Automates Cellulaires : Aspects algorithmiques des configurations périodiques en toute dimension
Texte intégral
Figure
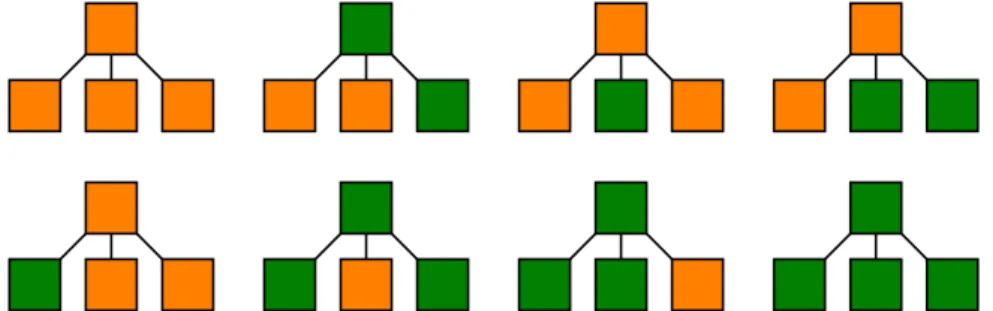
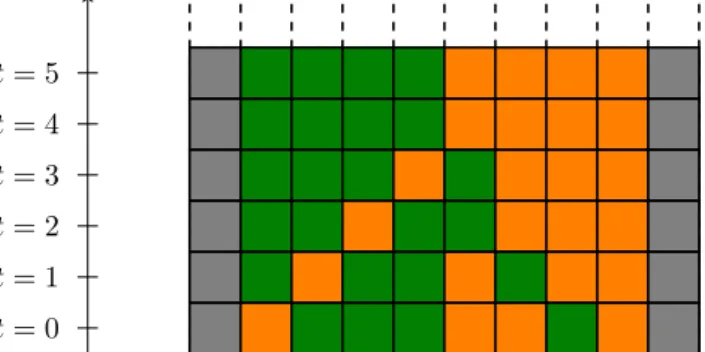
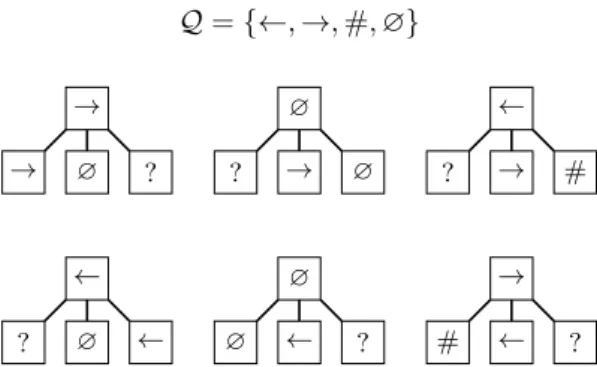
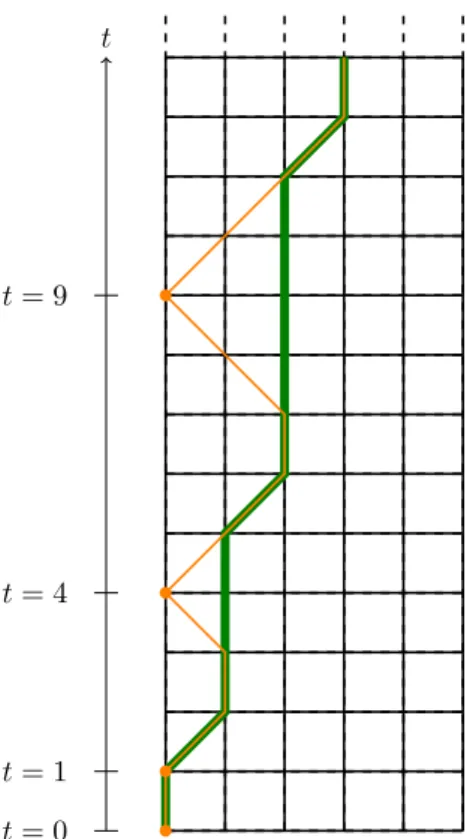


Outline
Documents relatifs
[r]
- Ceci s’explique par le fait que Rob, R’ouina, vinaigre et la pâte de datte sont ancestralement fabriqués au niveau des ménages et élargis à des
the above problems on the one hand and on the other one from a an interest in teaching reading strategies in ESP context. The introduction of the teaching of language learning
Development and use of molecular markers for characterisation of Forest Genetic Resources and for Breeding : a case study, Black poplar (Populus nigra L.).. Advanced Studies
L’étiquetage apposé sur l’emballage de la Plate de Florenville comporte, outre les mentions légales (le numéro d’agréation du préparateur / emballeur, la mention « pomme
Pour analyser la capacité des formulations à induire une expression de l’ARNm vectorisé en présence de sérum, deux lignées cellulaires épithéliales (HEK293 et HeLa)
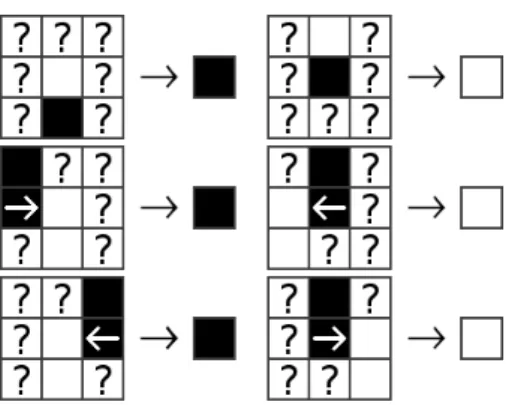
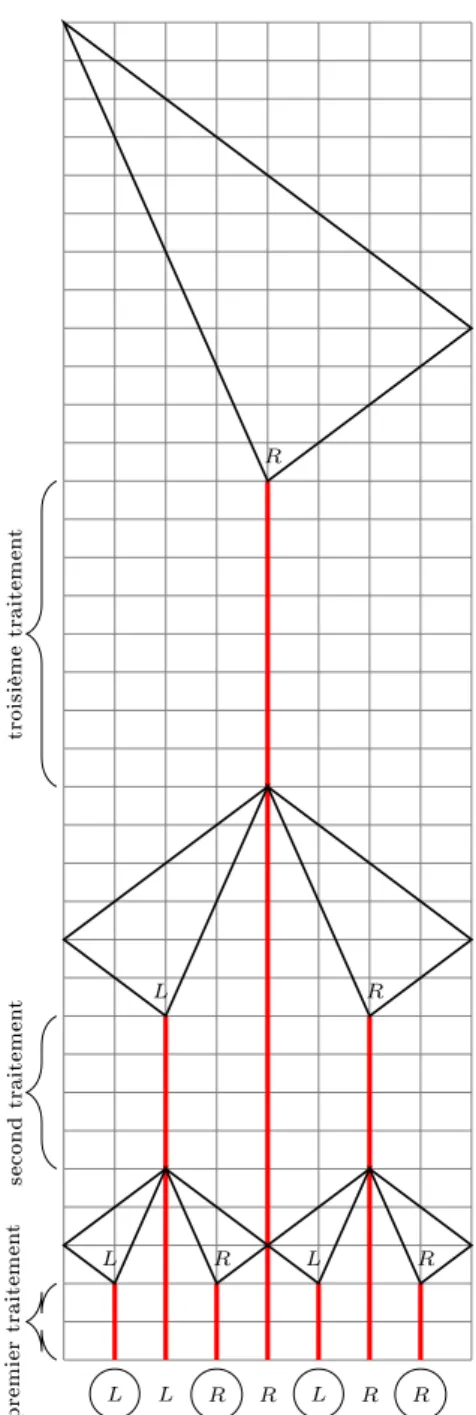
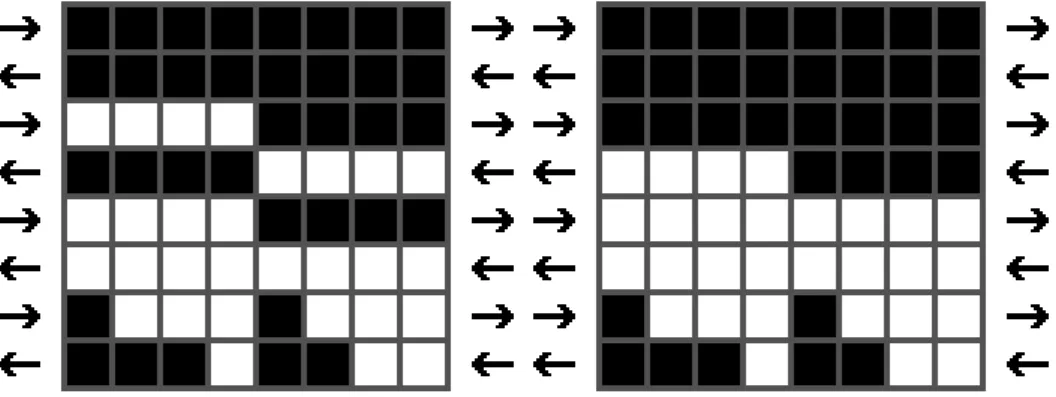
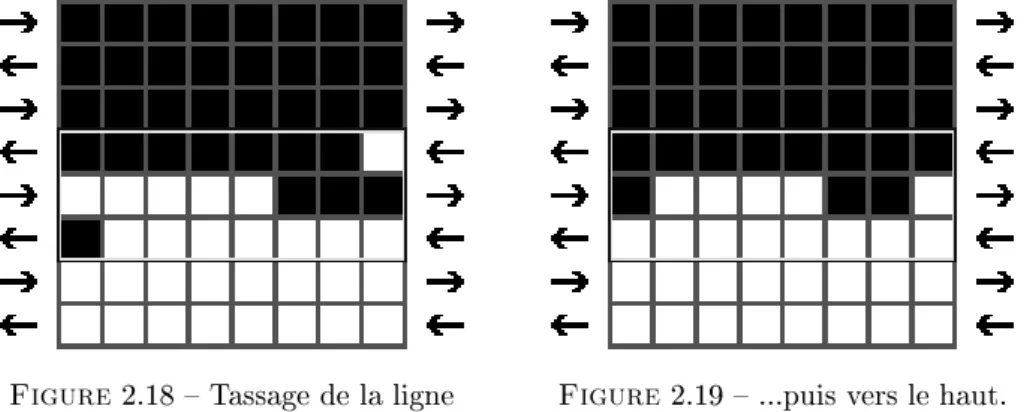
Dans cette étude, la non-préexistence de rotation ayant des propriétés intéressantes pour la modélisation sur automates cellulaires nous a contraints dans un premier temps à
