support de cours
Web Dynamique – Web Mapping
cours n°1
Introduction
au fonctionnement du web
Emmanuel Fritsch
1 Préambules
1.1 Objectifs du cours
L’objectif de ce cours est de vous amener très rapidement à la capacité de programmer des pages web dynamiques simples. Le cours se compose d’une partie théorique, qui présente les principes généraux du web, et d’une série de travaux pratiques progressifs, qui permettent de découvrir pas à pas les différentes composantes du web dynamique.
Ce cours constitue par ailleurs un pré requis du cours de web mapping. Nous porterons donc un intérêt particulier à l’affichage d’images.
1.2 Organisation
Ce cours comporte plusieurs documents :
- le présent polycopié, cours n°1, introduction essentiellement théorique, - le cours n°2, centré sur le poste client (HTML, CSS et javascript),
- le cours n°3, qui vous apprendra à générer des pages web dynamiques avec PHP, - des TP suivis permettant de pratiquer et d’étendre les différentes notions exposées en
cours.
1.3 Comment utiliser ce cours
Ces documents sont conçus pour permettre plusieurs niveaux de lecture. Vous pouvez vous contenter d’une lecture purement théorique, au cours de laquelle vous vous contenterez de lire le texte normal. Le texte normal représente le contenu contractuel du cours. Ce paragraphe est un exemple de texte normal.
Pour réviser le cours, ou bien pour vous en faire une idée générale, vous pouvez vous contenter d’un survol des paragraphes importants, mis en valeur de la manière suivante :
Ceci est un paragraphe important.
Les points importants vous donneront des informations de caractère général, nécessaires à toute personne voulant comprendre le fonctionnement du web dynamique.
Pour une acquisition des techniques présentées dans ce cours, nous vous demandons d’effectuer les exercices progressifs référencés ici. Les exercices les plus simples seront inclus dans le texte du cours. Les TP un peu plus complexes seront indiqués par un renvoi aux TP. Le paragraphe ci-dessous est un exemple d’annotation. Les annotations contiennent des informations inutiles à l’acquisition directe des compétences du cours, mais permettant parfois d’aller plus loin.
Ces annotations regroupent les digressions, les informations touchant à la culture générale, les idées du professeur, ses doutes et ses humeurs. Les annotations peuvent servir aussi à présenter un concept important mais développé à la fin du cours (par exemple AJAX). Le contenu du cours est ainsi hiérarchisé comme une araignée tisse sa toile : quelques fils de départ donnent la forme globale. Cette structure est rapidement
complétée d’un maillage grossier. Progressivement, les larges mailles se remplissent d’un nouveau tissage, qui les sépare en mailles plus fines.
1.4 Prérequis du cours
Ce cours s’adresse à des étudiants ayant au moins une petite connaissance de la programmation. Vous devez savoir ce qu’est une variable, et être capable de mettre en œuvre une boucle simple.
Il s’agit d’une initiation ; aucune connaissance du web n’est donc requise, en dehors bien sûr de celle que doit avoir un utilisateur habituel d’Internet. Pour faire les exercices, vous devez aussi savoir utiliser un éditeur de texte, comme Notepad, ou le Bloc-notes de Windows, ou mieux encore : Notepad++.
Avant de parler du web dynamique, nous décrirons les techniques de base du web statique. Dynamique ou statique, le fonctionnement du web repose sur des langages et des logiciels variés. Leur découverte en un seul cours vous demandera un peu d’agilité intellectuelle.
La difficulté principale est de bien identifier, lorsque vous traitez une opération, sur quel logiciel, ou sur quel langage vous êtes en train de travailler.
Pour mettre en œuvre les exercices et les travaux pratiques, vous devez naturellement disposer d’un ordinateur. Certains exercices et TP requièrent que vous disposiez des droits d’administrateurs, pour installer et configurer le serveur. Si vous ne disposez pas d’un serveur, vous pouvez utiliser les pages perso de certains fournisseurs d’accès, comme free.fr ou freesurf.fr, mais pour des raisons de commodités, je vous recommande d’installer au moins easyPHP sur votre ordinateur.
2 Le Web Statique
2.1
l’architecture client-serveur
2.1.1 clients et serveurs
Lorsqu’on connecte les ordinateurs en réseau, il devient intéressant de concentrer certaines ressources (c'est-à-dire des informations et des programmes) sur un seul ordinateur, et de permettre aux autres ordinateurs de se servir de ces ressources uniquement lorsqu’ils en ont besoin. C’est l’architecture client-serveur.
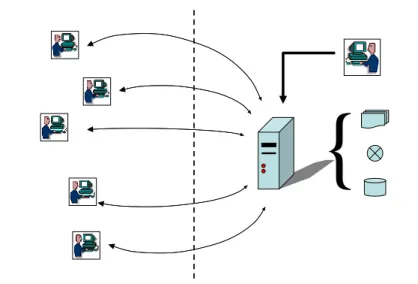
Le serveur, c’est l’ordinateur sur lequel se trouve une ressource.
Le client, c’est l’ordinateur qui a le droit d’accès à la ressource sur le serveur
?
{
figure 1 - schéma de l’architecture client-serveur. Plusieurs clients partagent les fichiers, les applications et les bases de données placées en partage sur un serveur. Le trait pointillé entre le serveur et les client illustre le fait qu’un client et un serveur peuvent être très éloignés l’un de l’autre, par exemple lorsqu’on utilise Internet. A côté des clients, le serveur possède un administrateur, qui l’alimente en données, en programme et en base de données.
Les avantages de l’architecture client-serveur sont :
o une économie d’espace mémoire (tous les postes clients vont chercher l’information
en fonction de leurs besoins, et ne doivent pas la stocker durablement)
o une garantie de cohérence (à chaque instant, le serveur constitue un référentiel unique, identique pour tous les clients, alors qu’une duplication sur chaque poste client entraîne généralement une divergence entre les différentes versions, et une perte du référentiel commun). Cette garantie de cohérence est particulièrement souhaitable lorsque l’information subit des mises à jour.
o Une maîtrise du service (le gestionnaire du serveur contrôle ce que les programmes clients peuvent faire ou ne pas faire sur le serveur).
Le premier avantage est de nature physique. Les deux autres touchent directement à l’organisation du travail et des processus.
Lorsqu’on parle de « client » et de « serveur », il peut s’agir à la fois de l’ordinateur et du programme qui tourne sur cet ordinateur.
Dans la suite de ce cours, « client » et « serveur » désigneront les programmes. Les ordinateurs seront explicitement désignés par « ordinateur client » et « ordinateur serveur ».
2.1.2 application à Internet
Internet est l’exemple extrême d’architecture client-serveur : chaque serveur est potentiellement accessible par des millions de clients. On peut dire que le Web illustre de manière aiguë les avantages de l’architecture client-serveur : chacun est libre de décider de ce qu’il met en ligne, chacun possède en permanence le droit d’accéder à un volume de données plus d’un million de fois supérieur à ses capacités de stockage personnelles.
Sur le web,
o le serveur s’appelle « serveur internet ». Le programme le plus utilisé est Apache.
o le client s’appelle navigateur, (ou bien browser, ou butineur). Les programmes les plus
utilisés sont Internet Explorer et Firefox, puis Opera.
Dans le cadre de ce cours, nous utiliserons le serveur Apache, et le navigateur FireFox. Pour la programmation de site web, il est recommandé de tester chaque page avec Internet Explorer et FireFox.
2.2 les protocoles
2.2.1 Qu’est-ce qu’un protocole ?
Un protocole est une convention de communication entre deux ordinateurs. Lorsque deux ordinateurs communiquent entre eux, ils utilisent à chaque fois plusieurs protocoles en même temps, et ces protocoles sont inclus les uns dans les autres.
Le dialogue entre le client et le serveur repose sur toute une série de protocoles imbriqués les uns dans les autres.
J’ai longtemps eu du mal à comprendre cette histoire de protocoles imbriqués. Le plus simple pour le comprendre est de se représenter le protocole comme un langage. Lorsque vous écrivez un message à un autre être humain, vous tracez des signes sur du papier. Le fait de tracer des signes au stylo ou à la plume sur un post-it que l’on colle sur le frigo, c’est le premier niveau du protocole. En informatique, on parle de protocole physique, car nous sommes ici au niveau du signal physique. Pour le post-it collé sur le frigo, cela signifie par exemple « liste de courses ».
Notre message est ensuite composé de lettres. On peut dire que la convention alphabétique est le premier protocole logique de votre communication. D’autres humains utilisent d’autres protocoles, par exemple les idéogrammes ou les syllabaires.
Ensuite, les lettres sont regroupées en mots. Chaque mot porte un sens : c’est le lexique. La convention lexicale est le deuxième protocole de votre communication. Les mots sont eux-mêmes regroupés en phrases, selon les règles de la grammaire : la grammaire de la phrase est le troisième protocole de la communication. Avec les
mêmes mots, vous pouvez utiliser des grammaires différentes. Par exemple, si Adeline laisse à Barnabé une liste de courses sur un post-it, elle utilise une énumération à la place de la grammaire française.
L’analogie de l’emboîtement des protocoles ne doit pas être poussée trop loin. La grande différence, en particulier, c’est que pour écrire un message, Adeline doit maîtriser tous les protocoles. Au contraire, dans un programme informatique, les protocoles sont encapsulés les uns dans les autres, et un programme qui utilise le protocole de plus haut niveau ne doit pas utiliser les protocoles de niveaux inférieurs (ou en tout cas ne devrait pas les utiliser). Le protocole de plus haut niveau est là pour masquer, ou "encapsuler" ceux de niveau inférieur.
2.2.2 Les protocoles d’Internet
2.2.2.1 TCP/IP
Le protocole de base qui structure Internet (pas seulement le web, mais aussi les autres composantes d’Internet, comme le FTP et le mail) s’appelle TCP/IP. De fait, il s’agit déjà de deux protocoles imbriqués : TCP et IP.
TCP/IP permet de transformer les signaux physiques en information numérique. Dans la programmation d’un site web, on utilise un protocole logique qui s’appuie sur TCP/IP, et le navigateur n’a pas connaissance de ce protocole : TCP/IP n’est mentionné ici que pour information, et nous n’en parlerons plus dans la suite du cours.
2.2.2.2 HTTP – le protocole du web
Au dessus de TCP/IP, le web repose sur le protocole HTTP. HTTP est le protocole spécifique du web. HTTP signifie : Hyper-Text Transfert Protocole
HTTP est donc la langue dans laquelle le serveur et le client dialogue.
Pour explorer les arcanes de ce protocole HTTP, je vous conseille de lire l’excellent chapitre 14 du livre sur Java dans la collection O’Reilly. Le livre se trouve à la bibliothèque de l’école. D’autres références sont faciles à trouver sur Internet.
2.3 le serveur
Le serveur joue en premier lieu un rôle de distributeur de fichiers. Autour de ce rôle de serveur de fichiers, il peut rendre diverses sortes de services.
2.3.1 le serveur, un serveur de fichiers
Le rôle du serveur est d’abord d’aller chercher, lorsqu’on lui en fait la requête, le fichier réclamé, puis de le renvoyer au demandeur.
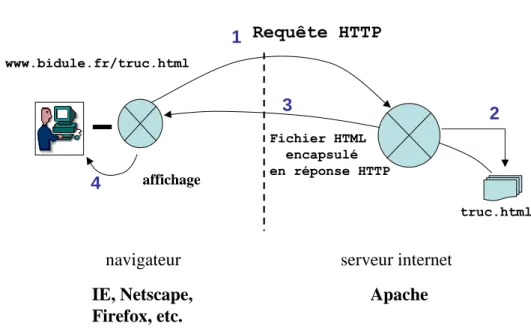
Requête HTTP serveur internet Apache Fichier HTML encapsulé en réponse HTTP www.bidule.fr/truc.html navigateur IE, Netscape, Firefox, etc. affichage truc.html 1 2 3 4
figure 2 -l’itinéraire d’une requête : 1- le navigateur demande un fichier au serveur, 2-le serveur va chercher le fichier dans son système de fichier, 3-le serveur poste le fichier au navigateur, 4- le navigateur reçoit le fichier et l’affiche.
2.3.2 le répertoire racine
Lorsque vous consultez une page internet, vous n’avez accès qu’à une petite partie des fichiers installés sur la machine serveur.
C’est aussi le rôle du serveur de limiter la zone à laquelle les clients peuvent avoir accès.
Cette limitation de la zone accessible depuis l’extérieur est absolument nécessaire pour des raisons de sécurité.
Le répertoire accessible depuis l’extérieur, que nous appellerons le répertoire de la racine web, est défini par l’administrateur. Sur Apache, la configuration de ce répertoire se fait au moyen de l’expression suivante :
DocumentRoot "c:/Apache/visibleWeb"
Cette ligne de configuration est placée dans le fichier qui regroupe la plupart des variables de
truc.html c:\ wwwroot\ Program Files\ apache\ machin\ bidule\
figure 3. Seule une petite partie des répertoires du serveur est accessible depuis Internet.
2.3.3 affichage des dossiers
Sur certains sites internet, lorsqu’on tape un nom de répertoire
(par exemple http://mnibjb.free.fr/exo/)
on voit apparaître le contenu du répertoire, avec tous ces fichiers.
En revanche, lorsque dans la barre d’adresse de mon navigateur, je tape www.ensg.eu, je ne
vois pas le contenu du répertoire racine, mais j’obtiens le même résultat que si je tapais
www.ensg.eu/index.html. De fait les deux adresses pointent sur un seul fichier : index.html.
C’est encore le rôle du serveur que de traiter les requêtes sur les répertoires : le serveur cherche le fichier nommé index.html dans le répertoire. Si un tel fichier s’y trouve, il le renvoie au client. Sinon, il lui renvoie le contenu du répertoire.
En fait, c’est l’administrateur du serveur qui définit les noms possibles pour les fichiers d’index. La configuration de la liste des noms d’index se fait au moyen de la ligne suivante :
DirectoryIndex index.html, index.php, index.php3, pantagruel.php
Avec cette configuration, le serveur teste d’abord s’il existe dans le répertoire un fichier index.html. S’il n’existe pas, il teste ensuite successivement l’existence des fichiers index.php, index.php3, pantagruel.php. Le premier fichier trouvé est renvoyé au client. Si aucun des quatre n’est trouvé, le serveur renvoie le contenu du répertoire.
2.3.4 Les erreurs
Le serveur est aussi responsable de la gestion des erreurs dans la connexion avec le client. Utilisateurs d’Internet, vous avez déjà eu l’occasion de rencontrer l’erreur 404, lorsque le client réclame un fichier que le serveur ne trouve pas. Il existe d’autres erreurs, dont les codes sont spécifiés par HTTP.
C’est le serveur qui génère la page d’erreur, avec son code, et les éventuelles explications.
2.3.5 Conclusion
Le serveur ne joue donc pas seulement un rôle de distributeur : il rend par ailleurs une série de services annexes. Certains de ces services sont fixés par le protocole HTTP. D’autres sont contraints par Apache, ou paramétrés par son administrateur.
Les quelques services listés ci-dessus ne représentent qu’une toute petite partie des services rendus par le serveur.
Parmi les autres services, il y en a un qui est assez important, c’est la gestion du cache. Le cache, c’est une portion de la mémoire de l’ordinateur client qui est réservée au stockage des pages web qu’on a déjà visitées dans le passé. Lorsque vous tapez l’adresse d’un fichier, par exemple www.ensg.ign.fr, votre navigateur regarde si le fichier se trouve dans son cache. Si le fichier demandé est présent, et s’il n’est pas trop vieux, le navigateur décide de ne pas le redemander au serveur. Ainsi, on économise de la bande passante.
La gestion du cache est assurée à la fois par le serveur et par le navigateur. Pour plus de précision sur le cache, reportez vous aux spécifications de HTTP. Pour résoudre un problème technique rapidement, consultez les documentations en ligne de PHP et HTML (fonction header(), tag META). Quelques pistes dans les liens suivants :
- http://www.die.net/musings/page_load_time/
- http://www.commentcamarche.net/forum/affich-28946-gestion-du-cache-du-navigateur
Attention, le cache ne concerne pas seulement la machine client : il peut y avoir un ou plusieurs caches sur la machine serveur, en particulier dans le cadre du Web dynamique. Certaines applications de web dynamique permettent de gérer explicitement le cache (voir par exemple Spip, CartoWeb, etc.), mais cela dépasse le cadre de ce cours.
2.4 le client
2.4.1 le langage HTML
HTML signifie : Hyper Text Mark-up Language, c’est-à-dire langage d’hyper-texte fondé sur des balises.
Qu’est-ce qu’un document d’hyper-texte ? C’est un document qui permet de passer à un autre document lorsqu’on clique sur une zone prévue pour cela et appelée lien hyper-texte. Chaque document peut porter plusieurs liens hyper-texte, ce qui permet à chaque internaute de piloter sa lecture parmi les différents documents qui lui sont accessibles.
HTML est un langage de structuration de document pour la navigation en hyper-texte. La structure du document est codée au moyen des balises.
Qu’est-ce donc qu’une balise ? Le mieux est de prendre un exemple :
<p> Ceci est un paragraphe que je peux remplir de blabla</p>
Explication :
o On commence un paragraphe avec la balise <p>. C’est la balise ouvrante.
o Une balise, c’est tout ce qui se trouve entre < et >.
o On ferme le paragraphe avec la balise </p>. Une balise fermante présente la même
forme qu’une balise ouvrante avec seulement le '/' devant le nom de la balise.
o Entre la balise ouvrante et la balise fermante, nous avons un objet paragraphe. Cet objet paragraphe contient du texte.
C’est ce texte que nous voyons apparaître à l’écran dans le navigateur. Les balises n’apparaissent pas : elles sont là pour donner une structure au document.
Un fichier HTML est constitué de morceaux de textes structurés par des balises. Le navigateur interprète les balises pour donner une mise en page au texte.
Lorsque vous avez un acronyme informatique qui finit par « ML », il y a de fortes chances pour que ce soit un langage à base de balises. Les seules exceptions que je connaisse sont UML (unified modelisation language) et YAML (YAML Ain't Markup Language – acronyme récursif pour un langage de structuration de données qui n’est justement pas un langage à base de balises) ; dans tous les autres cas, ML signifie « mark-up language ».
Exercice 1 :
a. tapez l’exemple précédent dans un éditeur de texte. Enregistrez-le, dans un fichier exercice1.html, puis ouvrez le dans votre navigateur.
b. le langage HTML n’est pas un protocole. Pouvez-vous dire pourquoi ?
Pour en savoir plus, vous pouvez commencer le chapitre « premier pas avec HTML ».
2.4.2 CSS et feuilles de style
Le langage CSS permet de définir des styles que l’on va associer au code HTML. Ces styles permettent de donner une forme homogène à une page HTML, voire à tout un site. On peut modifier ainsi l’aspect de plusieurs pages en changeant simplement une seule feuille de style.
Pour en savoir plus, vous pouvez commencer à lire « premier pas avec CSS ».
2.4.3 l’inclusion d’une image
Comment se passe l’inclusion d’une image dans un document HTML ? Nous allons décrire ce fonctionnement, qui permet d’illustrer le fonctionnement du client et du serveur.
Dans le code HTML, une image est représentée par la balise suivante :
<img src="carte.gif" width="180" height="90" >
Décomposons :
- img : on ouvre un objet image. Comme il n’y a pas de texte dans une image, la balise
fermante est inutile. img, le premier mot de la balise, définit la nature de cette balise :
ici, une image. On dit que c’est le nom de la balise. Tout ce qui suit correspond aux attributs de cette balise.
- src="carte.gif" : le navigateur pourra afficher l’image en allant chercher le fichier
spécifié ici.
- width="180" : largeur,
- height="90" : et hauteur, en pixels, de l’image à l’écran
Ces deux derniers attributs sont optionnels. Si ils sont omis, l’image apparaîtra selon ses dimensions d’origine. Si on met un seul des deux attributs de dimension, le deuxième est recalculé selon les proportions de l’image d’origine. On peut préciser d’autres attributs, par exemple border pour mettre un cadre autour de l’image.
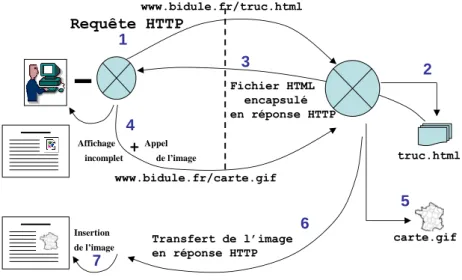
Ce que nous devons noter, c’est que l’image ne se trouve pas stockée dans le code HTML. Ce qu’on trouve dans le code HTML, c’est l’adresse de l’image. Le navigateur charge donc la page en deux temps :
Requête HTTP www.bidule.fr/truc.html Appel de l’image truc.html 1 2 3 4 carte.gif www.bidule.fr/carte.gif Fichier HTML encapsulé en réponse HTTP Affichage incomplet Insertion
de l’image Transfert de l’image
en réponse HTTP
5
7
+
6
figure 4 - Affichage d’une page avec une image. 1- appel de la page HTML. 2- le serveur va chercher le fichier HTML, 3- et l’envoie au client. 4- le client affiche le fichier : comme il y a une image dedans, il réserve la place pour l’image, et il appelle le fichier de cette image sur le serveur. 5- Le serveur attrape l’image, et 6- la renvoie au client. 7- le client reçoit l’image et l’insère dans la page.
2.4.4 - les plug-in
le navigateur ne permet pas de tout faire. Pour étendre les capacités des navigateurs, il est possible de leur brancher des programmes additionnels. Ce sont les plug-in.
Le plug-in est un programme indépendant que l’on peut lancer depuis une page HTML, et qui fonctionne à l’intérieur de la page. Par exemple, la page HTML peut contenir un film, ou bien une musique. Ce film ou cette musique ne sont pas codé sous forme HTML (langage totalement incapable de coder de la musique ou des images animées). La page HTML contient :
o le nom du fichier correspondant au film ou au morceau de musique
o le nom du programme (du plug-in) qui doit servir à interpréter le fichier. Si le plug-in n’est pas précisé, le navigateur peut le déterminer automatiquement en fonction de l’extension du fichier.
o quelques informations précisant la façon dont le plug-in s’insère dans la page HTML. Seul le nom du fichier est obligatoire. Si le plug-in n’est pas précisé, le navigateur peut le déterminer automatiquement en fonction de l’extension du fichier. Les informations précisant la façon dont le plug-in s’insère dans la page HTML dépendent de la nature de chaque fichier. Par exemple, pour un film, il faut préciser la dimension de l’écran dans lequel apparaîtra l’image. Ces informations sont inutiles pour un morceau de musique.
L’exemple le plus connu de plug-in est Flash. En affichage cartographique, on utilise aussi des plug-in pour interpréter le langage SVG. Nous aurons l’occasion de parler de ces deux plug-in dans d’autres cours. Mais de nombreux autres plug-in sont très utilisés : Mediaplayer, CosmoPlayer. La machine virtuelle Java joue aussi le rôle de plug-in.
3 Le web dynamique – l’architecture
Le Web que nous avons décrit jusqu’ici est purement statique : chaque adresse correspond à une page, et chaque page est un fichier qui s’affiche de manière univoque sur votre navigateur.
Avec le web dynamique, nous allons avoir des pages qui pour une même adresse peuvent prendre des formes différentes selon les actions de l’utilisateur.
Pour obtenir une page changeante, nous disposons de deux techniques :
- soit c’est le serveur qui construit une nouvelle page, qu’il envoie au client (scripts côté serveur)
- soit le client reçoit une page fixe, et il modifie cette page (scripts côté client)
Dans la pratique, nous verrons que les deux méthodes peuvent être utilisées sur la même page, mais comme elles reposent sur des techniques différentes, et qu’il ne faut pas les confondre, nous allons les décrire séparément.
3.1 script côté serveur – PHP
Sur le serveur, il est possible de faire tourner des programmes qui vont générer automatiquement du code HTML. PHP est l’un des langages de script côté serveur, et probablement le plus utilisé. Nous allons voir comment fonctionne ce langage.
Le code PHP est constitué de morceaux de script, inclus dans du code HTML. Lorsque le fichier PHP est interprété, les morceaux de scripts affichent les parties variables de la page. Le code HTML reste inchangé : il représente les parties fixes.
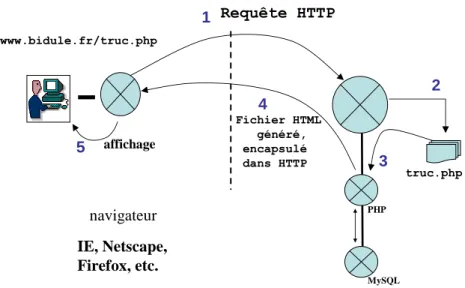
Requête HTTP Fichier HTML généré, encapsulé dans HTTP www.bidule.fr/truc.php navigateur IE, Netscape, Firefox, etc. affichage truc.php 1 2 4 5 3 PHP MySQL
figure 5. 1- Le serveur Apache reçoit la requête HTTP. 2-Il va chercher le fichier PHP correspondant. 3- il identifie que ce fichier est un fichier PHP, et il l’envoie au module qui interprète les scripts PHP. 4- le module d’interprétation génère du code HTML, qui est posté vers le client. 5- Le client affiche le code HTML comme si c’était une page normale.
Voici un exemple de code PHP :
<?php $nom="Victor Hugo" ; ?>
<p>Bonjour <?php echo $nom ; ?>, je suis heureux de vous voir </p>
Toutes les zones encadrées "<?php" et "?>" sont considérées comme du code PHP, et interprétées par le serveur. Ici, la première ligne est une affectation de variable. La deuxième
ligne effectue un affichage au moyen de l’instruction echo.
L’affichage se fait dans le code HTML,
à l’endroit où se trouve l’instruction echo.
Au final, l’interpréteur PHP produit le code HTML suivant :
<p>Bonjour Victor Hugo, je suis heureux de vous voir </p>
C’est ce code HTML que le client va recevoir.
Tel qu’il est présenté ici, le code PHP n’est pas très intéressant, car la variable $nom est équivalente à une constante. Mais les variables PHP jouent réellement le rôle de variables lorsque leur valeur est déterminée ailleurs que dans la page PHP : les scripts peuvent recevoir des variables depuis un formulaire HTML, ou bien encore ils peuvent aller les chercher dans une base de données.
Pour en savoir plus, vous pouvez commencer à lire « premier pas en PHP ».
Il existe d’autres langages qui permettent de construire des applications web dynamiques. Le concurrent direct de PHP est ASP, le produit de Microsoft. On peut citer aussi Python et Perl.
3.2 Accès aux bases de données
Sur la figure 5, PHP était branché sur MySQL. MySQL est un SGBD (Système de Gestion de Base de Données), c’est-à-dire un programme qui assure la cohérence, le stockage et l’interrogation des données dans une base de données.
Toutes les données importantes d’un site web doivent être stockées dans une base de données.
Parmi les nombreux SGBD du marché, il faut en connaître quelques uns de nom :
o Oracle est le SGBD historique. C’est la solution la plus robuste, la solution commerciale la plus utilisée. C’est aussi la plus chère.
o MySQL est un SGBD relativement simple, gratuit et très populaire. Il est recommandé pour les prototypes et pour les applications simples. Le logiciel SPIP, par exemple, utilise mySQL.
o PostGreSQL est un peu plus compliqué que MySQL. Il est gratuit lui aussi. Il comporte un module spatial (la cartouche spatiale) qui permet de manipuler de l’information géographique. Le module spatial de PostGreSQL se nomme PostGIS.
Dans ces SGBD, les données sont rangées dans des tables (ce sont en réalité comme des tableaux de données). Dans ces trois SGBD, on manipule les données et les tables au moyen d’un langage appelé SQL.
Dans le cadre de ce cours, nous utiliserons MySQL et PostGreSQL.
3.3 Scripts coté client : javascript
Javascript est un langage de script qui permet de modifier une page HTML et de la rendre plus interactive.
Par exemple :
- sur le site de la SNCF, lorsque je clique sur le bouton de date, j’affiche un mini calendrier qui me permet de choisir une date en cliquant dessus.
- Sur certains sites « folkloriques », lorsque je bouge la souris, le curseur est suivi d’une queue de comète.
- Sur certaines pages, je peux cliquer sur un bouton « fermer la fenêtre » (et la fenêtre alors se ferme).
- Sur certains sites, les étiquettes de survol peuvent être très décoratives, comme sur
cette page : http://www.bosrup.com/web/overlib/?Features
Toutes ces actions sont obtenues au moyen de javascript.
Les effets obtenus avec Javascript peuvent aussi bien être codés dans un plug-in comme Flash. Néanmoins, il vaut mieux réserver Flash pour le dessin et les animations vectorielles. Pour manipuler la mise en page, les formulaires, les zones d’affichage, les styles, etc., on préfèrera généralement Javascript : directement branché sur la page HTML, il permet de manipuler facilement les différents éléments de la page.
L’utilisation des plug-in présente en effet plusieurs inconvénients : - le plug-in n’est pas toujours installé sur toutes les machines
- l’interaction entre le plug-in et le reste de la page internet n’est pas toujours facile à assurer.
- Pour le développeur, le code javascript est tellement répandu qu’un grand nombre de ressources sont disponibles sur Internet.
Exercice 2 :
a. aller sur le site de réservation en ligne de la SNCF (http://www.voyages-sncf.com) pour tester le calendrier.
b. quelle est la date maximale qu’on peut atteindre sur ce calendrier ?
Pour en savoir plus, vous pouvez commencer à lire « premier pas en javascript ».
3.4 quelle utilisation ?
Pourquoi est-il intéressant d’avoir des scripts à la fois sur le serveur et sur le client ?
o Les scripts du côté client doivent servir aux opérations qui concernent directement l’interaction avec l’usager. Il est intéressant par exemple de faire exécuter sur le client les opérations de vérification des champs d’un formulaire : il est inutile de faire de multiples tentatives de soumission d’un formulaire si l’usager n’a pas rempli tous les champs d’un formulaire, et ne les a pas remplis de manière correcte. Dans ce cas, un script sur le client peut faire la vérification que les valeurs entrées dans le formulaire sont correctes.
o Les scripts du côté serveur doivent servir aux opérations lourdes, qui consomment des données. Une opération qui utilise des informations présentes dans une base de données doit être placé sur le serveur. De même, une opération qui manipule des données ou des algorithmes sensibles ne doivent pas aller sur le client : elle doit donc être traitée sur le serveur.
Il n’y a pas de règles absolues pour faire le partage entre ce qui doit tourner sur le client et ce qui doit tourner sur le serveur. Certaines opérations pourront être gérées des deux côtés. Ainsi, pour la vérification d’un formulaire, outre la première vérification sur le client, pour une meilleure fluidité et une économie de bande passante, il est recommandé d’en mettre en place une deuxième sur le serveur, pour assurer la sécurité des données.
3.5 Javascript est-il universel ?
De nombreux cours internet affirment qu'un bon site web doit prévoir une navigation sans javascript. Il est évident que l'utilisation de javascript rend un site un peu moins accessible, en particulier aux déficients visuels qui utilisent des clients spécialisés, ainsi qu'à certains clients mobiles.
Pour un site cartographique, néanmoins, sauf à passer par un plug-in, il est très difficile de se passer de javascript, qui assure des fonctions importantes de navigation. La navigation sans javascript est possible (c'est celle que l'on utilise dans certains TP dans les cours de Web Mapping) mais elle n’est pas très ergonomique.
3.6 Les cookies
Exercice 3 :
a. Allez sur le site « de Particulier à Particulier ».
b. consulter les annonces (par exemple : clic sur location, puis recherche un studio dans le 75)
c. mettez une ou deux annonces dans votre panier d. regardez le contenu de votre panier
e. fermer votre navigateur, puis relancer sur le même site. f. relancer une consultation d’annonces
g. vérifier que votre panier est toujours disponible
Avec cette manipulation très simple, vous voyez que sans jamais avoir entré votre nom ni vos coordonnées, l’ordinateur vous a identifié, et est capable de retrouver vos informations personnelles.
Comment cela est-il possible ?
En réalité, ce n’est pas vous qui êtes reconnu par le serveur, c’est votre navigateur.
Lors de la première communication en HTTP, le serveur envoie au client une variable que le navigateur va :
- stocker un certain temps (fixé par le serveur)
Cette variable véhiculée par HTTP s’appelle un cookie.
La durée de validité du cookie est fixée par le serveur. Le cookie peut rester valable pour un temps donné, ou bien il peut être effacé à la fin de la session.
Exercice 4 :
a. effacer les cookies du site du Particulier (chercher la méthode sur internet).
b. recommencer une consultation des annonces : votre panier maintenant doit être vide. c. Trouver sur la machine le fichier contenant le cookie correspondant au site du
Particulier.
d. Quels sont les noms et les valeurs des variables, et la durée de validité des cookies placés sur votre machine par le site pap.fr ?
Aide :
- Consulter l’article Wikipedia sur les cookies
http://fr.wikipedia.org/wiki/Cookie_%28informatique%29
- Sur vos disques durs locaux, chercher les fichiers contenant le mot "pap.fr".
Le mécanisme des cookies est à la base d’une fonctionnalité de PHP qui s’appelle les sessions. Une session est un cookie spécial qui permet à PHP d’identifier et de suivre un navigateur entre le moment où il commence à naviguer sur un site et le moment où il quitte le site. Le serveur lit la variable de session comme il lit un cookie. Son écriture seule est plus simple.
4 Le Web 2.0
Il est d’usage aujourd’hui de parler de web 2ème génération, sous le vocable de Web 2.0.
Au-delà de l’effet de mode, il existe plusieurs technologies qui permettent d’offrir au client des fonctionnalités et un confort de navigation inaccessibles aux technologies du web traditionnel. Le confort de navigation est principalement assuré par AJAX. Les nouvelles fonctionnalités sont distribuées sous la forme de web services et d’API client.
4.1 AJAX
Vous consultez une carte au milieu d’une page, avec un menu à gauche, la légende à droite, et les outils de navigation au-dessus. Sur une page web classique, lorsque vous cliquez dans la légende pour ajouter une couche sur votre carte, c’est la totalité de votre page qui est rechargée sur le serveur. Ici, avec AJAX, seule la carte va changer.
Vous utilisez Gmail : vous cliquez sur un message, le contenu du message s’affiche sans que le reste de la page ait changé. Là encore, Gmail utilise AJAX pour obtenir ce résultat.
AJAX est une méthode qui permet à Javascript d’interroger le serveur pour modifier certaines zones de la page sans avoir à tout recharger. Cela assure une navigation dynamique plus fluide.
Pour bien comprendre le gain obtenu grâce à AJAX, examinons pour commencer le déroulement d’une navigation sur internet en mode hyper-texte archaïque :
Page 1
Clic sur le zoom
+ -[ ] requête HTTP Interface utilisateur navigateur serveur requête HTTP Page morte Page 2 + -[ ] Effet blink affichage + initialisation affichage + ré-initialisation délai inévitable et peu gênant délai inutile et plus gênant requête URL html g é n é ra tio n d u c o n te n u re -g é n é ra tio n d u c o n te n u gaspillage de bande passante gaspillage ressource serveur + fichiers associés (img, scripts, css) html + fichiers associés
!
!
!
!
!
+ moteur javascriptToute action sur la carte provoque un rechargement et une réinitialisation de la page. A chaque fois qu’on fait une action, le navigateur recharge la page. Pour le navigateur, les versions 1 et 2 de la page sont indépendantes. Une partie des fichiers sont certes stockées en cache, mais pas tous, et tout le travail d’initialisation (instanciation des variables, calcul d’affichage) doit être refait à chaque fois : lors du rechargement, l’état de la page est perdu et doit être rechargé et recalculé.
De droite à gauche, on note les désavantages de cette architecture : - le serveur doit regénérer tout le contenu de la page
- le réseau doit transporter tout le contenu (même si une bonne politique de cache permet de diminuer le volume transporté)
- la ré-initialisation de la page bloque le client quelques instants (très courts, mais perceptibles, même en haut débit)
- auparavant, la page a subi un saut (effet blink) visuellement fatigant pour l’utilisateur - si l’utilisateur a demandé trois mouvements vers la droit, le serveur va en offrir un
nombre aléatoire entre un et trois.
Avec AJAX, la gestion de la navigation est retirée au navigateur, pour être confiée à son moteur javascript : c’est lui qui va lancer les requêtes, en interpréter le résultat, et modifier sur la page les seuls zones qui en ont besoin. La page n’est pas rechargée en bloc.
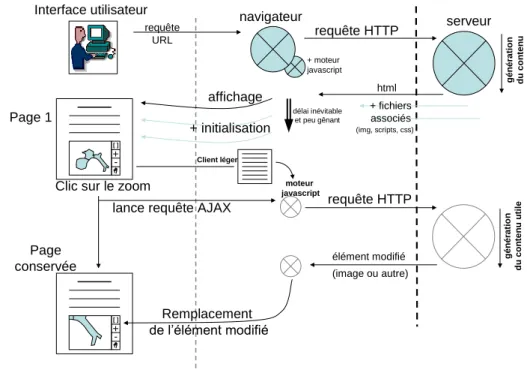
Page 1
Clic sur le zoom
+ -[ ] requête HTTP Interface utilisateur navigateur serveur requête HTTP Page conservée + -[ ] affichage + initialisation Remplacement de l’élément modifié délai inévitable et peu gênant requête URL html g é n é ra tio n d u c o n te n u g é n é ra tio n d u c o n te n u u til e + fichiers associés (img, scripts, css) élément modifié + moteur javascript moteur javascript Client léger (image ou autre)
lance requête AJAX
figure 7 – principe du client léger : après une phase d’initialisation, les manipulations de l’utilisateur ne provoque pas le rechargement complet de la page. Le client léger, programme tournant en javacript, envoie au serveur les requêtes permettant de mettre à jour la page, en ne modifiant que les zones qui doivent changer.
Si vous avez fait les TP d’initiation à javascript et PHP, vous pouvez vous lancer dans « premier pas avec AJAX ».
4.2 Les Web Services.
Un Web Service, c’est une page dynamique qui n’est pas faite pour être affichée directement, mais qui est conçue pour être intégrée dans d’autres pages web dynamiques.
Le navigateur appelle une page dynamique, sur un serveur, et ce serveur va lui-même chercher de l’information dans une autre page web dynamique. Le premier serveur joue donc le rôle du client par rapport au second serveur.
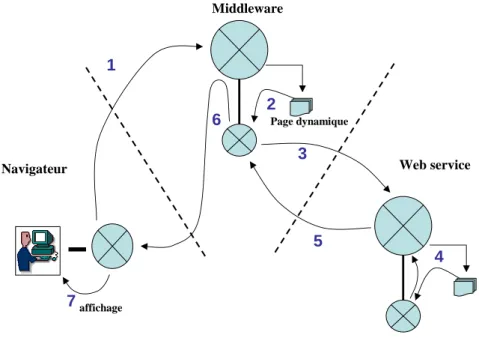
Cette architecture porte le nom d’architecture 3-tiers, et le serveur intermédiaire est souvent appelé middleware. affichage 1 3 7 2 4 5 6 Navigateur Page dynamique Web service Middleware
figure 8 – architecture 3-tiers utilisant un web service : 1- le navigateur appelle une page dynamique. 2- le serveur lance le calcul de la page dynamique. 3- La page dynamique utilise un web service : le serveur appelle le web service. 4- Le web service est lui-même une page qui dynamique : cette page dynamique est calculée. 5- le résultat du Web service est envoyé à l’appelant. 6- le serveur finit de produire la page dynamique, et la poste au Navigateur, qui 7- l’affiche.
Dans la pratique, un web service, c’est un serveur web qui fait une partie du travail à votre place. Par exemple : vous voulez afficher un plan dynamique sur votre site, mais vous n’avez pas les données pour faire le fond de carte, et vous n’avez pas envie de dépenser votre argent pour acheter ces données, ni de perdre votre temps à programmer ce fond de carte. Ou bien encore : vous n’avez pas le droit d'installer un serveur cartographique sur votre machine serveur.
Plutôt que de calculer un fond de carte dynamique, vous allez chercher un fond de carte directement sur Internet. Comme vous voulez que votre plan soit dynamique, il faut que votre fond de carte soit dynamique aussi : à chaque fois que votre page dynamique est calculée, elle va chercher le fond de carte dont elle a besoin sur une autre page dynamique.
Pour assurer la discussion entre les deux serveurs (le web service et le middleware), il faut structurer l’information pour lui donner une forme standard. On utilise pour cela un protocole qui encapsule HTTP. L’un de ces protocoles le plus utilisé s’appelle SOAP (Service Oriented Architecture Protocol), mais d’autres formats de web services sont possibles, par exemple WMS pour les services cartographiques.
4.3 Les API javascript
Une API javascript est une bibliothèque de fonctions javascript que vous pouvez utiliser pour obtenir rapidement des effets intéressants sur votre page web. Ce sont des aides à la programmation de pages web.
Certaines sont très simples à utiliser, s’intégrant facilement dans un site web pour lui offrir des fonctionnalités nouvelles. D’autres constituent des boite à outils pour faciliter les tâches du programmeur.
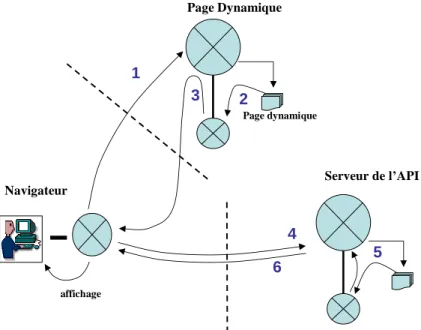
Parmi les API les plus populaires aujourd’hui figurent les API cartographiques, dont Google Map est la plus connue, mais qui comptent aussi Yahoo Map et MSN Virtual Earth. Elles présentent une architecture spécifique :
affichage 1 3 2 5 4 Navigateur Page dynamique Serveur de l’API Page Dynamique 6
figure 9 – architecture d’une application utilisant une API cartographique. 1 à 3 décrivent l’interrogation de la page dynamique. 4 à 6 décrivent l’interogation du serveur cartographique. Le résultat des deux requêtes est fusionné sur le navigateur, par javascript.
Attention, d’une part toutes les API ne sont pas des API cartographiques, d’autre part toutes les API n’ont pas besoin de faire des accès réseau : l’architecture présentée ici correspond à celle des API cartographiques, et en générale de toutes celles qui utilisent un serveur.
Le code javascript qui permet d’interroger le serveur de l’API fonctionne avec AJAX. Pour des raisons de sécurité, ce code ne peut pas se trouver sur la page dynamique. Il se trouve obligatoirement sur le serveur de l’API. Pour en savoir plus, consultez l’article « Same Origin Policy » de Wikipedia.
5 Conclusion
De ce document, vous devez avoir retenu au minimum les points suivants :
HTML est un langage de structuration et de mise en page de documents
hyper textes.
PHP est un langage de script côté serveur qui permet de générer des pages
dynamiques en HTML.
CSS est un langage de définition de style.
Javascript est un langage de script côté client.
MySQL et PostGreSQL sont des SGBD accessibles depuis PHP selon une
syntaxe SQL. Ils permettent de stocker des données de manière fiable et structurée.
Pour faire un site web dynamique et interactif, nous allons utiliser tous ces
6 Sommaire
1 Préambules ... 2
1.1 Objectifs du cours ... 2
1.2 Organisation ... 2
1.3 Comment utiliser ce cours ... 2
1.4 Prérequis du cours ... 3 2 Le Web Statique ... 4 2.1 l’architecture client-serveur ... 4 2.1.1 clients et serveurs ... 4 2.1.2 application à Internet ... 5 2.2 les protocoles ... 5
2.2.1 Qu’est-ce qu’un protocole ? ... 5
2.2.2 Les protocoles d’Internet ... 6
2.2.2.1 TCP/IP ... 6
2.2.2.2 HTTP – le protocole du web ... 6
2.3 le serveur ... 6
2.3.1 le serveur, un serveur de fichiers ... 6
2.3.2 le répertoire racine ... 7
2.3.3 affichage des dossiers ... 8
2.3.4 Les erreurs ... 8
2.3.5 Conclusion ... 9
2.4 le client ... 9
2.4.1 le langage HTML ... 9
2.4.2 CSS et feuilles de style ... 10
2.4.3 l’inclusion d’une image ... 10
2.4.4 - les plug-in ... 11
3 Le web dynamique – l’architecture ... 13
3.1 script côté serveur – PHP ... 13
3.2 Accès aux base de données ... 14
3.3 Scripts coté client : javascript ... 15
3.4 quelle utilisation ? ... 15
3.5 Javascript est-il universel ?... 16
3.6 Les cookies ... 16
4 Le Web 2.0 ... 18
4.1 AJAX ... 18
4.2 Les Web Services. ... 20
4.3 Les API javascript ... 21
5 Conclusion ... 22