A linear-space algorithm for distance preserving graph embedding
Texte intégral
Figure


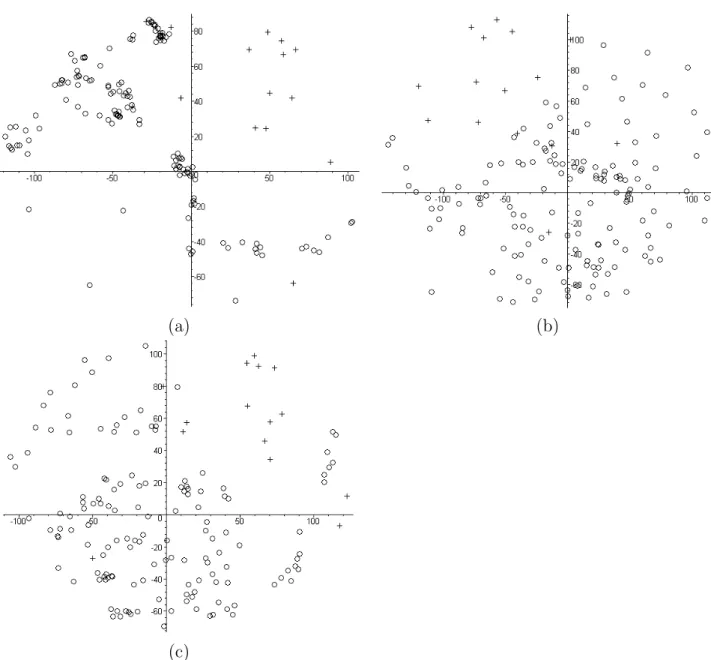
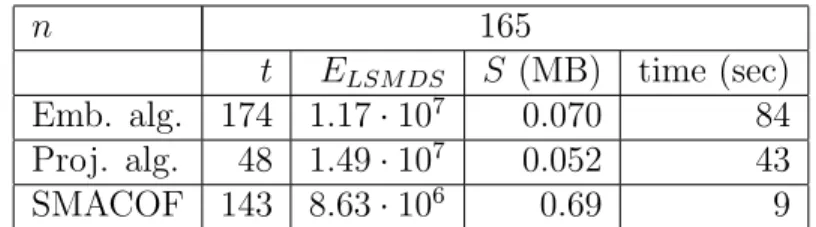



Documents relatifs
In this work, we will examine some already existing algorithms and will present a Two-Phase Algorithm that will combine a novel search algorithm, termed the Density Search Algorithm
Five values of N were chosen: -1, 100, 250, 500 and 1000, where N =-1 represents the decomposition of the first floor in the search tree with all possible branches, N = 100 and
Five values of N were chosen: -1, 100, 250, 500 and 1000, where N =-1 represents the de- composition of the first floor in the search tree with all possible branches, N = 100 and
If a chemist wants to search a database for a molecule similar to a query molecule using this similarity score, he may find many molecules with the same (minimal) RMSD.. Among
For each method, we obtain formulas that provide bounds on the total number of vector additions in F k b required to perform any of the following three computations, given a vector S
We have proposed an iterative deconvolution approach and its embedding in a fine-tuned CNN where each feature map corresponds to a step of an ADMM algorithm, demonstrating
Methods to learn representations that encode structure in- formation about the graph can be categorized to be graph- kernel based or graph neural network (GNN) based2. Inter-
For this application, the template functions obtained by the Robust Manifold Estimator based on our algorithm seem to capture the salient features of the sample of hip and knee
