA system, which allows two-dimensional spreading in both time and
Celui-ci doit permettre plusieurs traitements et parmi ceux-ci, on peut citer: - la création d’images, - la capture d’images directement à partir d’un scanner ou d’une autre
![[PDF] lLangage de programmation orienté web TP | Cours Informatique](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)